本文主要是介绍数据分析案例-中国黄金股票市场的EDA与价格预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
6.建模预测
源代码
1.项目背景
在金融市场中,黄金一直被视为避险资产和价值储存工具。中国的黄金市场在全球范围内具有举足轻重的地位。随着中国经济实力的增强和金融市场的逐步开放,国内黄金市场的规模和影响力不断扩大。在此背景下,对于中国黄金市场的深度分析和预测,对于投资者、政策制定者和学术研究者都具有重要意义。
一、研究背景
近年来,受全球经济形势不确定性增加、金融市场波动加剧的影响,黄金作为避险资产的需求持续上升。中国作为全球第二大经济体,其黄金市场的动态和趋势备受关注。因此,对中国黄金市场的有效分析和预测,对于理解全球黄金市场的动态、制定投资策略和政策具有重要意义。
二、技术进步的推动
随着大数据、人工智能等技术的快速发展,数据驱动的定量分析方法在金融领域的应用越来越广泛。这为深入研究中国黄金市场提供了新的工具和视角。利用先进的数据分析技术,我们可以更准确地挖掘市场数据中的隐藏信息,更有效地预测市场趋势。
三、政策与市场环境
中国政府近年来对于金融市场的开放和黄金市场的规范化发展给予了高度重视。一系列的政策措施推动了黄金市场的健康发展。同时,国内外经济环境、货币政策、地缘政治等因素,都对黄金市场产生了深远影响。对这些因素的深入分析和理解,是进行黄金市场预测的重要基础。
四、学术研究的需要
学术界对于中国黄金市场的关注也在持续升温。对于中国黄金市场的深入研究,不仅可以丰富和发展金融市场的理论体系,还可以为投资者提供更有价值的决策依据。通过科学的实证研究和模型构建,可以更准确地把握市场动态,更有效地预测市场趋势。
2.数据集介绍
本数据集来源于Kaggle,原始数据集为2015-2022年中国黄金股票价格,共有1945条,11个变量,各变量含义如下:
ts_code- 交易市场代码
trade_date- 交易日期
close- 开盘价
open- 收盘价
high- 最高价格
low- 最低价格
pre_close- 最后交易日收盘价
change- 变化点
pct_chg- 变化的百分比
vol- 交易量
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入第三方库并加载数据集
import numpy as np
import pandas as pd
import seaborn as sns
from datetime import datetime
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score,confusion_matrix
from xgboost import XGBRegressor
import time
import plotly.io as pio
import plotly.graph_objects as go
import plotly.offline as pyo
# 初始化plotly
pyo.init_notebook_mode()df = pd.read_csv('Gold-Au99_95.csv')
df.head()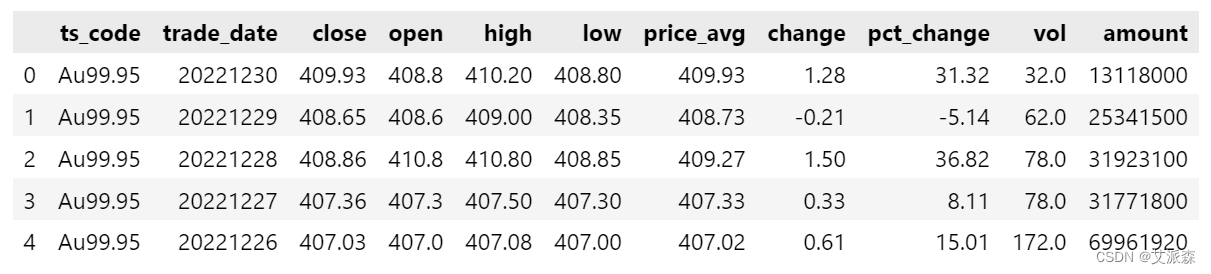
查看数据大小

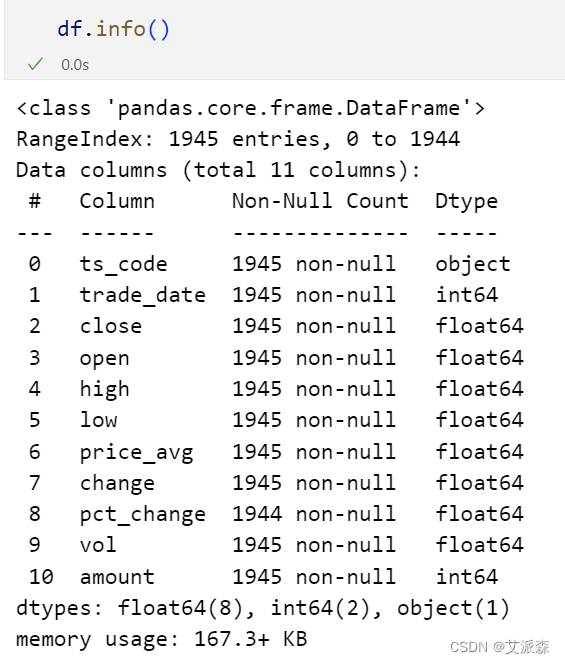
查看数据基本信息
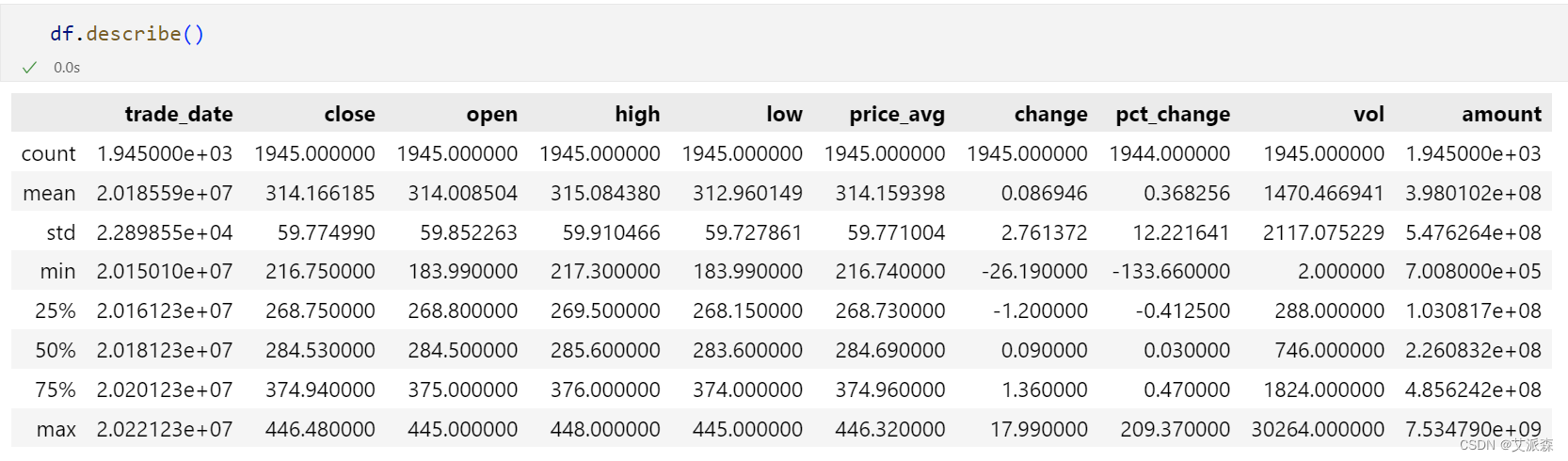
查看描述性统计
数据预处理
# 转化日期数据类型
df['trade_date'] = pd.to_datetime(df['trade_date'].astype(str), format='%Y%m%d')
df.sort_values(by="trade_date",inplace=True) # 按日期重新排序
df.drop('ts_code',axis=1,inplace=True) # 删除ts_code列
df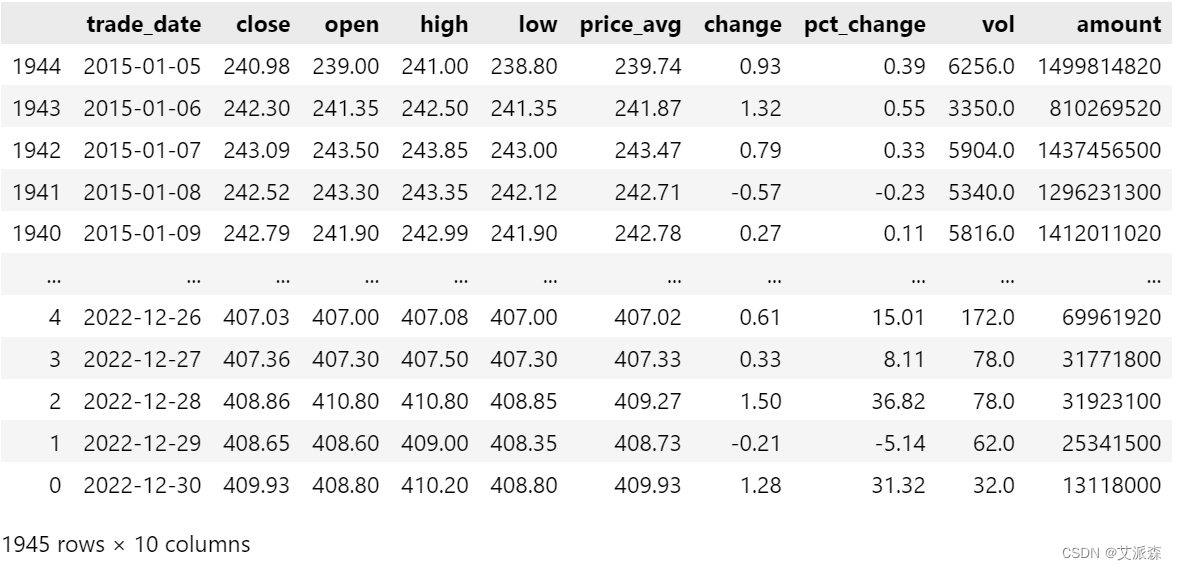
5.数据可视化
figure(figsize=(12, 4),dpi=80)
sns.lineplot(data=df,x='trade_date',y='close')
plt.show()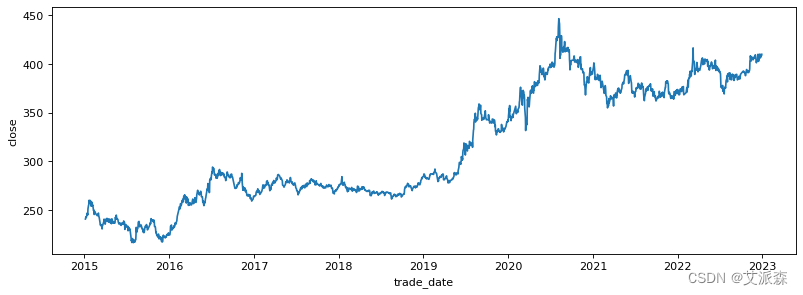
a = df[df['vol']<6000]
figure(figsize=(16, 4), dpi=80)
sns.regplot(data=a,x='price_avg',y='vol')
plt.show()
figure(figsize=(12, 4), dpi=80)
sns.lineplot(data=df,x='trade_date',y='amount')
plt.show()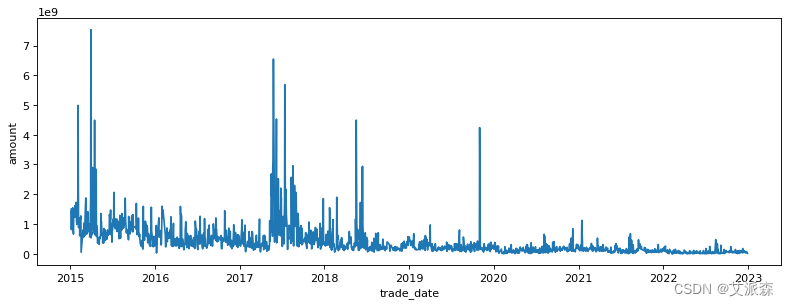
figure(figsize=(12, 4), dpi=80)
sns.boxplot(data=df,x='pct_change')
plt.show()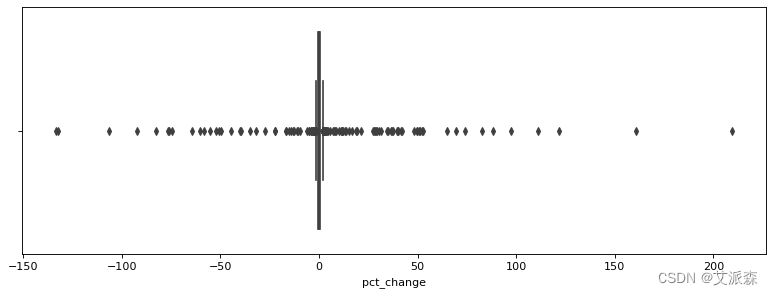
a = df[(df['pct_change']>-10) &(df['pct_change']<10)]
figure(figsize=(12, 4), dpi=80)
sns.boxplot(data=a,x='pct_change')
plt.show()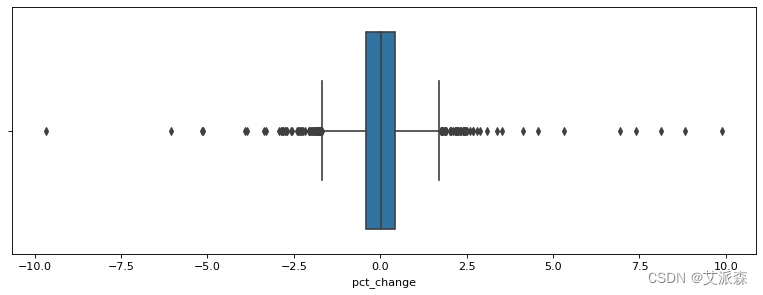
figure(figsize=(12, 4), dpi=80)
sns.histplot(data=a,x='pct_change',kde=True)
plt.show()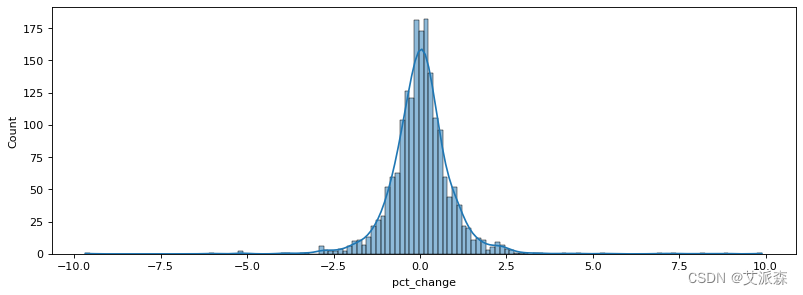
pio.renderers.default = 'iframe'
lags = [1, 2, 3]
def lag_features(df, lags):c = df.copy()for lag in lags:value1 = c['pct_change'].transform(lambda x: x.shift(lag))value2 = c['vol'].transform(lambda x: x.shift(lag))c['return_lag_' + str(lag)] = value1c['vol_lag_' + str(lag)] = value2return ca= lag_features(a, lags)
a['vol_incremental'] = a['vol_lag_1'] -a['vol_lag_2']
a['label'] = a['pct_change'].apply(lambda x:0 if x<=0 else 1)df['EMA_9'] = df['close'].ewm(9).mean().shift()
df['SMA_5'] = df['close'].rolling(5).mean().shift()
df['SMA_10'] = df['close'].rolling(10).mean().shift()
df['SMA_15'] = df['close'].rolling(15).mean().shift()
df['SMA_30'] = df['close'].rolling(30).mean().shift()t1 = go.Scatter(x=df.trade_date, y=df.EMA_9, name='EMA 9')
t2 = go.Scatter(x=df.trade_date, y=df.SMA_5, name='SMA 5')
t3 = go.Scatter(x=df.trade_date, y=df.SMA_10, name='SMA 10')
t4 = go.Scatter(x=df.trade_date, y=df.SMA_15, name='SMA 15')
t5 = go.Scatter(x=df.trade_date, y=df.SMA_30, name='SMA 30')
t6 = go.Scatter(x=df.trade_date, y=df.close, name='close', opacity=0.2)
data = [t1,t2,t3,t4,t5,t6]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')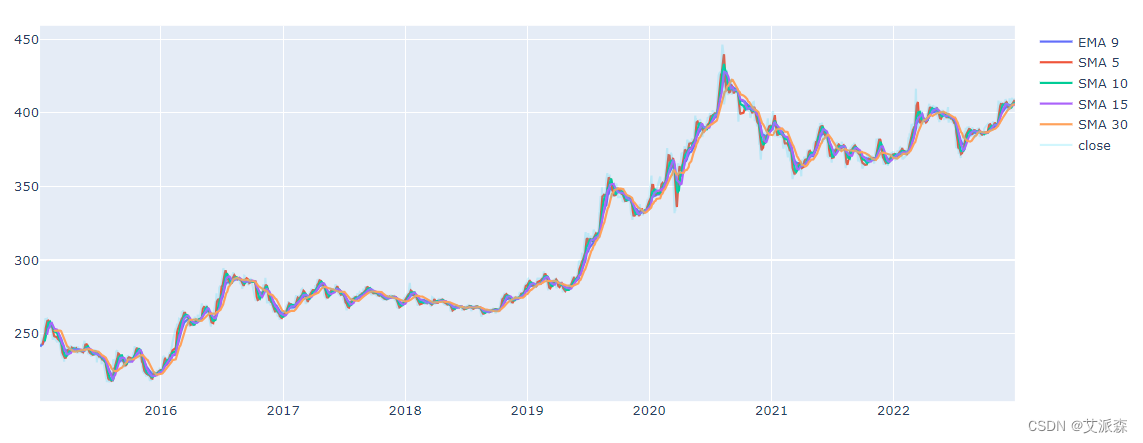
def relative_strength_idx(df, n=14):close = df['close']delta = close.diff()delta = delta[1:]pricesUp = delta.copy()pricesDown = delta.copy()pricesUp[pricesUp < 0] = 0pricesDown[pricesDown > 0] = 0rollUp = pricesUp.rolling(n).mean()rollDown = pricesDown.abs().rolling(n).mean()rs = rollUp / rollDownrsi = 100.0 - (100.0 / (1.0 + rs))return rsidf['RSI'] = relative_strength_idx(df).fillna(0)t1 = go.Scatter(x=df.trade_date, y=df.RSI, name='RSI')
data = [t1]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')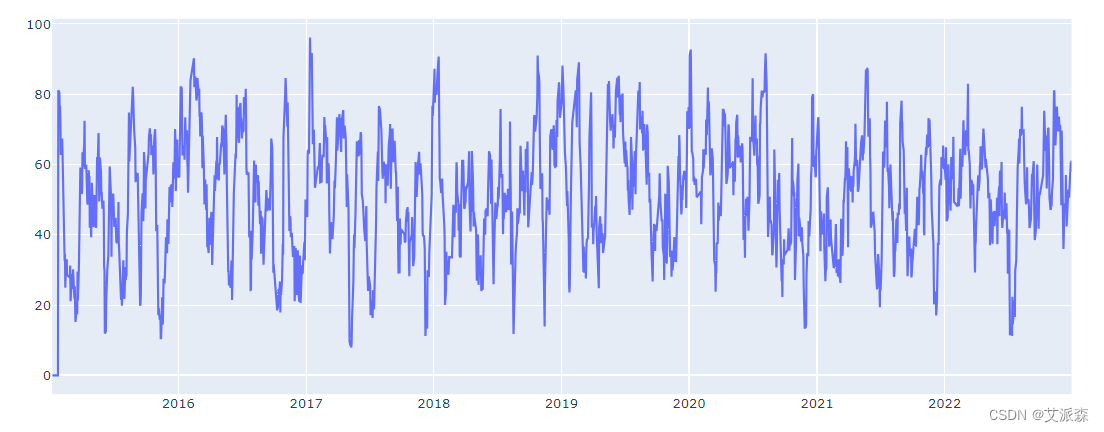
from plotly.subplots import make_subplotsEMA_12 = pd.Series(df['close'].ewm(span=12, min_periods=12).mean())
EMA_26 = pd.Series(df['close'].ewm(span=26, min_periods=26).mean())
df['MACD'] = pd.Series(EMA_12 - EMA_26)
df['MACD_signal'] = pd.Series(df.MACD.ewm(span=9, min_periods=9).mean())t1 = go.Scatter(x=df.trade_date, y=df.close, name='close')
t2 = go.Scatter(x=df.trade_date, y=EMA_12, name='EMA 12')
t3 = go.Scatter(x=df.trade_date, y=EMA_26, name='EMA 26')
t4 = go.Scatter(x=df.trade_date, y=df['MACD'], name='MACD')
t5 = go.Scatter(x=df.trade_date, y=df['MACD_signal'], name='Signal line')
data = [t1,t2,t3,t4,t5]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')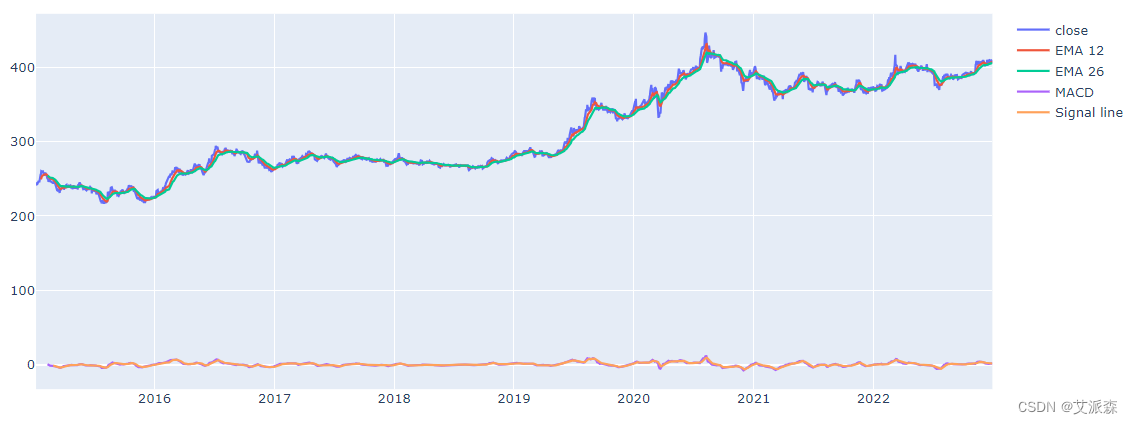
6.建模预测
df.dropna(how="any",inplace=True)
b = df.drop(['change', 'pct_change','amount','vol','high','open','low','price_avg'],axis=1)
# 这里的label表示下一个交易日的收盘价
b['label'] = b['close'].shift(-1)
b.dropna(how="any",inplace=True)拆分数据集,并使用网格搜索寻找 XGBRegressor模型的最优参数
y = b['label']
X = b.drop(columns=['label'],axis=1)train_set, valid_set= np.split(b, [int(.7 *len(b))])
y_train = train_set['label']
X_train = train_set.drop(columns=['label','trade_date'],axis=1)y_valid = valid_set['label']
X_valid = valid_set.drop(columns=['label','trade_date'],axis=1)grid = {'n_estimators': [100, 200, 300, 400],'learning_rate': [0.001, 0.005, 0.01, 0.05],'max_depth': [8, 10, 12, 15],'gamma': [0.001, 0.005, 0.01, 0.02],'random_state': [42]
}
clf = GridSearchCV(estimator=XGBRegressor(), param_grid=grid, n_jobs=-1, cv=None)
clf.fit(X_train, y_train)
scores=clf.score(X_valid, y_valid)
scores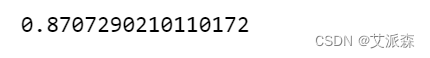
print(f'Best params: {clf.best_params_}')
print(f'Best validation score = {clf.best_score_}')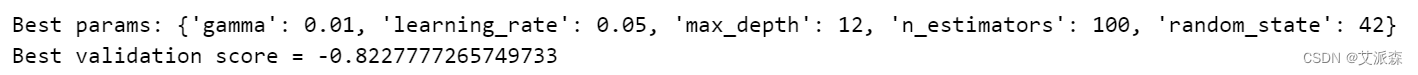
使用最佳参数重新训练模型
model = XGBRegressor(**clf.best_params_, objective='reg:squarederror')
model.fit(X_train, y_train)
pred = model.predict(X_valid)重要特征可视化
from xgboost import plot_importance
plot_importance(model) # 特征重要性可视化
plt.show() 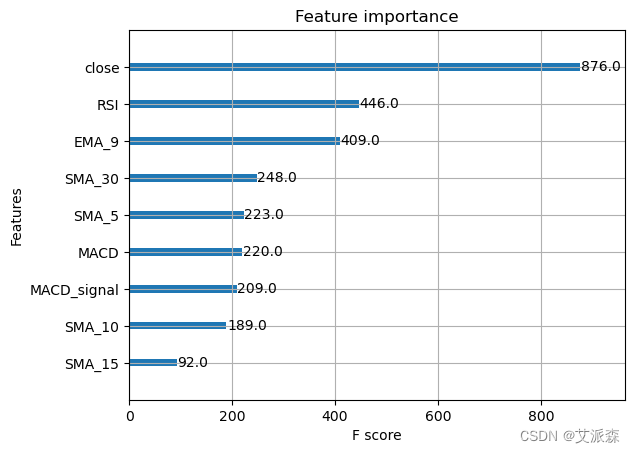
from sklearn.metrics import mean_squared_error
print(f'mean_squared_error = {mean_squared_error(y_valid, pred)}')![]()
i = len(pred)
predicted_prices = df.tail(i).copy()
predicted_prices['close'] = pred
t1 = go.Scatter(x=df.trade_date, y=df.close,name='Truth',marker_color='LightSkyBlue')t2 = go.Scatter(x=predicted_prices.trade_date,y=predicted_prices.close,name='Prediction',marker_color='MediumPurple')t3 = go.Scatter(x=predicted_prices.trade_date,y=y_valid,name='Truth',marker_color='LightSkyBlue',showlegend=False)t4 = go.Scatter(x=predicted_prices.trade_date,y=pred,name='Prediction',marker_color='MediumPurple',showlegend=False)
data = [t1,t2,t3,t4]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')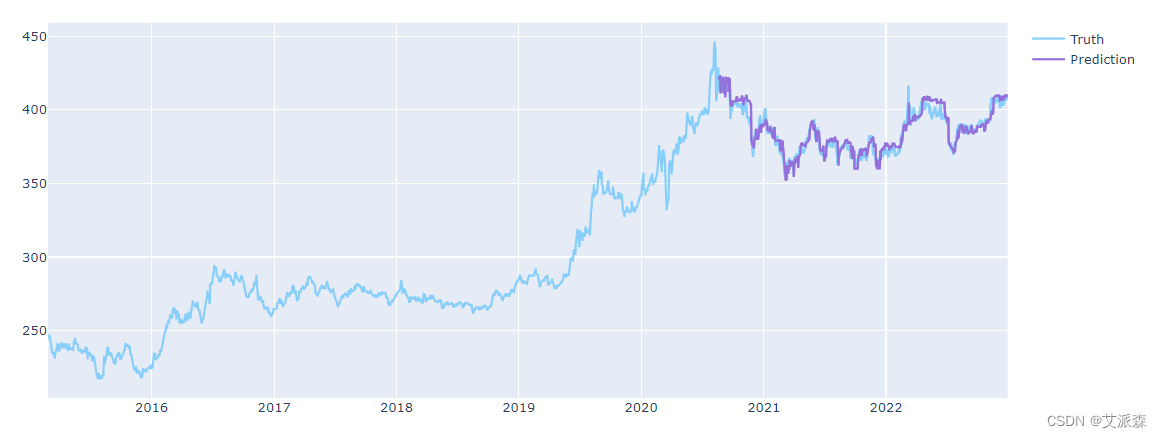
源代码
ts_code- 交易市场代码
trade_date- 交易日期
close- 开盘价
open- 收盘价
high- 最高价格
low- 最低价格
pre_close- 最后交易日收盘价
change- 变化点
pct_chg- 变化的百分比
vol- 交易量
import numpy as np
import pandas as pd
import seaborn as sns
from datetime import datetime
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score,confusion_matrix
from xgboost import XGBRegressor
import time
import plotly.io as pio
import plotly.graph_objects as go
import plotly.offline as pyo
# 初始化plotly
pyo.init_notebook_mode()df = pd.read_csv('Gold-Au99_95.csv')
df.head()
df.shape
df.info()
df.describe()
# 转化日期数据类型
df['trade_date'] = pd.to_datetime(df['trade_date'].astype(str), format='%Y%m%d')
df.sort_values(by="trade_date",inplace=True) # 按日期重新排序
df.drop('ts_code',axis=1,inplace=True) # 删除ts_code列
df
figure(figsize=(12, 4),dpi=80)
sns.lineplot(data=df,x='trade_date',y='close')
plt.show()
a = df[df['vol']<6000]
figure(figsize=(16, 4), dpi=80)
sns.regplot(data=a,x='price_avg',y='vol')
plt.show()
figure(figsize=(12, 4), dpi=80)
sns.lineplot(data=df,x='trade_date',y='amount')
plt.show()
figure(figsize=(12, 4), dpi=80)
sns.boxplot(data=df,x='pct_change')
plt.show()
a = df[(df['pct_change']>-10) &(df['pct_change']<10)]
figure(figsize=(12, 4), dpi=80)
sns.boxplot(data=a,x='pct_change')
plt.show()
figure(figsize=(12, 4), dpi=80)
sns.histplot(data=a,x='pct_change',kde=True)
plt.show()
pio.renderers.default = 'iframe'
lags = [1, 2, 3]
def lag_features(df, lags):c = df.copy()for lag in lags:value1 = c['pct_change'].transform(lambda x: x.shift(lag))value2 = c['vol'].transform(lambda x: x.shift(lag))c['return_lag_' + str(lag)] = value1c['vol_lag_' + str(lag)] = value2return ca= lag_features(a, lags)
a['vol_incremental'] = a['vol_lag_1'] -a['vol_lag_2']
a['label'] = a['pct_change'].apply(lambda x:0 if x<=0 else 1)df['EMA_9'] = df['close'].ewm(9).mean().shift()
df['SMA_5'] = df['close'].rolling(5).mean().shift()
df['SMA_10'] = df['close'].rolling(10).mean().shift()
df['SMA_15'] = df['close'].rolling(15).mean().shift()
df['SMA_30'] = df['close'].rolling(30).mean().shift()t1 = go.Scatter(x=df.trade_date, y=df.EMA_9, name='EMA 9')
t2 = go.Scatter(x=df.trade_date, y=df.SMA_5, name='SMA 5')
t3 = go.Scatter(x=df.trade_date, y=df.SMA_10, name='SMA 10')
t4 = go.Scatter(x=df.trade_date, y=df.SMA_15, name='SMA 15')
t5 = go.Scatter(x=df.trade_date, y=df.SMA_30, name='SMA 30')
t6 = go.Scatter(x=df.trade_date, y=df.close, name='close', opacity=0.2)
data = [t1,t2,t3,t4,t5,t6]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')
def relative_strength_idx(df, n=14):close = df['close']delta = close.diff()delta = delta[1:]pricesUp = delta.copy()pricesDown = delta.copy()pricesUp[pricesUp < 0] = 0pricesDown[pricesDown > 0] = 0rollUp = pricesUp.rolling(n).mean()rollDown = pricesDown.abs().rolling(n).mean()rs = rollUp / rollDownrsi = 100.0 - (100.0 / (1.0 + rs))return rsidf['RSI'] = relative_strength_idx(df).fillna(0)t1 = go.Scatter(x=df.trade_date, y=df.RSI, name='RSI')
data = [t1]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')
from plotly.subplots import make_subplotsEMA_12 = pd.Series(df['close'].ewm(span=12, min_periods=12).mean())
EMA_26 = pd.Series(df['close'].ewm(span=26, min_periods=26).mean())
df['MACD'] = pd.Series(EMA_12 - EMA_26)
df['MACD_signal'] = pd.Series(df.MACD.ewm(span=9, min_periods=9).mean())t1 = go.Scatter(x=df.trade_date, y=df.close, name='close')
t2 = go.Scatter(x=df.trade_date, y=EMA_12, name='EMA 12')
t3 = go.Scatter(x=df.trade_date, y=EMA_26, name='EMA 26')
t4 = go.Scatter(x=df.trade_date, y=df['MACD'], name='MACD')
t5 = go.Scatter(x=df.trade_date, y=df['MACD_signal'], name='Signal line')
data = [t1,t2,t3,t4,t5]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')
df.dropna(how="any",inplace=True)
b = df.drop(['change', 'pct_change','amount','vol','high','open','low','price_avg'],axis=1)
# 这里的label表示下一个交易日的收盘价
b['label'] = b['close'].shift(-1)
b.dropna(how="any",inplace=True)
y = b['label']
X = b.drop(columns=['label'],axis=1)train_set, valid_set= np.split(b, [int(.7 *len(b))])
y_train = train_set['label']
X_train = train_set.drop(columns=['label','trade_date'],axis=1)y_valid = valid_set['label']
X_valid = valid_set.drop(columns=['label','trade_date'],axis=1)grid = {'n_estimators': [100, 200, 300, 400],'learning_rate': [0.001, 0.005, 0.01, 0.05],'max_depth': [8, 10, 12, 15],'gamma': [0.001, 0.005, 0.01, 0.02],'random_state': [42]
}
clf = GridSearchCV(estimator=XGBRegressor(), param_grid=grid, n_jobs=-1, cv=None)
clf.fit(X_train, y_train)
scores=clf.score(X_valid, y_valid)
scores
print(f'Best params: {clf.best_params_}')
print(f'Best validation score = {clf.best_score_}')
model = XGBRegressor(**clf.best_params_, objective='reg:squarederror')
model.fit(X_train, y_train)
pred = model.predict(X_valid)
from xgboost import plot_importance
plot_importance(model) # 特征重要性可视化
plt.show()
from sklearn.metrics import mean_squared_error
print(f'mean_squared_error = {mean_squared_error(y_valid, pred)}')
i = len(pred)
predicted_prices = df.tail(i).copy()
predicted_prices['close'] = pred
t1 = go.Scatter(x=df.trade_date, y=df.close,name='Truth',marker_color='LightSkyBlue')t2 = go.Scatter(x=predicted_prices.trade_date,y=predicted_prices.close,name='Prediction',marker_color='MediumPurple')t3 = go.Scatter(x=predicted_prices.trade_date,y=y_valid,name='Truth',marker_color='LightSkyBlue',showlegend=False)t4 = go.Scatter(x=predicted_prices.trade_date,y=pred,name='Prediction',marker_color='MediumPurple',showlegend=False)
data = [t1,t2,t3,t4]
plt.close('all')
pyo.iplot(data, filename = 'basic-line')
资料获取,更多粉丝福利,关注下方公众号获取

这篇关于数据分析案例-中国黄金股票市场的EDA与价格预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





