本文主要是介绍FCN全卷积语义分割网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
参考FCN论文:Fully Convolutional Networks for Semantic Segmentation
FCN作为图像语义分割的先河,实现像素级别的分类(即end to end,pixel-wise),为后续使用CNN作为基础的图像语义分割模型提供重要基础。作者在阅读FCN论文时,遇到不少困难,同时FCN没有多少中文资料(更多是英语翻译),所以作者尽量用浅白的方式讲述FCN的原理与过程。
FCN中的CNN
首先回顾CNN测试图片类别的过程,如下图
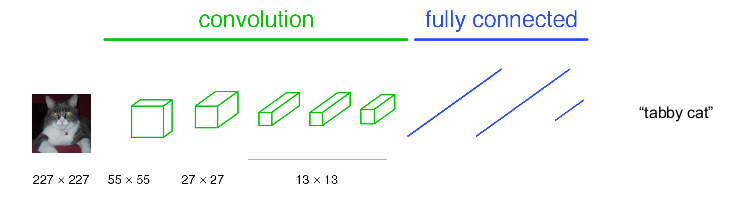
主要由卷积,pool与全连接构成,这里把卷积与pool都看作图中绿色的convolution,全连接为图中蓝色的fully connected。卷积主要是获取高维特征,pool使图片缩小一半,全连接与传统神经网络相似作为权值训练,最后通过softmax输出概率最高的类别。上图中nxn表示feature map(特征图)大小, 如原图大小为227x227,经过卷积与pool后得到55x55的特征图(一层的特征图可以有多个类别)。注意,不同的卷积操作可能会对图片大小产生影响,而pool永远使图片缩小1/2。–可以参考作者的卷积神经网络CNN(1)。经过多次卷积后特征图大小为13x13,特征图的权值展开为1维与后面的权值实现全连接,最后使用softmax输出类别。这就是CNN的大致网络结构与分类过程。
经过CNN改造的FCN如下图,
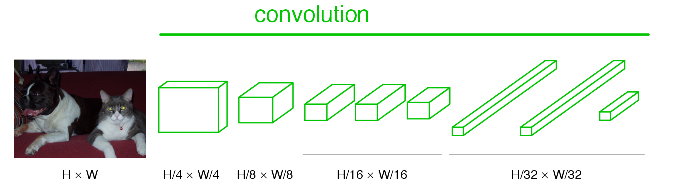
看可以看到蓝色的全连接层全部换成卷积层,对于CNN的过程就是做了这么简单直白的变换,全卷积的名字由此而来,这就是FCN。图中nxn是表示特征图的大小,可以看到最后特征图的大小为原图的1/32(这与FCN论文中解释upsample实现end to end 的32stride,16stride,8stride有莫大的关系)。
FCN的upsample
upsample意思为上采样,简单来说就是pooling的逆过程,所以pooling也就是下采样,采样后数据数量减少,upsample采样后数据数量增多。FCN作者在论文中讨论了3种upsample方法,最后选用的是反卷积的方法(FCN作者称其为后卷积)使图像实现end to end,可以理解upsample就是使大小比原图像小得多的特征图变大,使其大小为原图像大小。

下面解释FCN中是如何实现upsample,FCN作者分为FCN-32s,FCN-16s,FCN-8s三种,论文中有一个图是描述这个三个过程的,如下图,
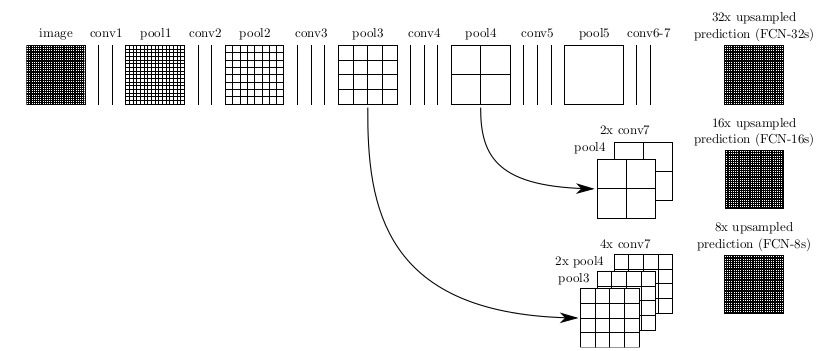
image是原图像,conv1,conv2..,conv5为卷积操作,pool1,pool2,..pool5为pool操作(pool就是使得图片变为原图的1/2),注意con6-7是最后的卷积层,最右边一列是upsample后的end to end结果。必须说明的是图中nx是指对应的特征图上采样n倍(即变大n倍),并不是指有n个特征图,如32x upsampled 中的32x是图像只变大32倍,不是有32个上采样图像,又如2x conv7是指conv7的特征图变大2倍。
第一行对应FCN-32s,第二行对应FCN-16s,第三行对应FCN-8s。
先从FCN-32s开始说明upsample过程,只需要留意第一行,网络里面有5个pool,所以conv7的特征图是原始图像1/32,可以发现最左边image的是32x32,同时我们知道在FCN中的卷积是不会改变图像大小(或者只有少量像素的减少,特征图大小基本不会小很多),看到pool1是16x16,pool2是8x8,pool3是4x4,pool4是2x2,pool5是1x1,所以conv7对应特征图大小为1x1,然后再经过32x upsampled prediction 图片变回32x32。FCN作者在这里增加一个卷积层,卷积后的大小为输入图像的32(2^5)倍,我们简单假设这个卷积核大小也为32,这样就是需要通过反馈训练32x32个权重变量即可让图像实现end to end,完成了一个32s的upsample,FCN作者称做后卷积,他也提及可以称为反卷积。事实上在源码中卷积核的大小为64,同时没有偏置bias。还有一点就是FCN论文中最后结果都是21x…,这里的21是指FCN使用的数据集分类,总共有21类。
现在我们把1,2两行一起看,忽略32x upsampled prediction,说明FCN-16s的upsample过程,,FCN作者在conv7先进行一个2x conv7操作,其实这里也只是增加1个卷积层,这次卷积后特征图的大小为conv7的2倍,可以从pool5与2x conv7中看出来,此时2x conv7与pool4的大小是一样的,FCN作者提出对pool4与2x conv7进行一个fuse操作(事实上就是将pool4与2x conv7相加),fuse结果进行16x upsampled prediction,与FCN-32s一样,也是增加一个卷积层,卷积后的大小为输入图像的16(2^4)倍,我们知道pool4的大小是2x2,放大16倍,就是32x32,这样最后图像大小也变为原来的大小,至此完成了一个16s的upsample。现在我们可以知道,FCN中的upsample实际是通过增加卷积层,通过bp反馈的训练方法训练卷积层达到end to end,这时卷积层的作用可以看作是pool的逆过程。
这是我们看第1行与第3行,忽略32x upsampled prediction,conv7经过一次4x upsample,即使用一个卷积层,特征图输出大小为conv7的4倍,所以4x conv7的大小为4x4,然后pool4需要一次2x upsample,变成2x pool4,大小也为4x4,最后吧4x conv7,2x pool4与pool3进行fuse,得到求和后的特征图,最后增加一个卷积层,使得输出图片大小为pool3的8倍,也就是8x upsampled prediction的过程,最后也得到一个end to end的图像。同时FCN-8s均优于FCN-16s,FCN-32s,这里的数量词都表示的是放大图像的倍数!越是后面的层就越需要放大的倍数更大!一般要是放大的倍数越大图像就越模糊,细节性就越差!
我们可以发现,如果继续仿照FCN作者的步骤,我们可以对pool2,pool1实现同样的方法,可以有FCN-4s,FCN-2s,最后得到end to end的输出。这里作者给出了明确的结论,超过FCN-8s之后,结果并不能继续优化。
Fina l l y
结合上述的FCN的全卷积与upsample,在upsample最后加上softmax,就可以对不同类别的大小概率进行估计,实现end to end,最后输出的图是一个概率估计,对应像素点的值越大,其像素为该类的结果也越大。FCN的核心贡献在于提出使用卷积层通过学习让图片实现end to end分类。事实上,FCN有一些短处,例如使用了较浅层的特征,因为fuse操作会加上较上层的pool特征值,导致高维特征不能很好得以使用,同时也因为使用较上层的pool特征值,导致FCN对图像大小变化有所要求,如果测试集的图像远大于或小于训练集的图像,FCN的效果就会变差。但是,也由于FCN提出了一种新的语义分割的方法,才使得有后面韩国Hyeonwoo Noh的对称反卷积网络,剑桥的SegNet等优秀用于语义分割的CNN网络。
这篇关于FCN全卷积语义分割网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





