本文主要是介绍SSD目标检测lmdb数据结构剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SSD读取训练集是从LMDB中读取AnnotatedDatum结构的数据,在训练和测试之前,要将图片(img)和XML(label)数据存储为AnnotatedDatum结构,然后将数据经过序列化,存入到LMDB数据库中。训练和测试的时候直接从LMDB读取数据,经过反序列化获取AnnotatedDatum结构的数据,获得训练集的图片和XML数据。
可以参考ssd caffe目录包下的src/caffe/util/io.cpp, tools/convert_annoset.cpp,会对你理解数据结构有很大的作用。
AnnotatedData数据结构
message AnnotatedDataParameter {
// Define the sampler.
repeated BatchSampler batch_sampler = 1;
// Store label name and label id in LabelMap format.
optional string label_map_file = 2;
// If provided, it will replace the AnnotationType stored in each
// AnnotatedDatum.
optional AnnotatedDatum.AnnotationType anno_type = 3;
}
一、LMDB数据库
- LMDB的全称是Lightning Memory-Mapped
Database,意为闪电般的内存映射数据库。它文件结构简单,一个文件夹,里面一个数据文件data.mdb,一个锁文件lock.mdb。数据随意复制,随意传输。它的访问简单,不需要运行单独的数据库管理进程,只要在访问数据的代码里引用LMDB库,访问时给文件路径即可。 - Caffe引入数据库存放数据集,是为了减少IO开销。LMDB的整个数据库放在一个文件里,避免了文件系统寻址的开销。LMDB使用内存映射的方式访问文件,使得文件内寻址的开销非常小,使用指针运算就能实现。数据库单文件还能减少数据集复制/传输过程的开销。一个几万,几十万文件的数据集,不管是直接复制,还是打包再解包,过程都无比漫长而痛苦。LMDB数据库只有一个文件,传输介质有多块,就能复制多快,不会因为文件多而变得很慢。

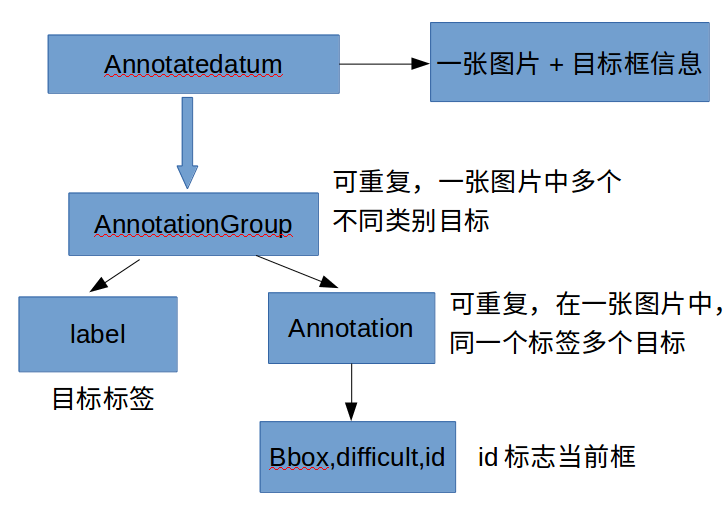
二、AnnotatedDatum数据结构
以PASCAL VOC数据集为例,label为$CAFFE_ROOT/data/VOCdevkit/VOC2007/Annotations下的XML文件,图片为$CAFFE_ROOT/data/VOCdevkit/VOC2007/JPEGImages下的图片文件。

- SSD读取数据,要将label和图片封装到一个数据结构下,用的是AnnotatedDatum结构,定义如下:
// An extension of Datum which contains "rich" annotations.
message AnnotatedDatum {enum AnnotationType {BBOX = 0;}optional Datum datum = 1;// If there are "rich" annotations, specify the type of annotation.// Currently it only supports bounding box.// If there are no "rich" annotations, use label in datum instead.optional AnnotationType type = 2;// Each group contains annotation for a particular class.repeated AnnotationGroup annotation_group = 3;
}- AnnotatedDatum结构里面包含AnnotationGroup结构、Datum结构和AnnotationType。Datum结构用于存放图片信息,后面会说到;使用$CAFFE_ROOT/src/caffe/util/io.cpp里面定义的ReadXMLToAnnotatedDatum函数将XML文件信息存储到AnnotationGroup结构中,AnnotationGroup结构定义如下:
// Group of annotations for a particular label.
message AnnotationGroup {optional int32 group_label = 1;repeated Annotation annotation = 2;
}- AnnotationGroup结构包含group_label和Annotation结构,group_label根据$CAFFE_ROOT/data/VOC0712/labelmap_voc.prototxt进行转换,将object的name改为数字,Annotation结构定义如下:
// Annotation for each object instance.
message Annotation {optional int32 instance_id = 1 [default = 0];optional NormalizedBBox bbox = 2;
}- Annotation结构包含instance_id和NormalizedBBox结构,NormalizedBBox即为XML文件每个object里面bbox的四个坐标点(xmin,ymin,xmax,ymax)。
这样XML文件的内容就存到了AnnotatedDatum结构里面。
(以上结构的定义文件都存储在$CAFFE_ROOT/src/caffe/proto/caffe.proto中)
三、Datum数据结构
AnnotatedDatum类里面包括Datum结构,用来存放图片数据。
- Datum的定义:
message Datum {optional int32 channels = 1;optional int32 height = 2;optional int32 width = 3;// the actual image data, in bytesoptional bytes data = 4;optional int32 label = 5;// Optionally, the datum could also hold float data.repeated float float_data = 6;// If true data contains an encoded image that need to be decodedoptional bool encoded = 7 [default = false];
}channels、height和width为Datum数据的三个维度。byte_data和float_data是存放数据的地方,分别存放整数型和浮点型数据。图像数据一般是整形,放在byte_data里,特征向量一般是浮点型,放在float_data里。label存放数据的类别标签,是整数型。encoded标识数据是否需要被解码(里面有可能放的是JPEG或者PNG之类经过编码的数据)。
- 使用$CAFFE_ROOT/src/caffe/util/io.cpp里面定义的ReadImageToDatum函数将图片数据存储到Datum结构中。先用OpenCV将图片读取为矩阵形式,获取图片的三维数据,将这些数据存储到Datum结构中。相关代码如下:
bool ReadImageToDatum(const string& filename, const int label,const int height, const int width, const int min_dim, const int max_dim,const bool is_color, const std::string & encoding, Datum* datum) {cv::Mat cv_img = ReadImageToCVMat(filename, height, width, min_dim, max_dim,is_color);if (cv_img.data) {if (encoding.size()) {if ( (cv_img.channels() == 3) == is_color && !height && !width &&!min_dim && !max_dim && matchExt(filename, encoding) ) {datum->set_channels(cv_img.channels());datum->set_height(cv_img.rows);datum->set_width(cv_img.cols);return ReadFileToDatum(filename, label, datum);}EncodeCVMatToDatum(cv_img, encoding, datum);datum->set_label(label);return true;}CVMatToDatum(cv_img, datum);datum->set_label(label);return true;} else {return false;}
}四、Python读取LMDB
为了加深理解,我用python写了一个读取LMDB数据的脚本,将存储在LMDB中的AnnotatedDatum结构中的图片和XML文件读取出来,获取object的name即label,并将图片用OpenCV显示,代码如下:
# -*- coding: utf-8 -*
import caffe
import lmdb
import numpy as np
import cv2
from caffe.proto import caffe_pb2lmdb_env = lmdb.open('/home/computer/wcaffe_test/examples/VOC0712/VOC0712_test_lmdb')lmdb_txn = lmdb_env.begin() # 生成处理句柄
lmdb_cursor = lmdb_txn.cursor() # 生成迭代器指针
annotated_datum = caffe_pb2.AnnotatedDatum() # AnnotatedDatum结构for key, value in lmdb_cursor:print keyannotated_datum.ParseFromString(value)datum = annotated_datum.datum # Datum结构grps = annotated_datum.annotation_group # AnnotationGroup结构type = annotated_datum.typefor grp in grps:xmin = grp.annotation[0].bbox.xmin * datum.width # Annotation结构ymin = grp.annotation[0].bbox.ymin * datum.heightxmax = grp.annotation[0].bbox.xmax * datum.widthymax = grp.annotation[0].bbox.ymax * datum.heightprint "label:", grp.group_label # object的name标签print "bbox:", xmin, ymin, xmax, ymax # object的bbox标签label = datum.label # Datum结构label以及三个维度 channels = datum.channelsheight = datum.heightwidth = datum.widthprint "label:", labelprint "channels:", channelsprint "height:", heightprint "width:", widthimage_x = np.fromstring(datum.data, dtype=np.uint8) # 字符串转换为矩阵image = cv2.imdecode(image_x, -1) # decodecv2.imshow("image", image) # 显示图片if cv2.waitKey(1) & 0xFF == ord('q'):break这篇关于SSD目标检测lmdb数据结构剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







