本文主要是介绍200页图解国标《数据分类分级规则》正式稿,强化重要数据识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
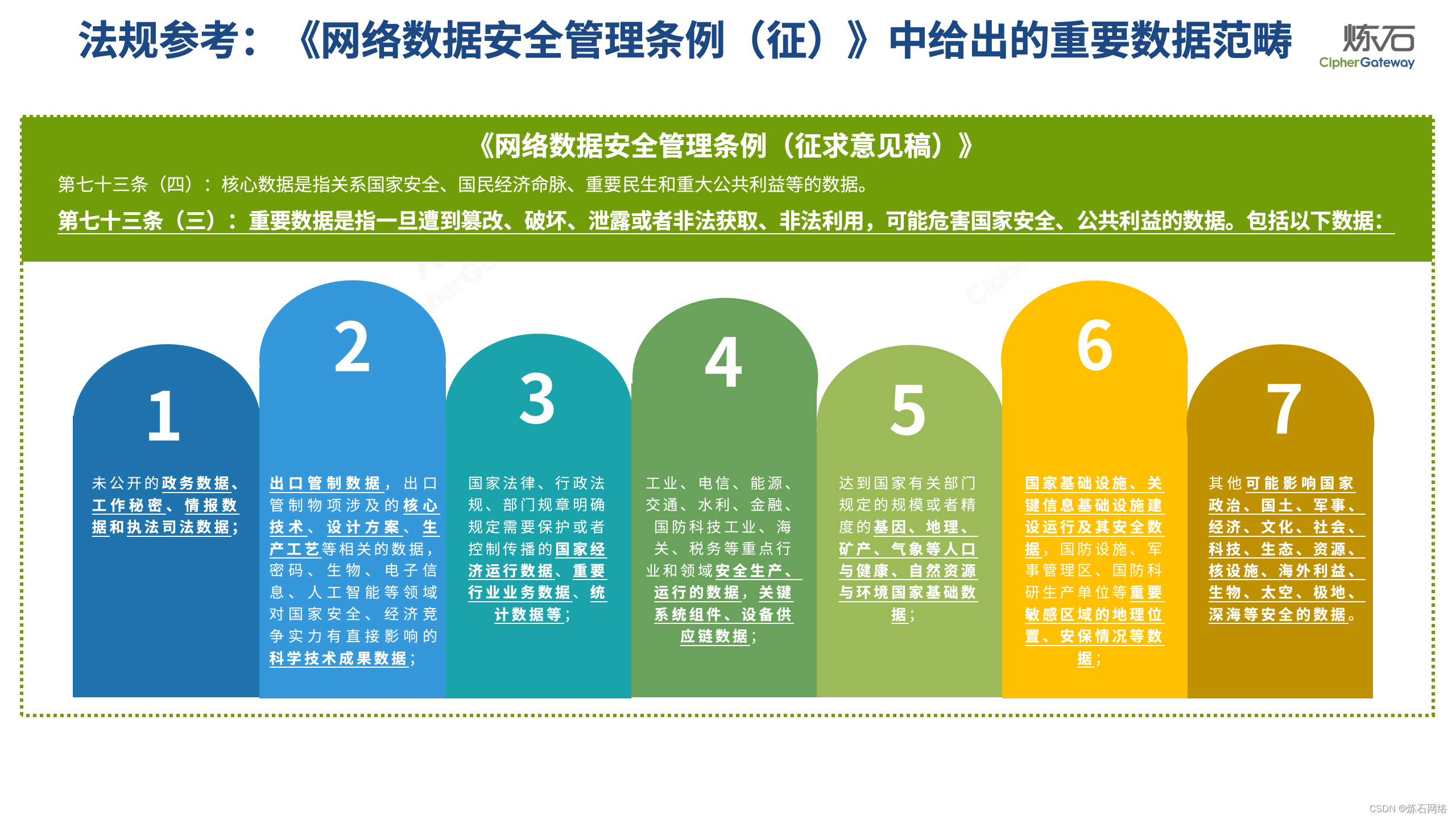
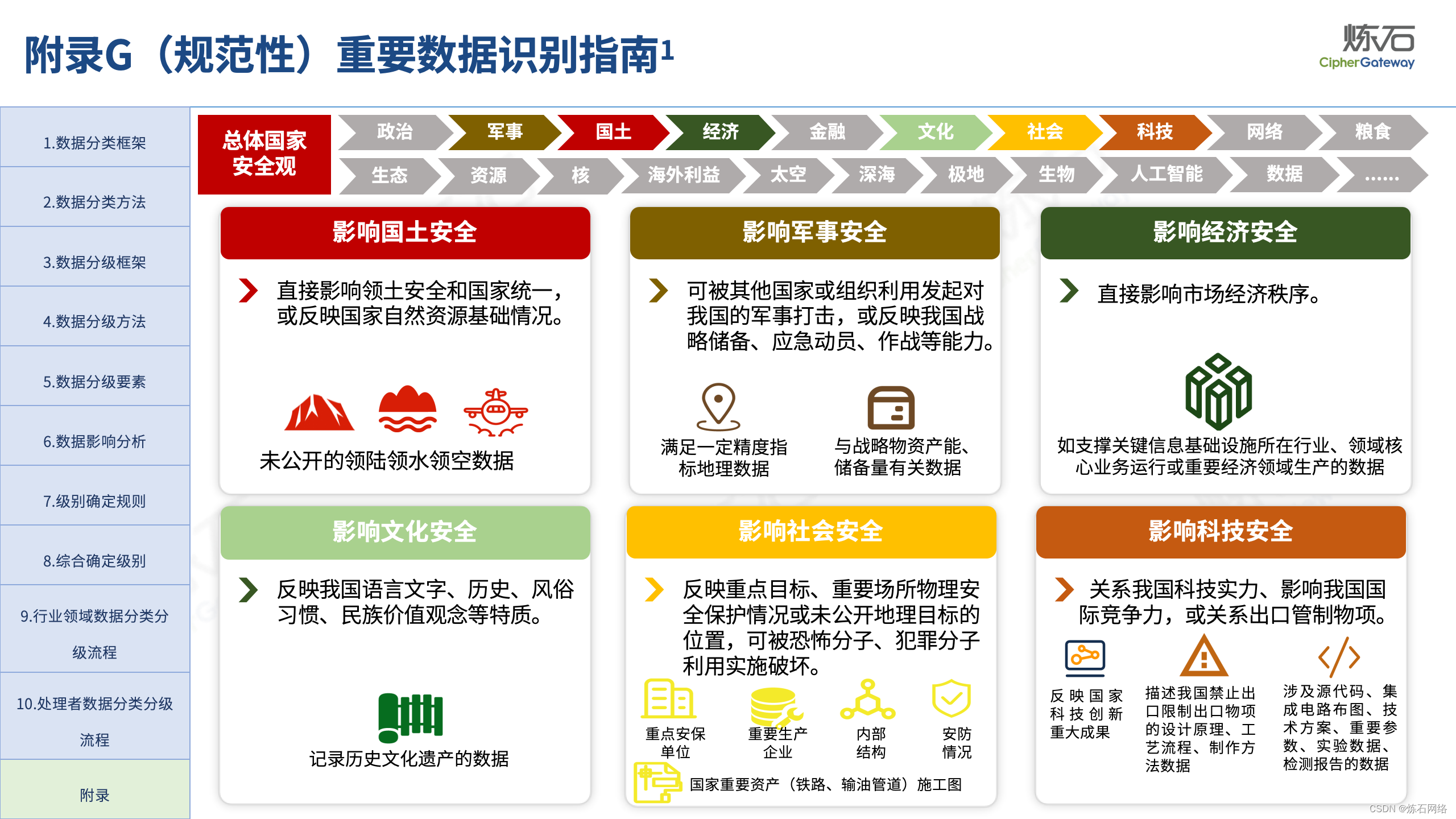
GB/T 43697-2024《数据安全技术 数据分类分级规则》正式稿发布,并于2024年10月1日实施。2024年4月17日,国家标准全文公开系统公布了国标最终版。《数据分类分级规则》是全国网安标委更名后,发布的第一部以“数据安全技术”命名的国家标准,也是指导各领域数据分类分级工作的基础性国标。数据分类分级工作的核心和基础是重要数据识别,本国标将《数据分类分级要求》与《重要数据识别指南》两标准进行合并,不仅规定了数据分类分级的通用方法,而且将原《重要数据识别指南》内容体现在附录G(规范性)中,给出了18项重要数据识别因素,进一步细化、补充了重要数据识别的执行要求。不同于资料性附录,附录G(规范性)作为强制性和地位与正文效力一致的技术要素,是必须执行的技术要求,各地区、各部门识别重要数据或制定重要数据识别规范可重点参考附录G。

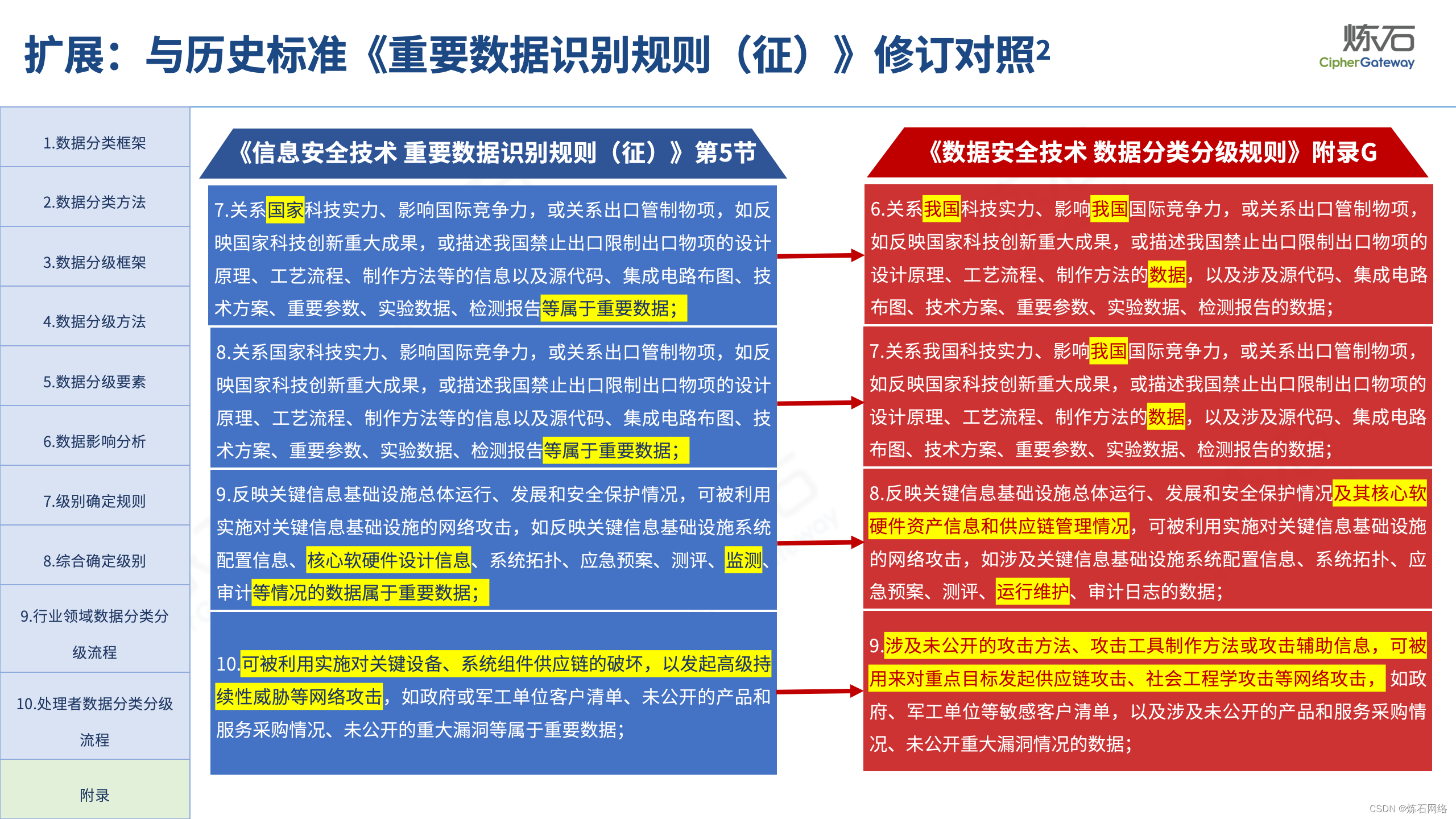
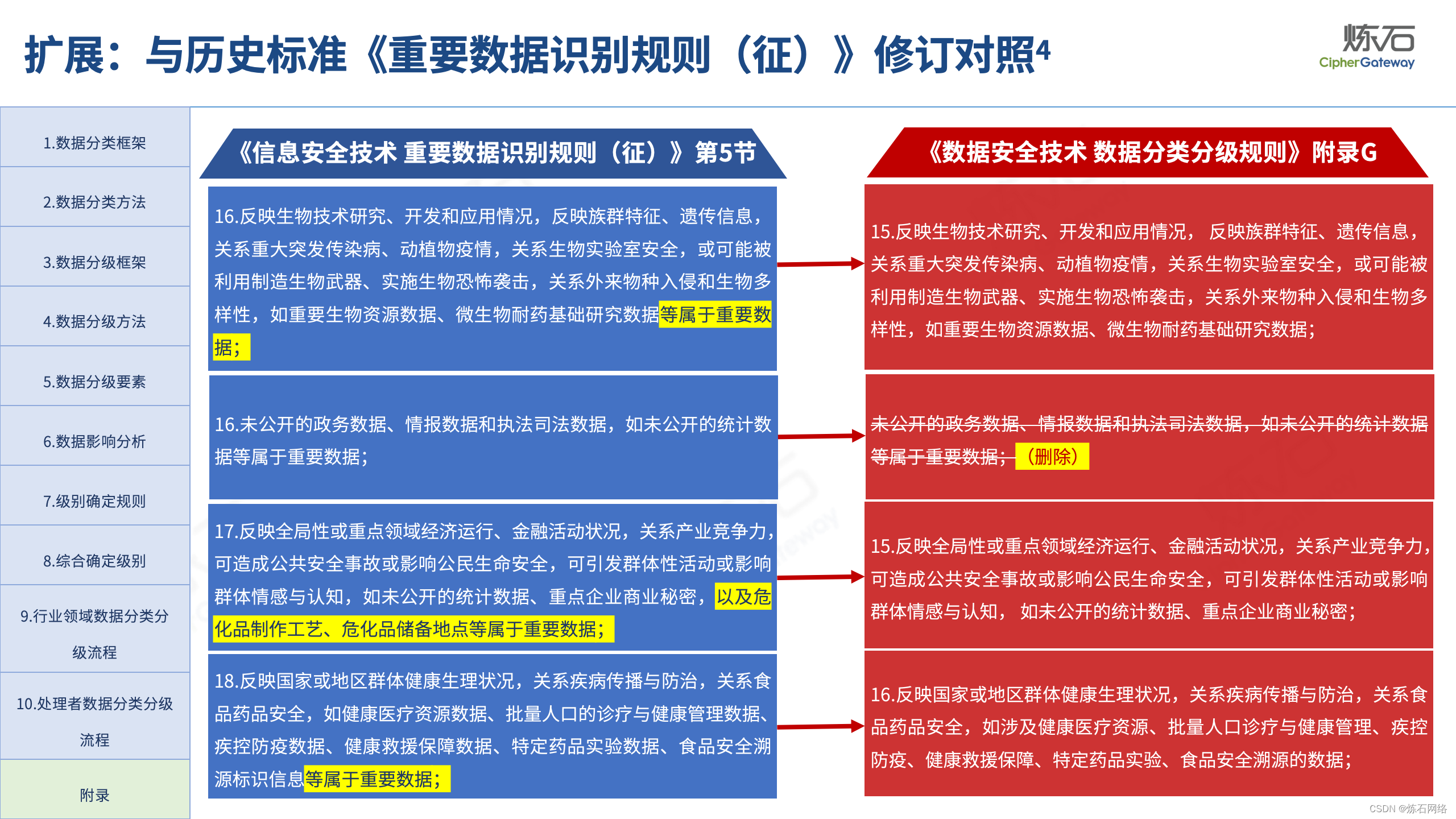
本次图解中,炼石聚焦国标《数据分类分级规则》的附录G(规范性),不仅扩展了规范性附录与资料性附录的区别、制定背景、重要数据定义演进、国内外重要数据识别参照政策、重要数据识别思路等内容,而且将18项重要数据识别因素与总体国家安全观、《信息安全技术 重要数据识别规则(征求意见稿)》做逐条对照,以期为各地区、各部门及从业者开展数据分类分级、重要数据识别提供参考。由于作者水平有限,欢迎业界同仁共同探讨完善。
从微信中搜索公众号:炼石网络CipherGateway,并后台回复关键词“炼石就是数据安全104”,即可下载【正式版-炼石图解《数据安全技术 数据分类分级规则》PDF版及标准原文】。
原创声明:北京炼石网络技术有限公司对本文的内容及相关产品信息拥有受法律保护的著作权,未经授权许可,任何人不得将本文的全部或部分内容以转让、出售等方式用于商业目的使用。转载、摘编使用本文文字或者观点的应注明来源。文中所载的材料和信息,包括但不限于文本、图片、数据、观点、建议等各种形式,不能替代律师出具的法律意见。违反上述声明者,本公司将追究其相关法律责任。本文撰写过程中,为便于技术说明和涵义解释,引用了一系列的参考文献,内容如有侵权,请联系本公司修改或删除。如需转载请关注公众号回复“转载”,或在文章下方留言。
注:欢迎业界同仁反馈改进、共同完善、交流合作,信息反馈请发送邮件至:support@ciphergateway.com。由于少部分文件未公开正式版本,因此仅提供更早版本文件或不提供文件下载。
为了共同推动数据安全产业发展,欢迎行业同仁加入“[炼石]数据安全技术圈”微信群,探讨数据安全技术最新动态和最佳实践。







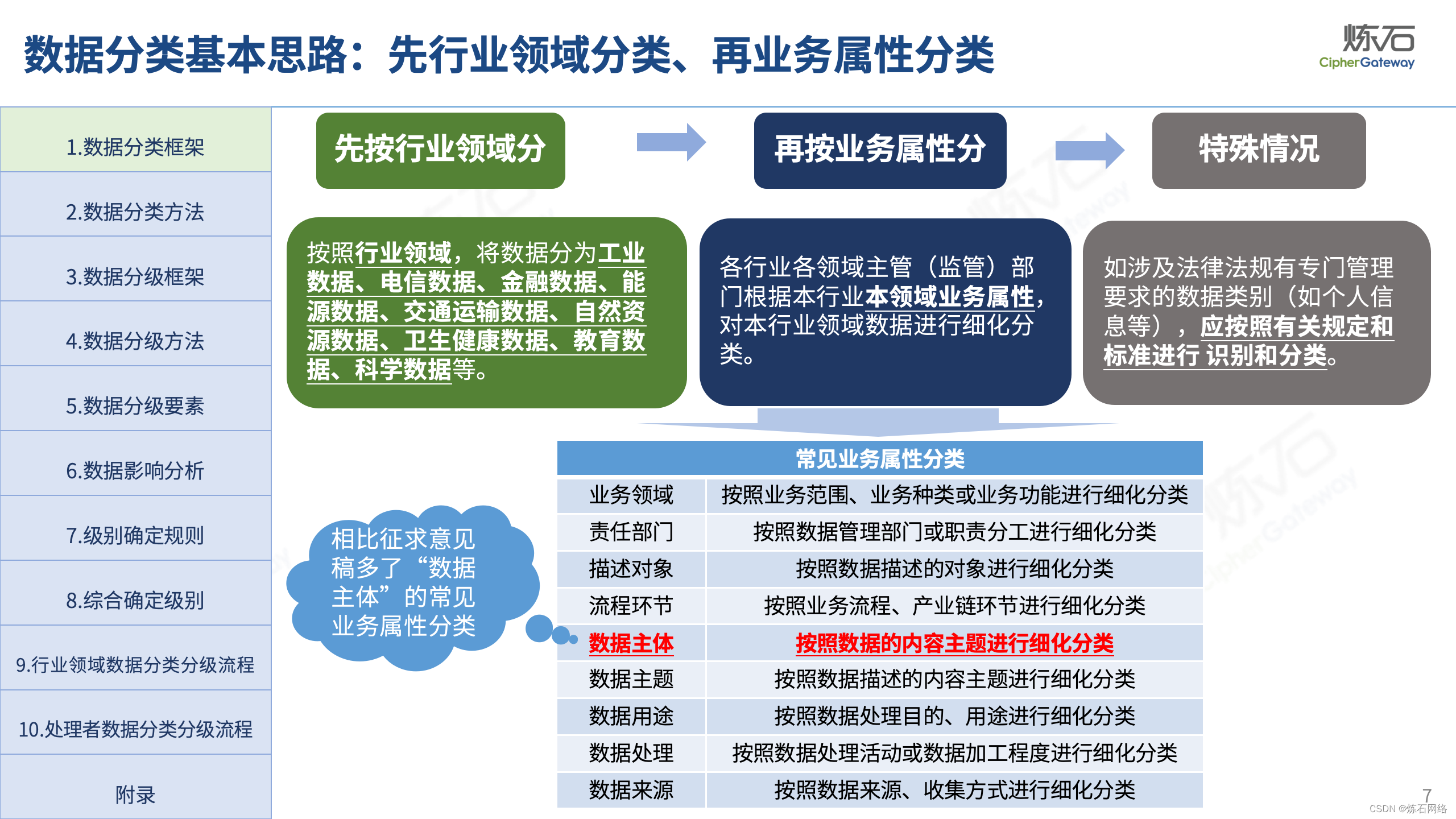
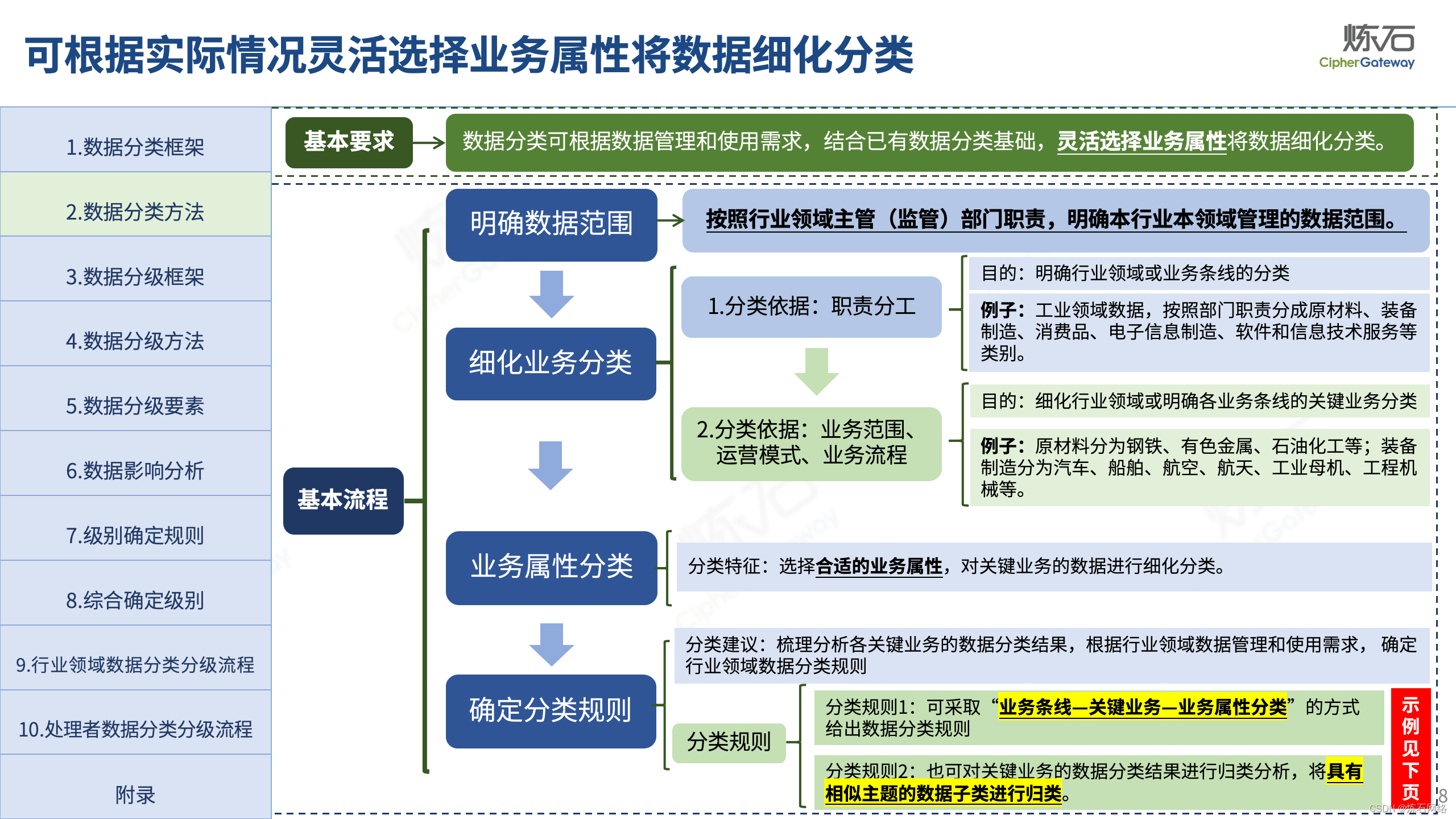
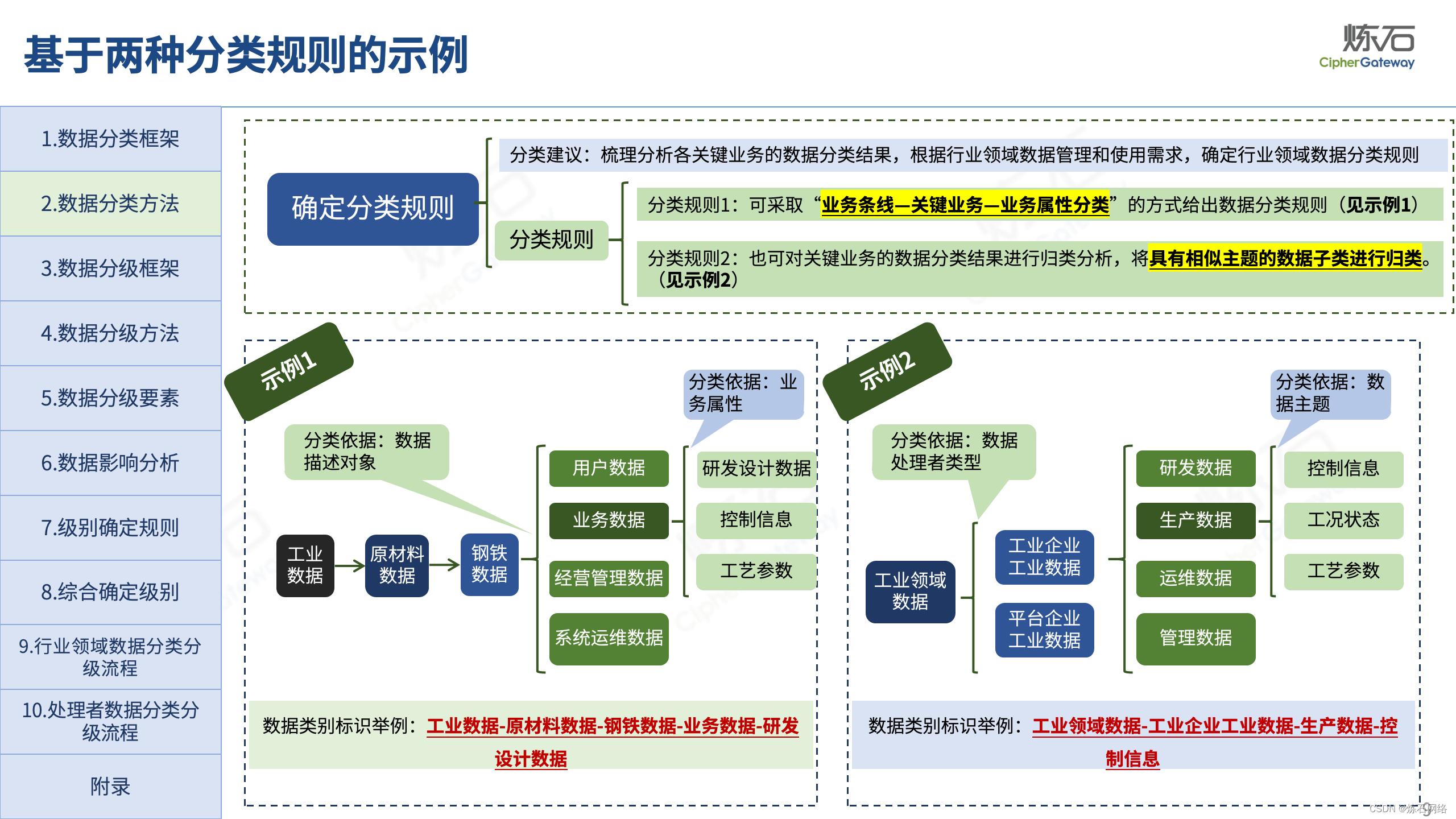

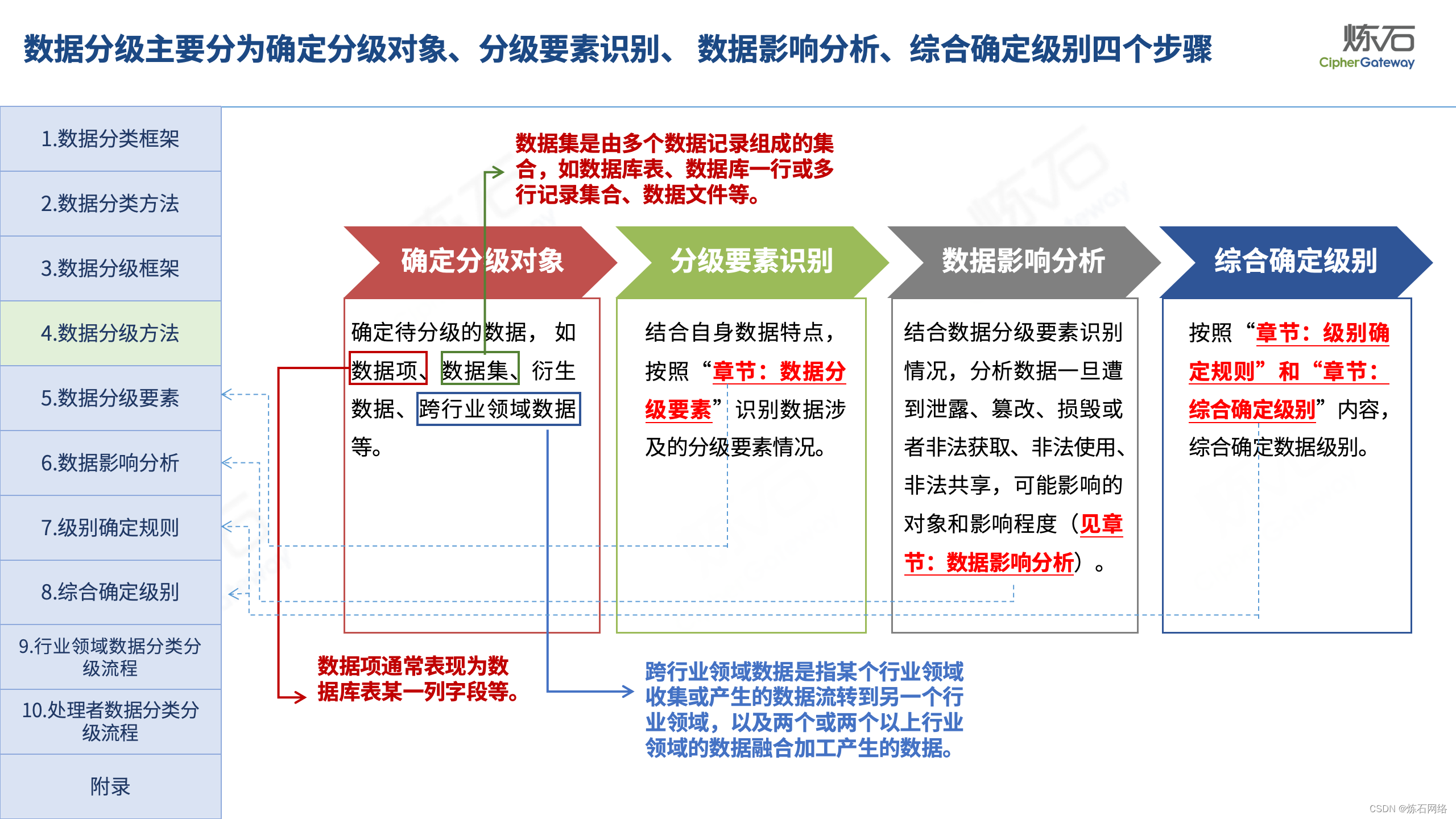


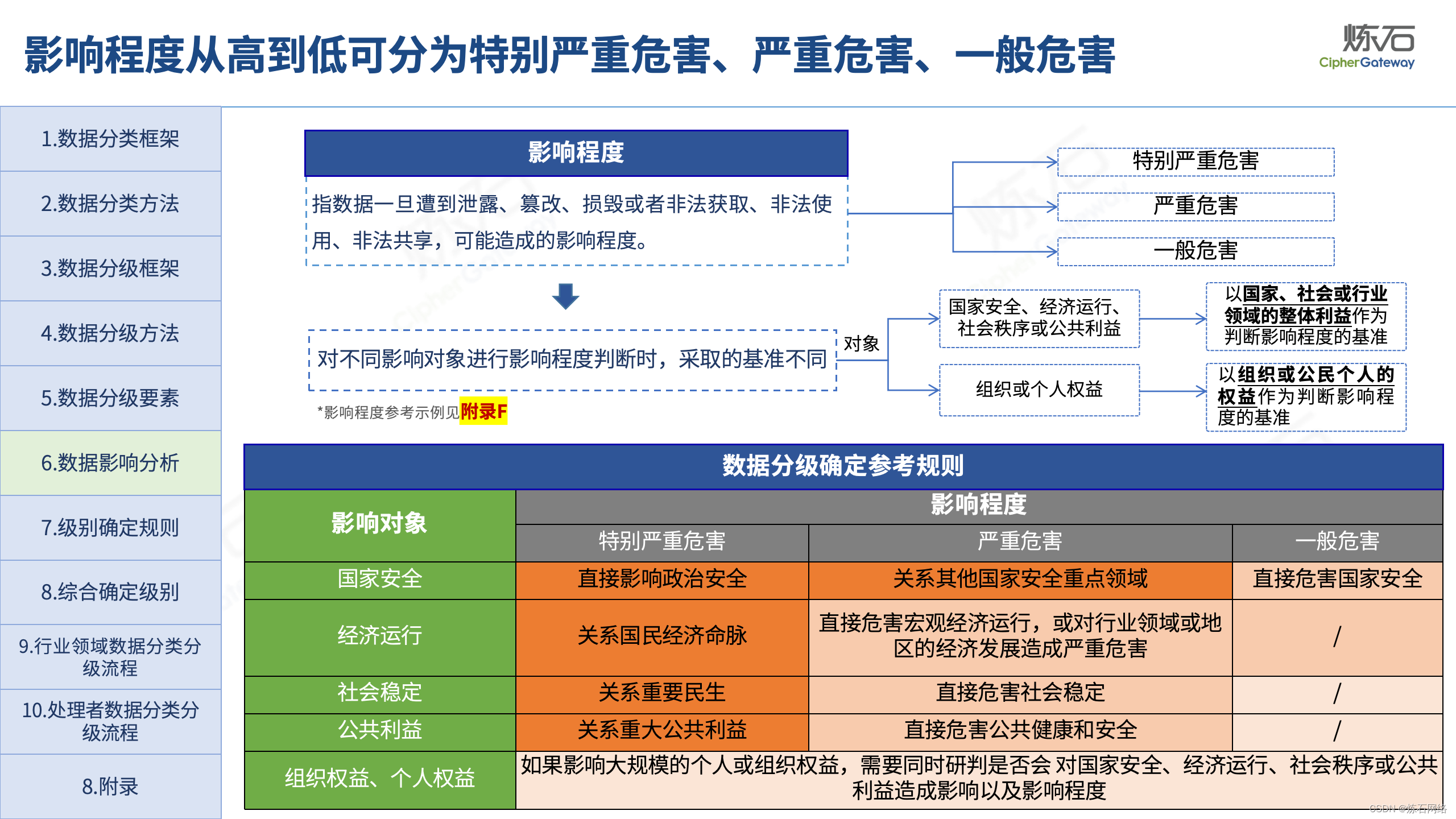
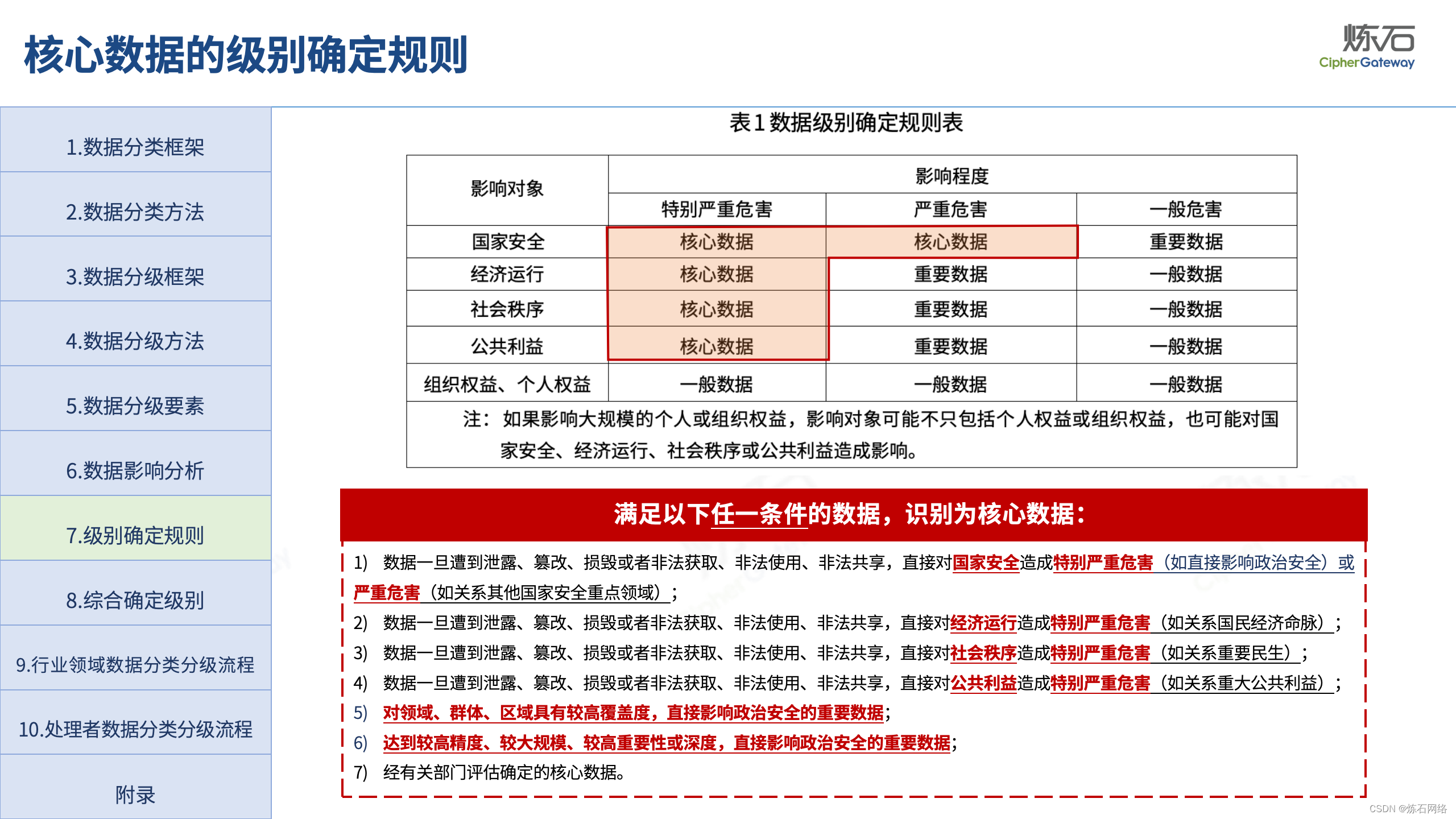

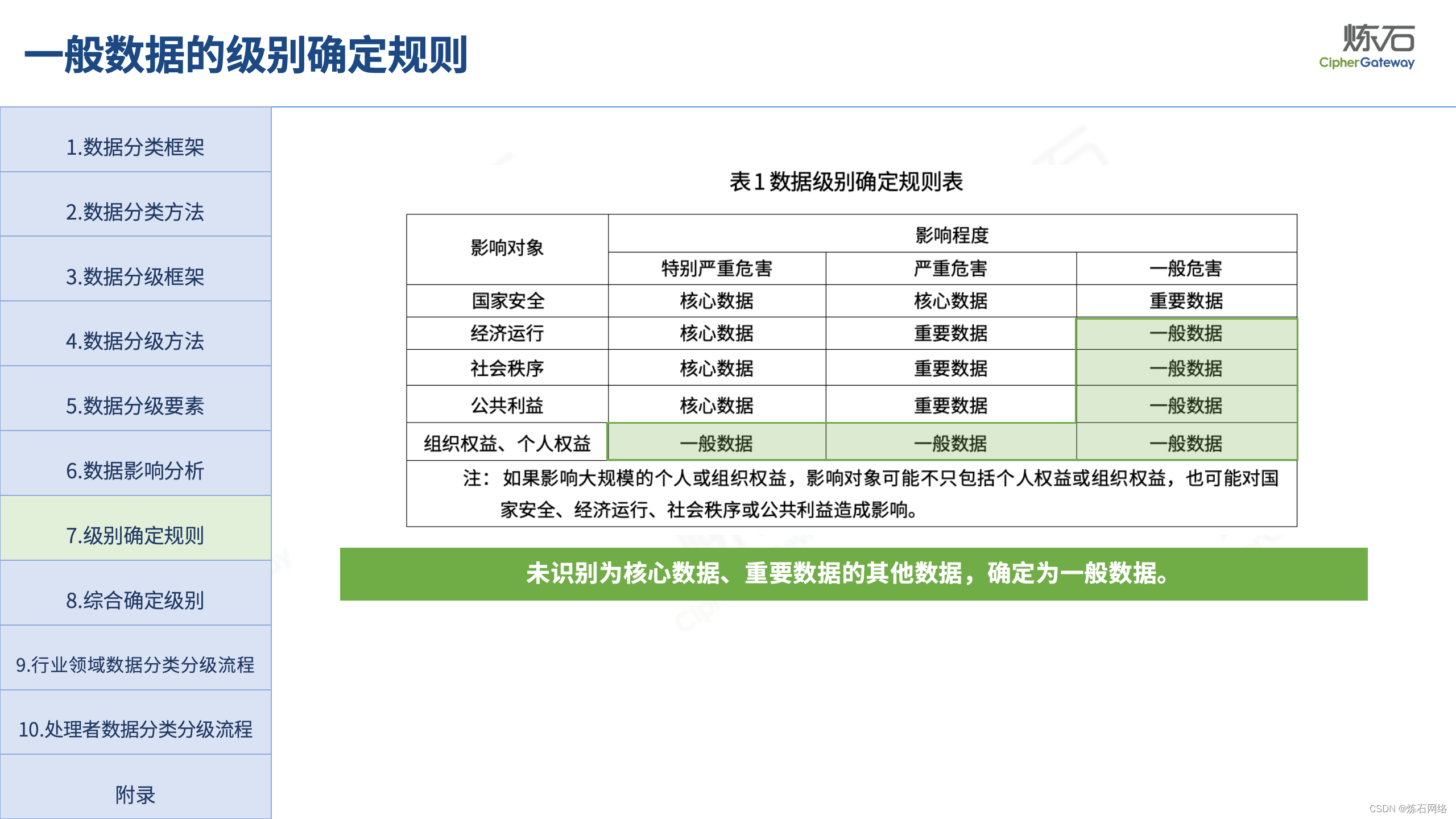






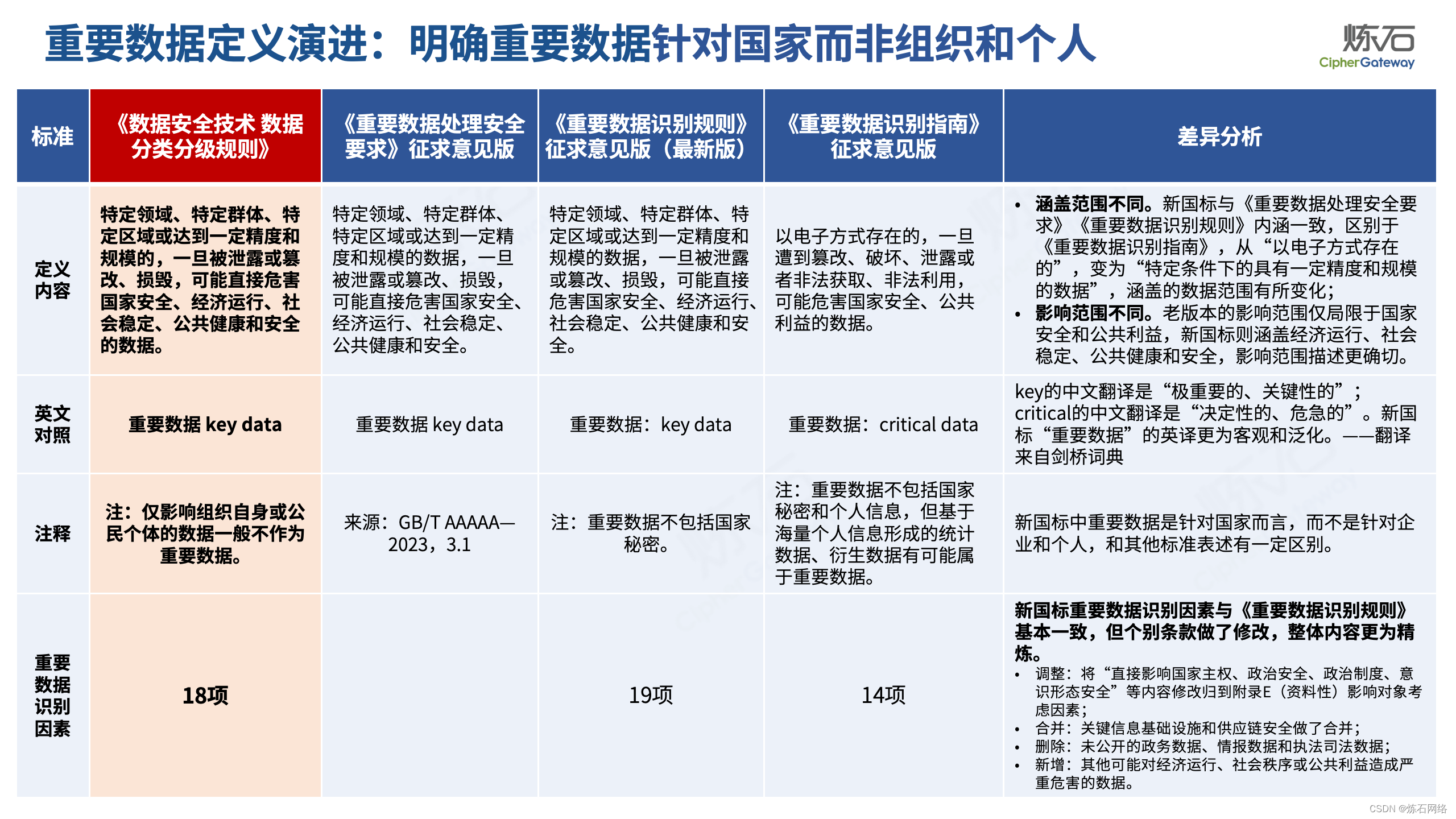








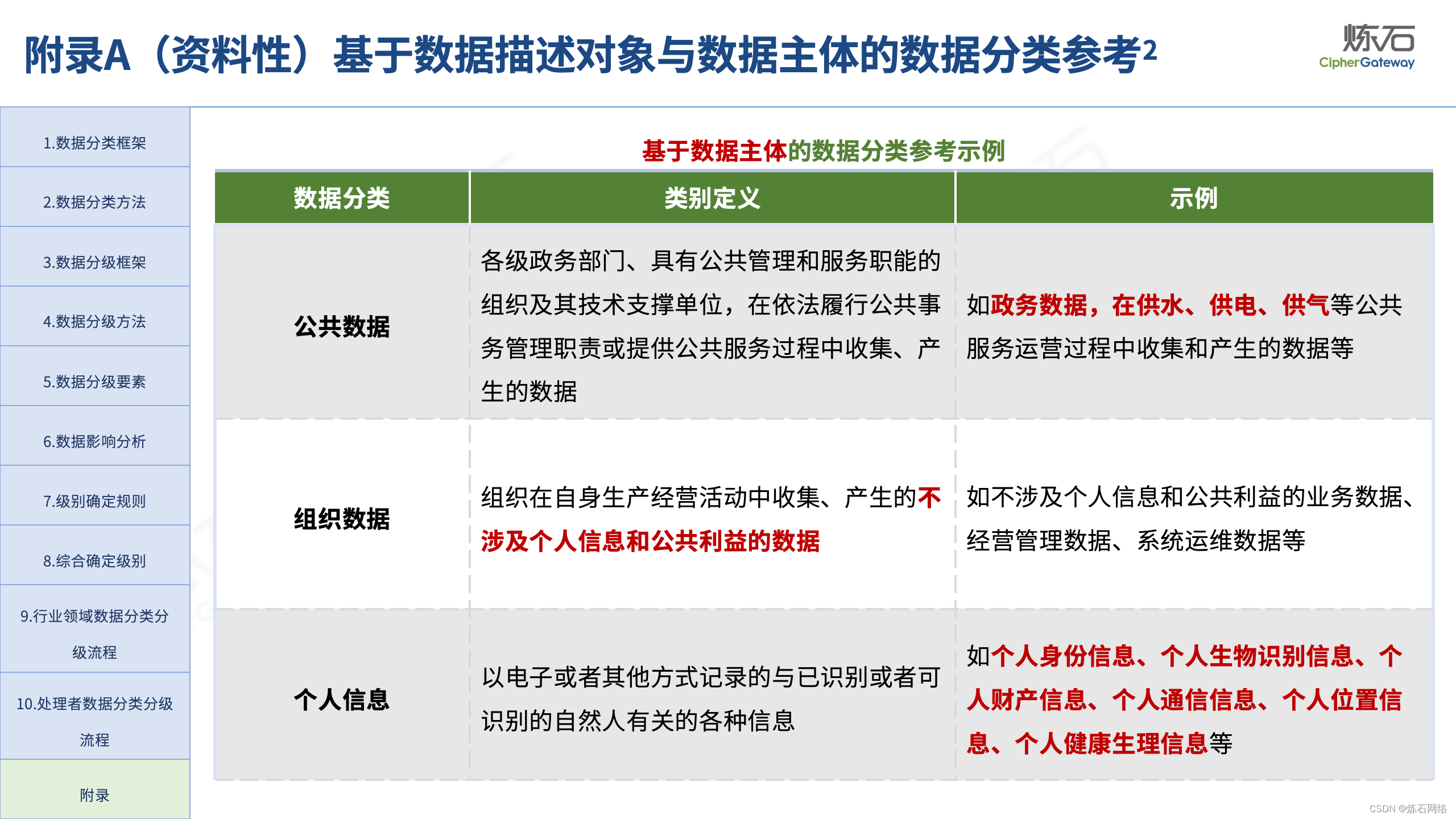
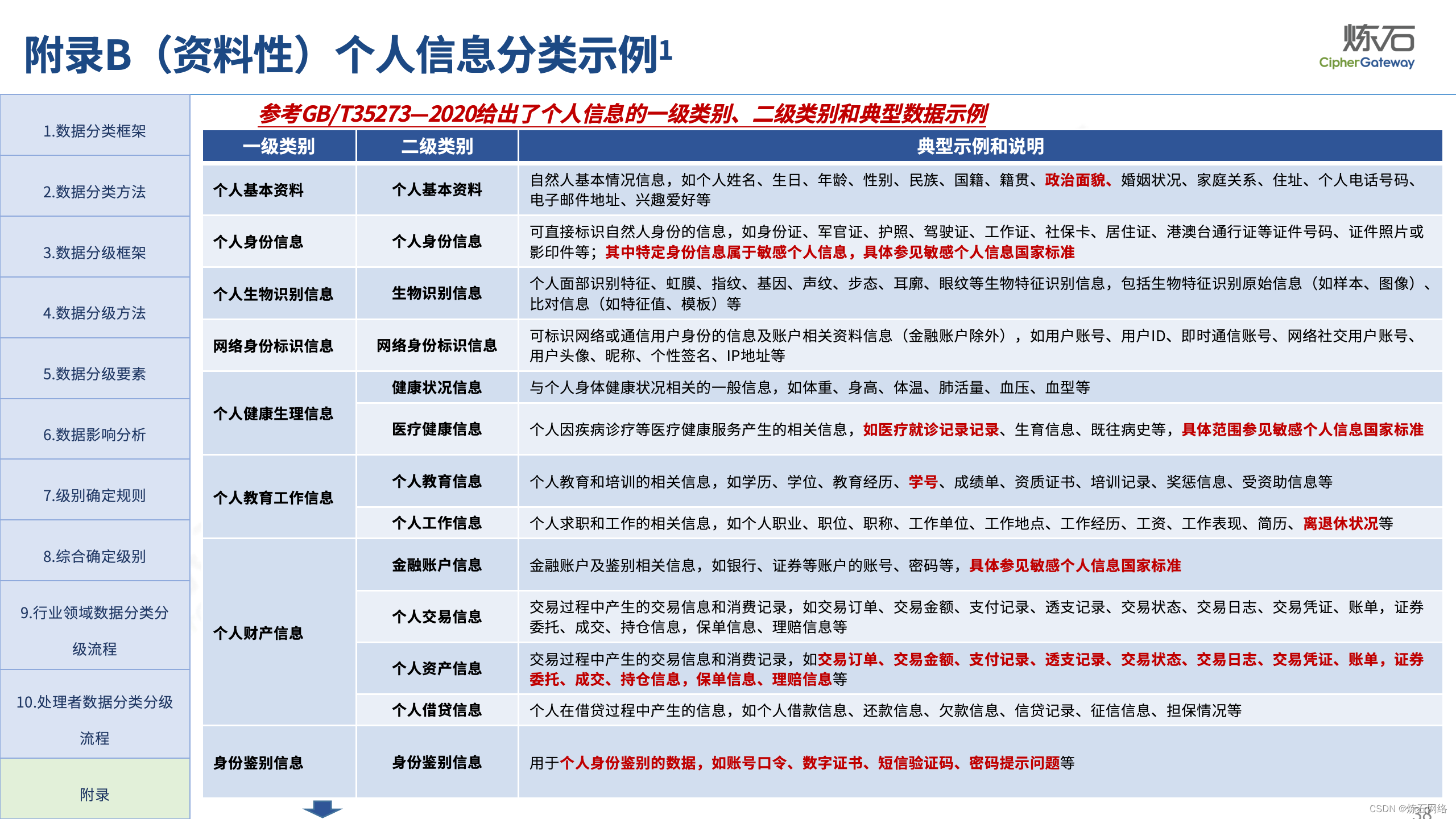

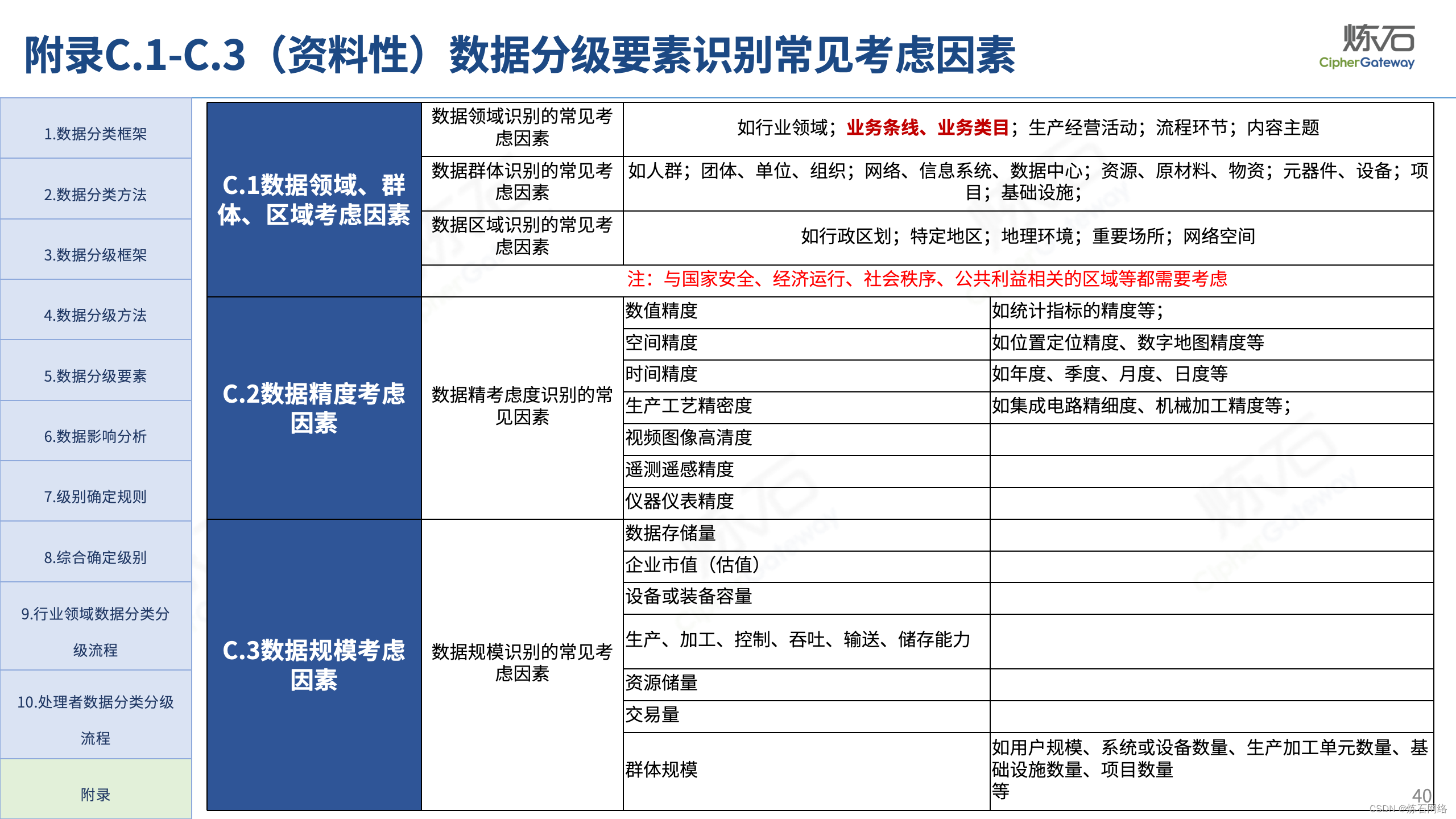
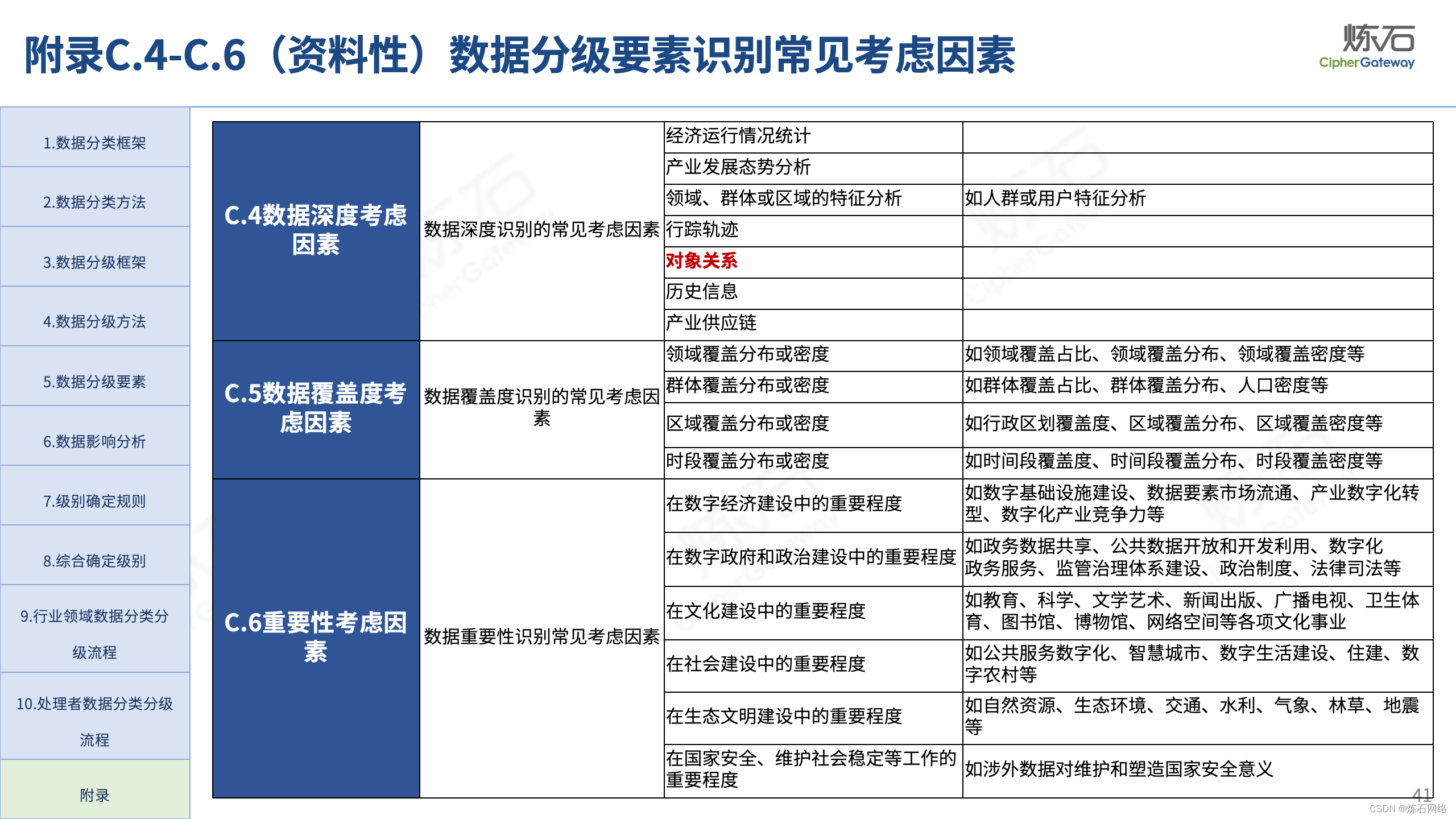
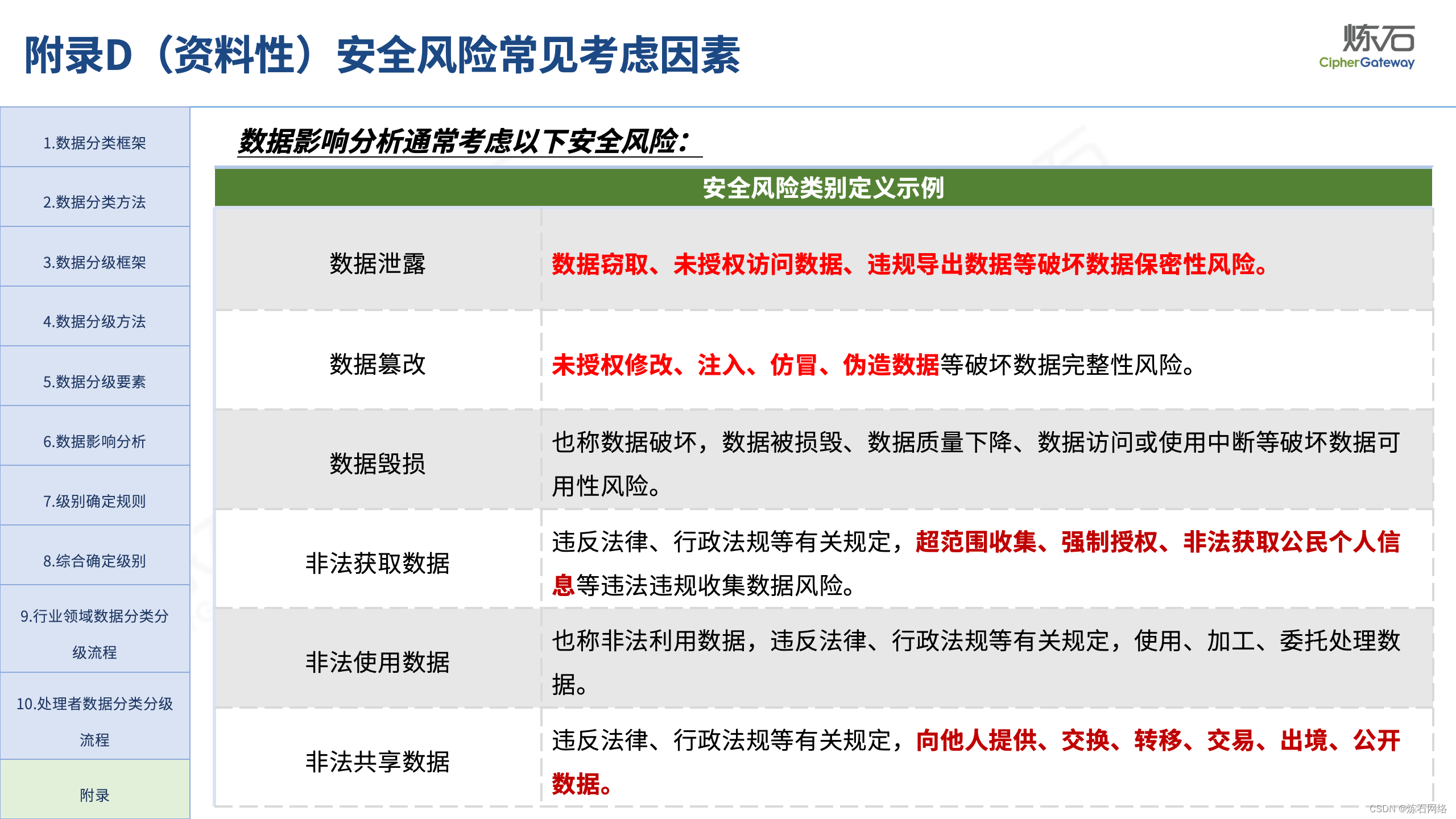







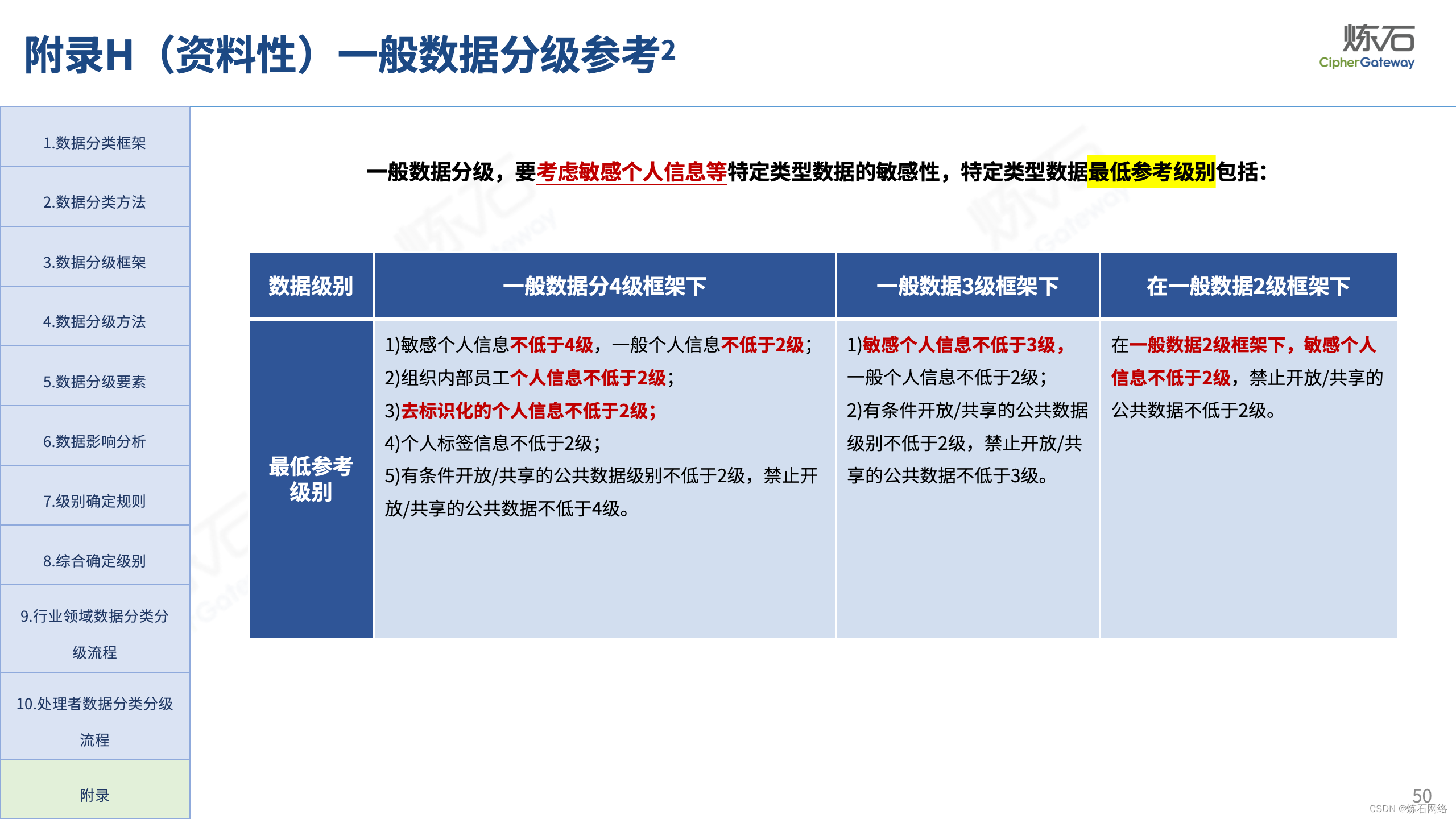






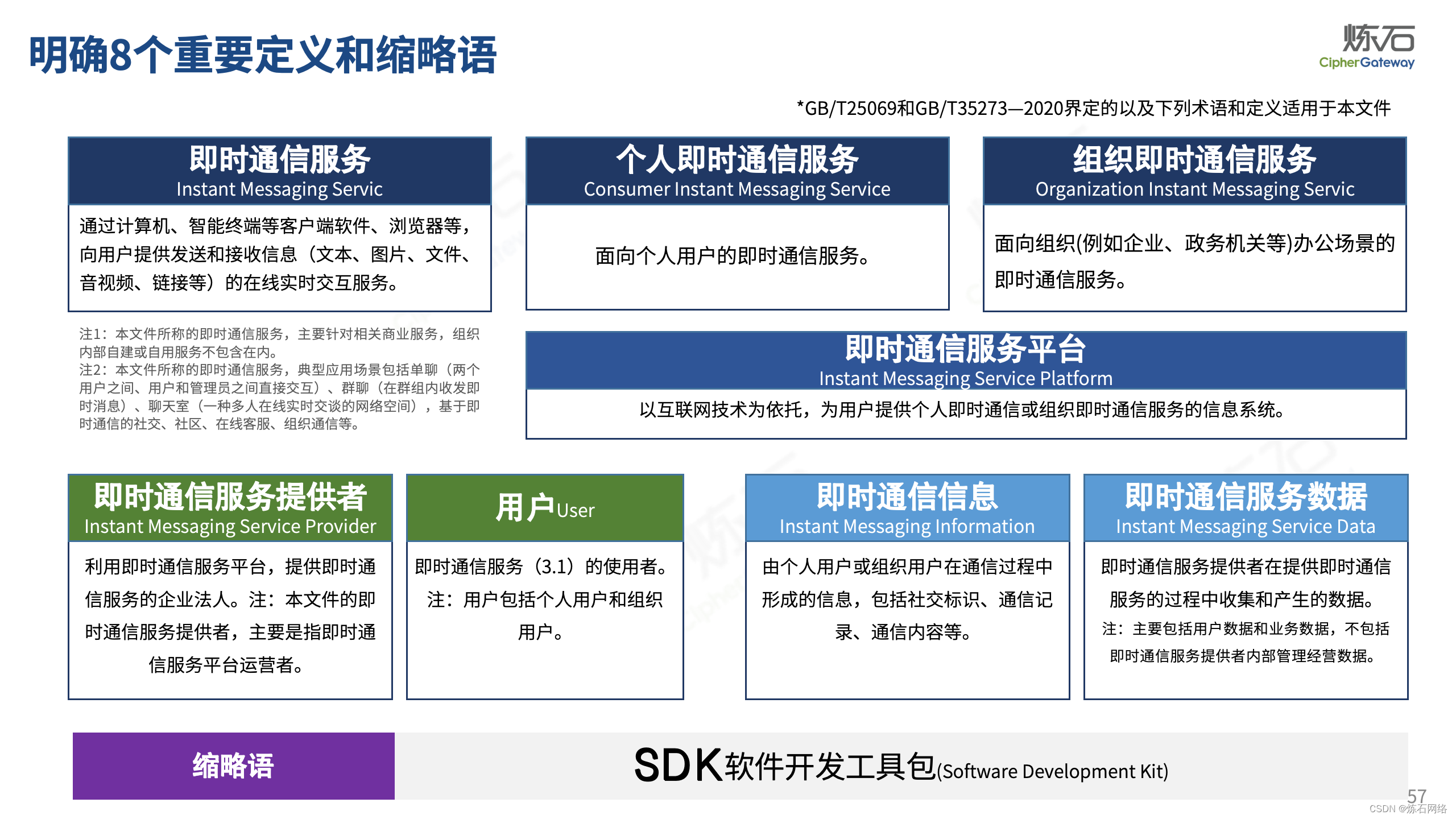








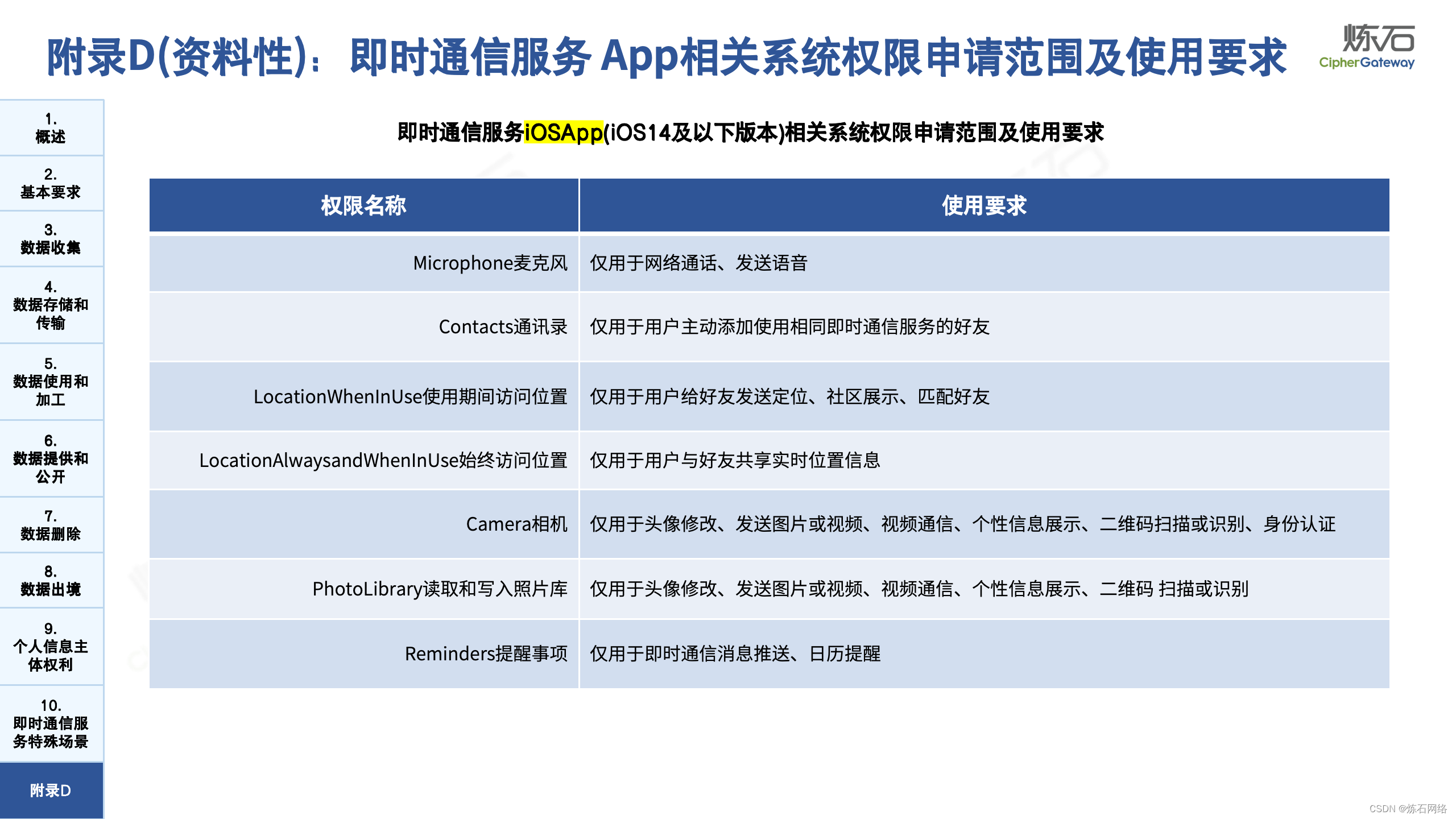










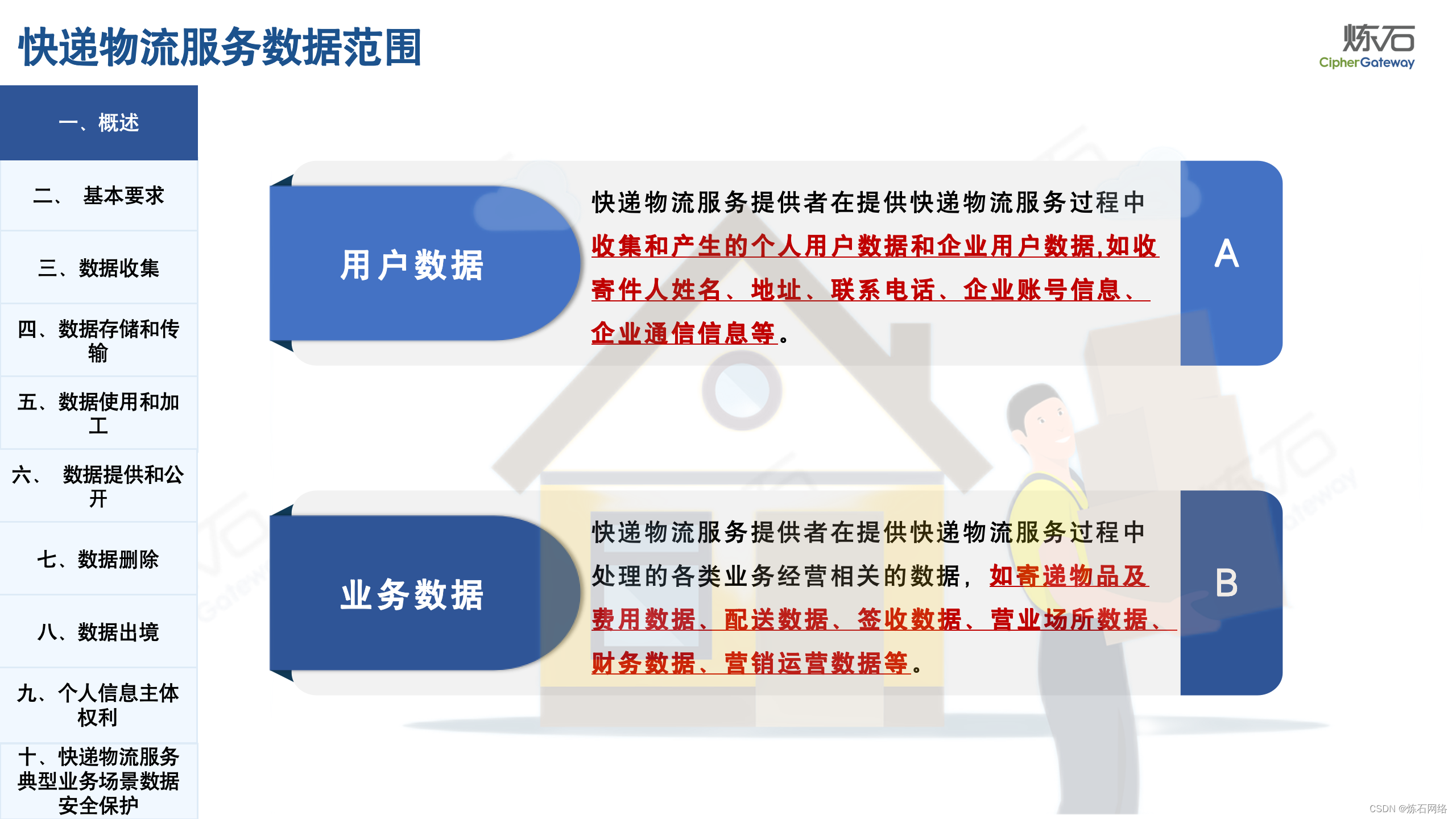

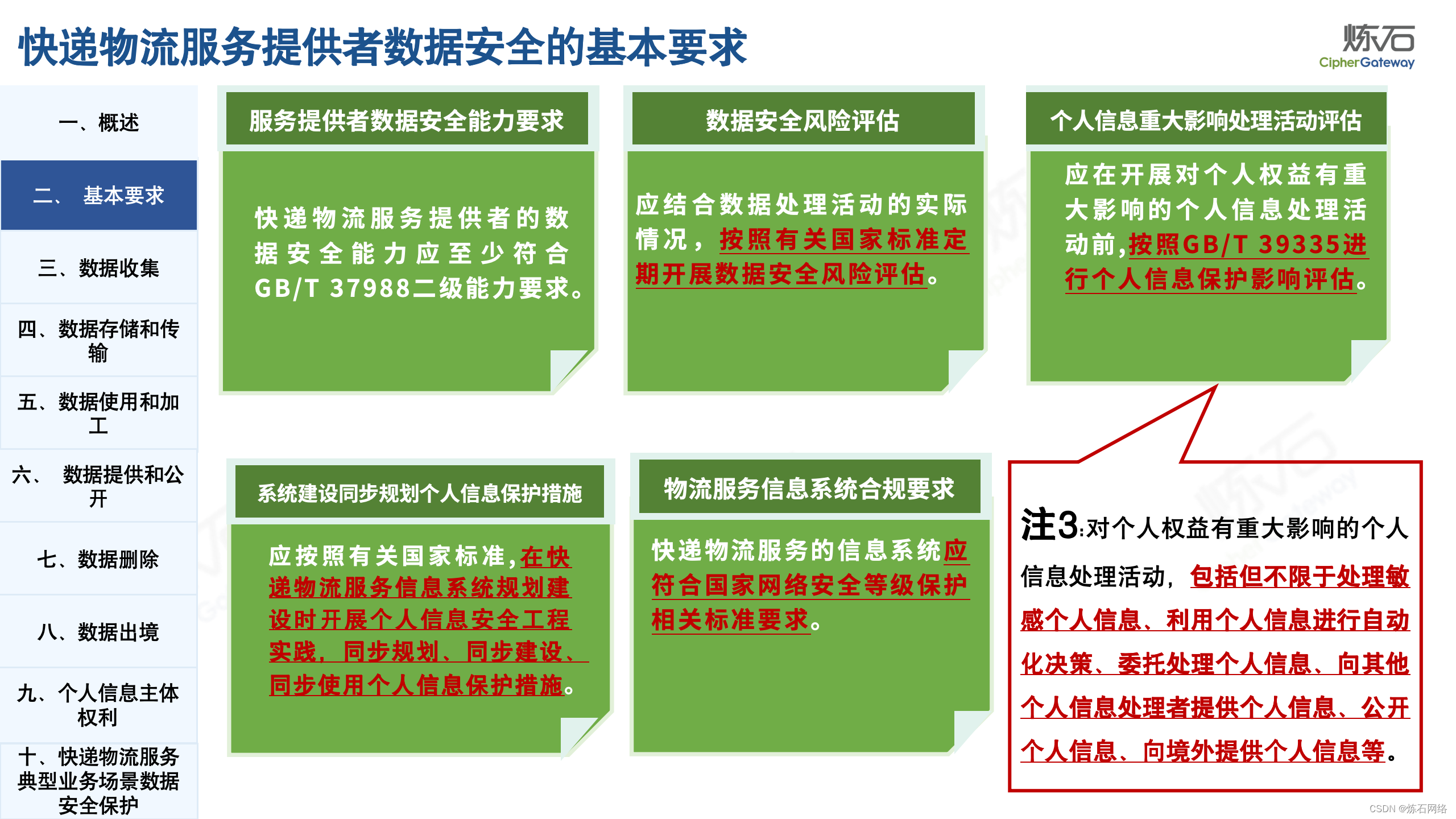









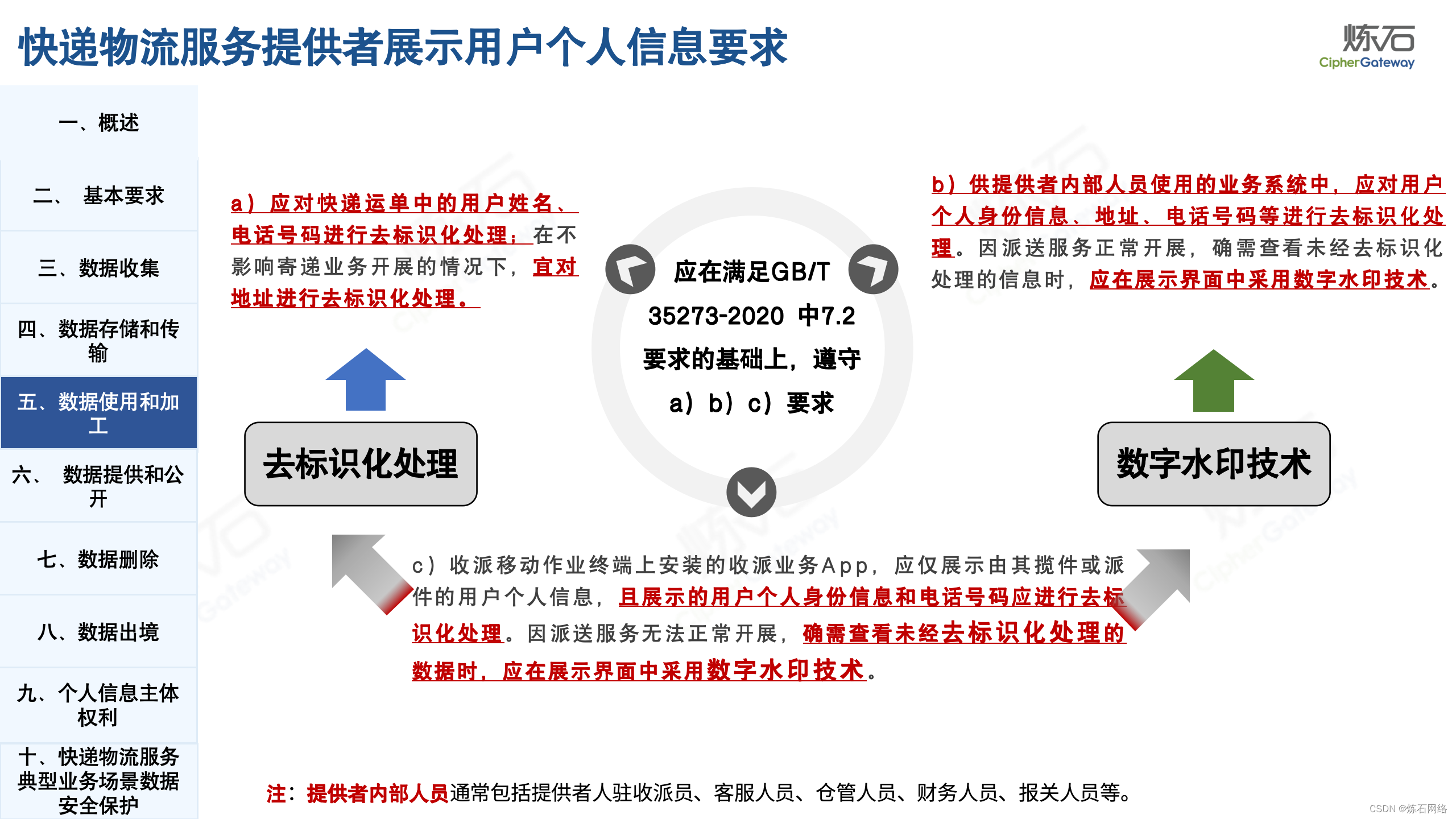


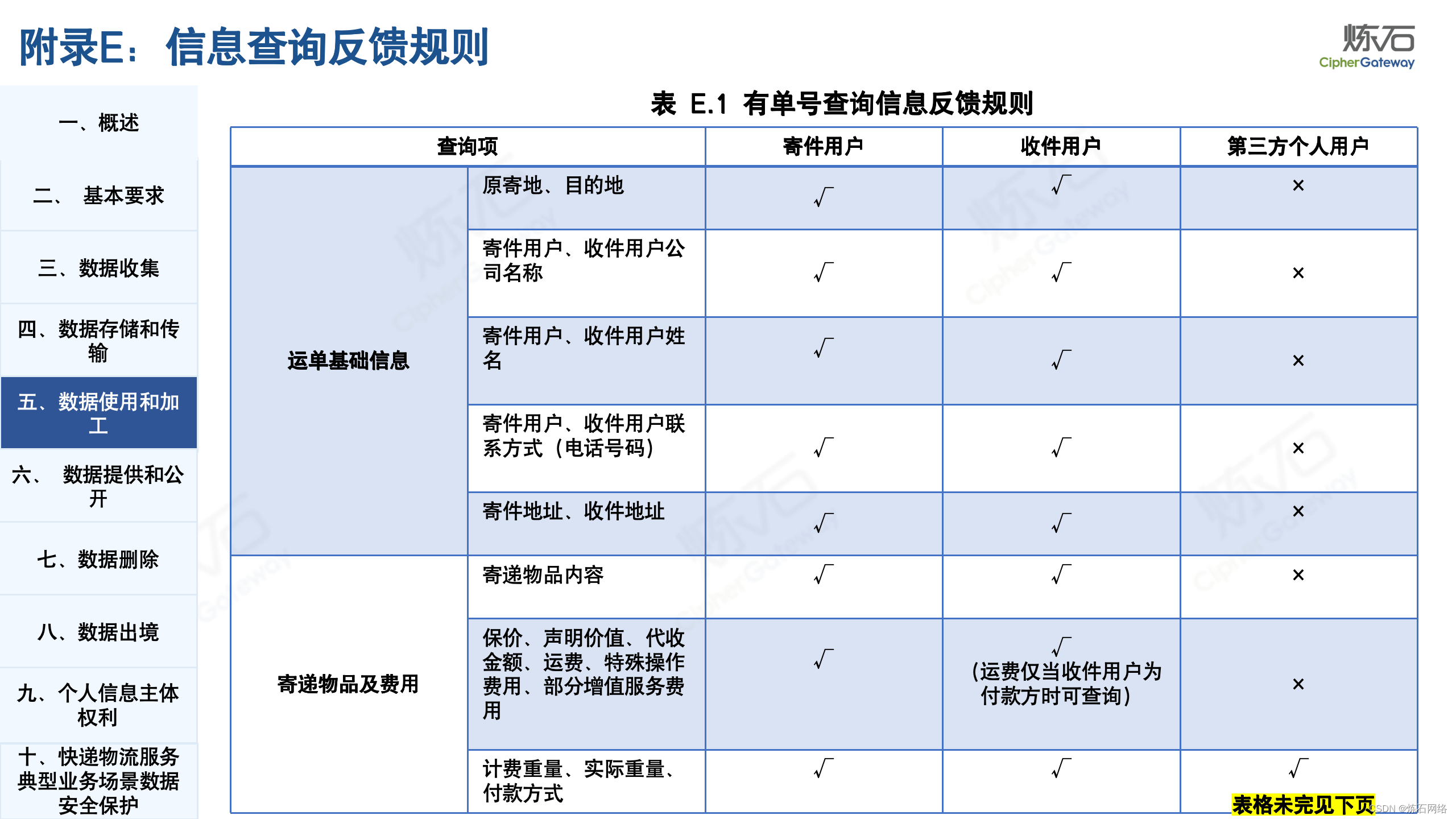
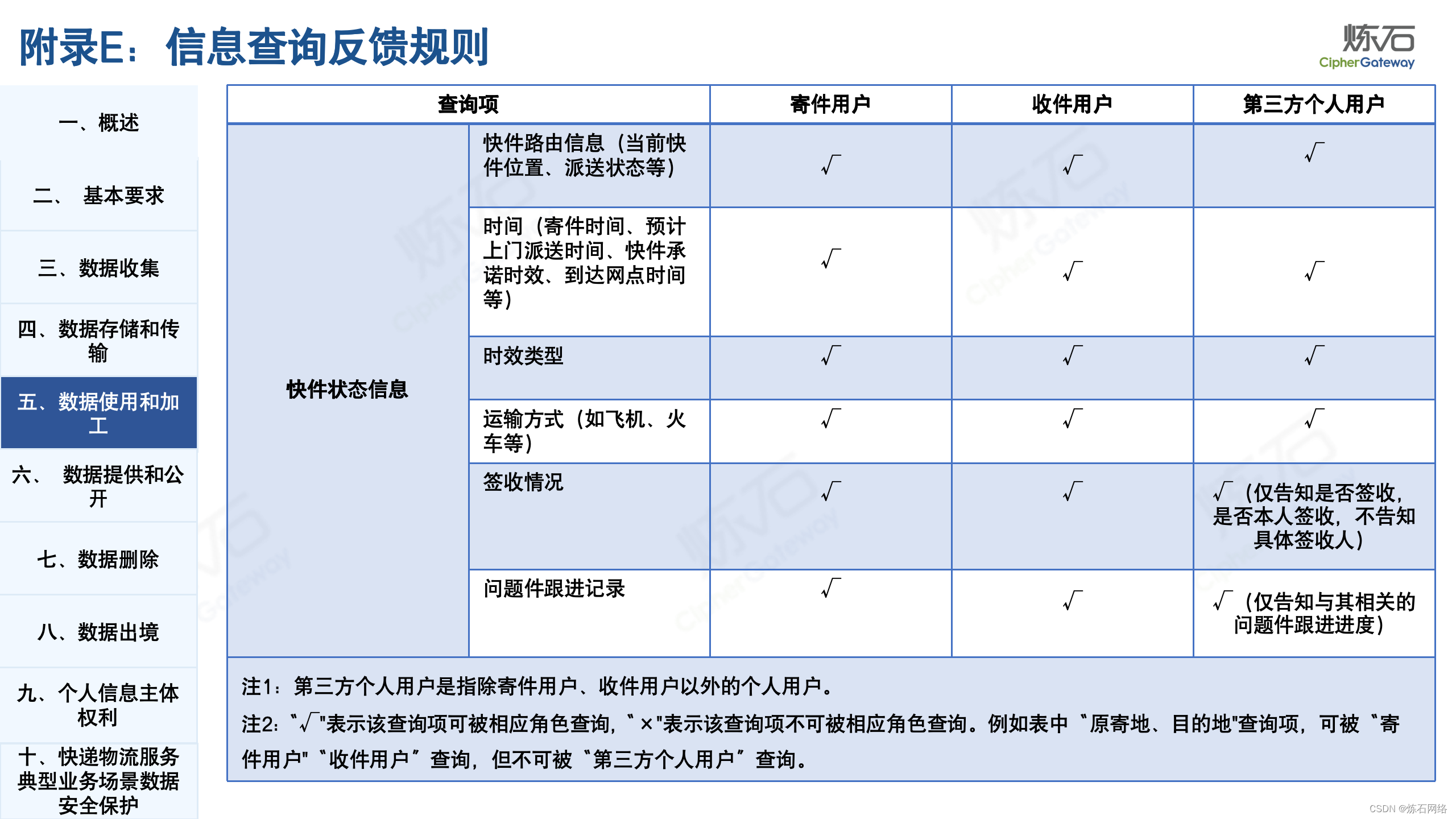


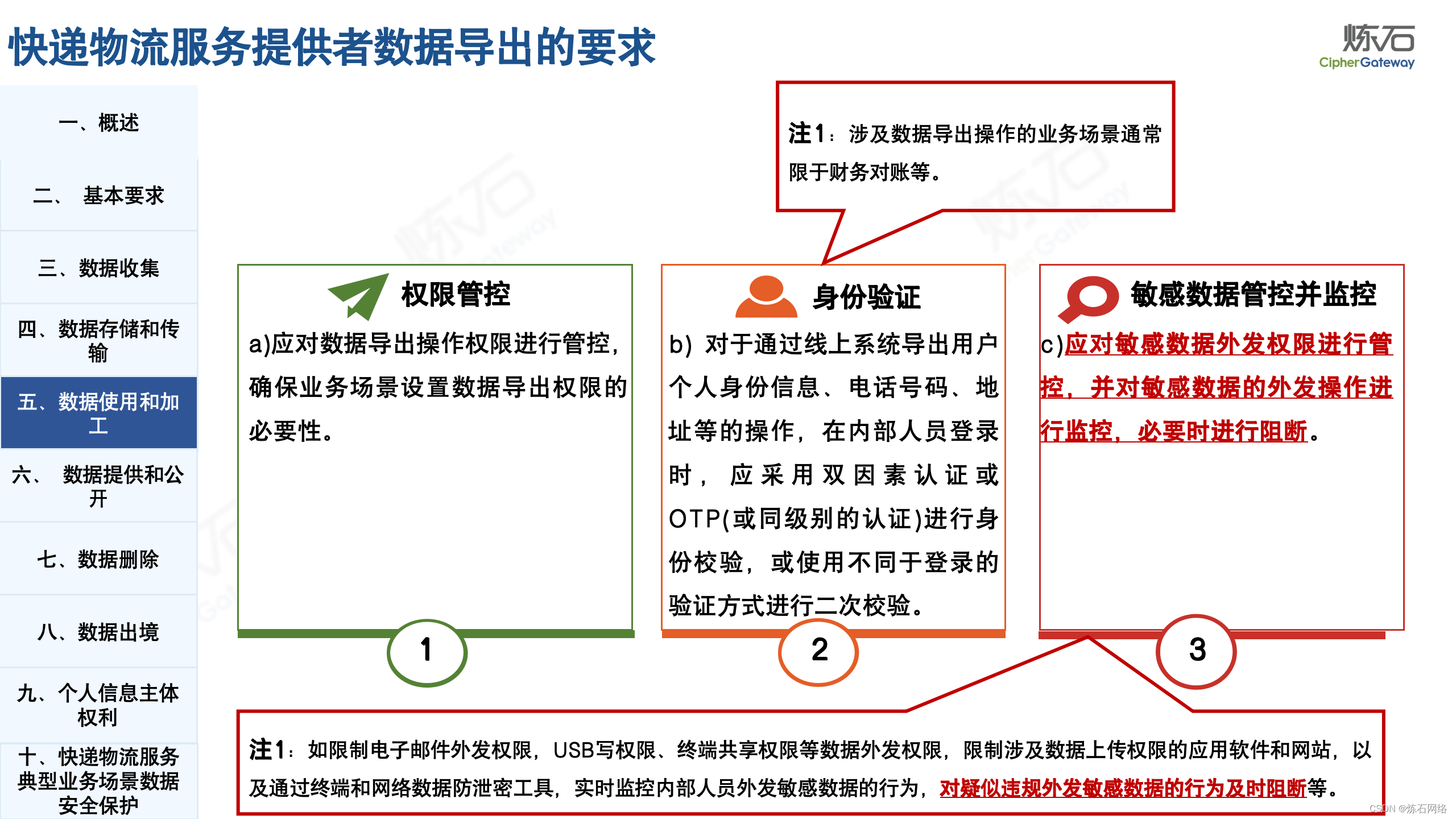




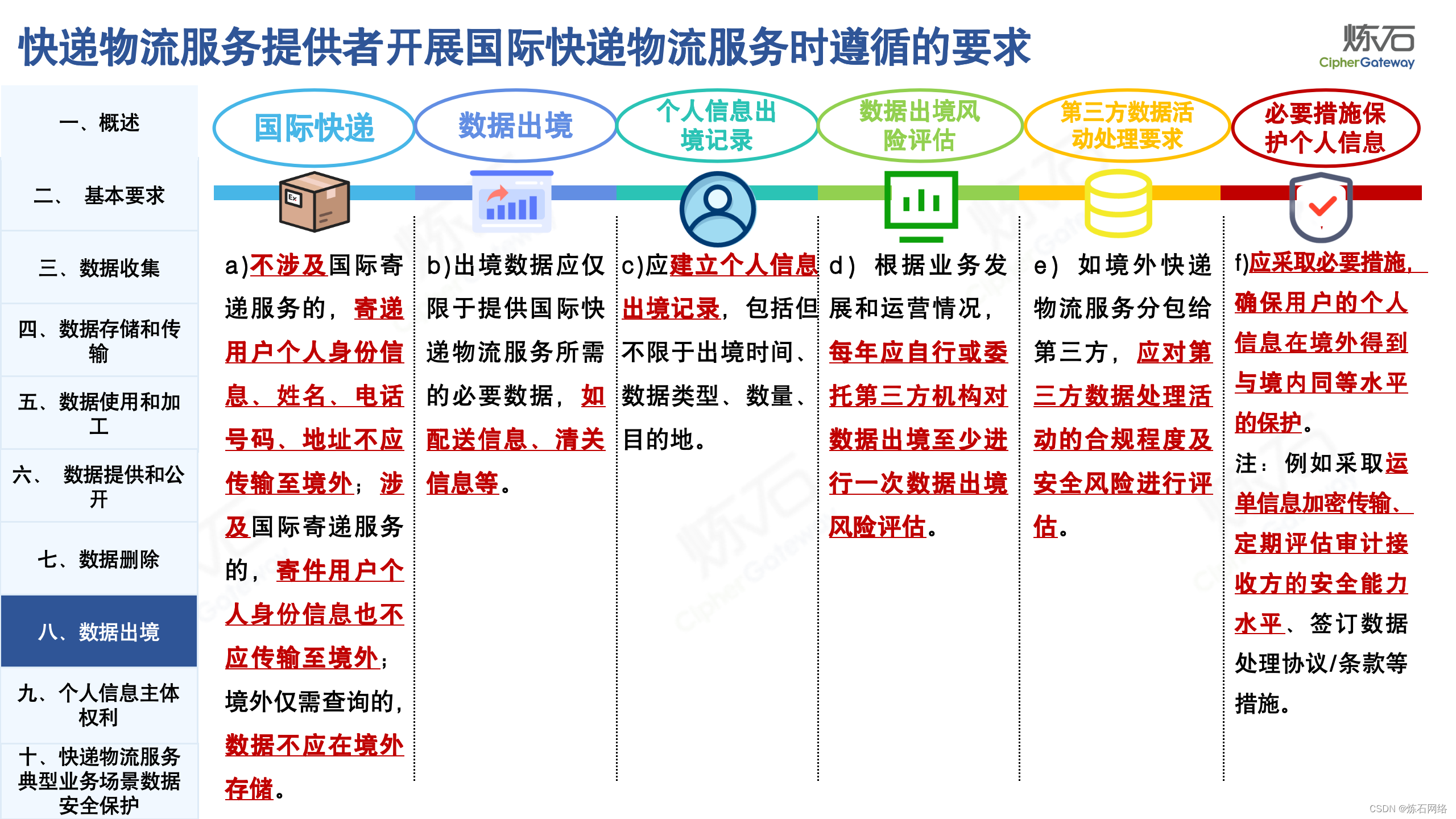




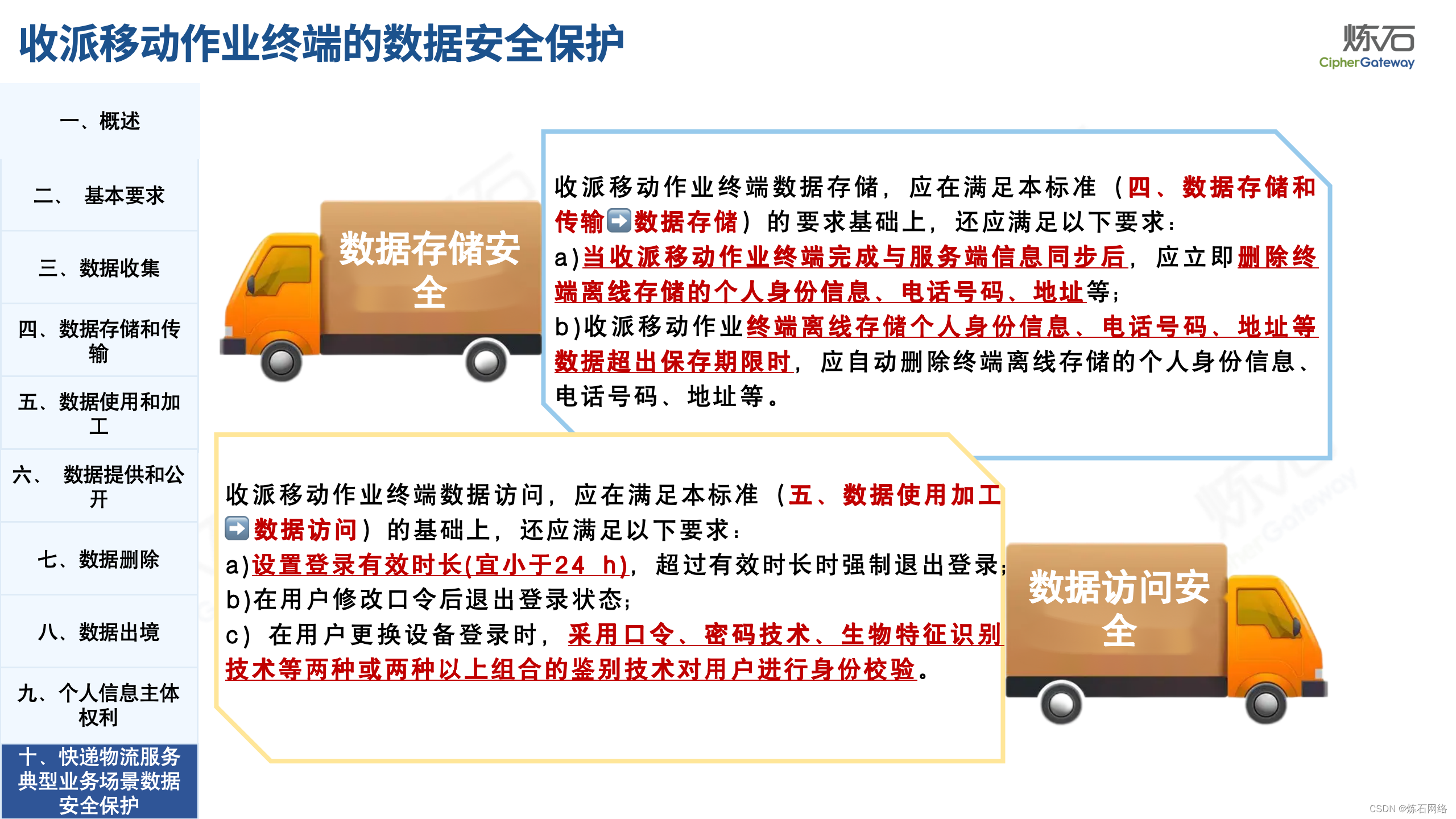


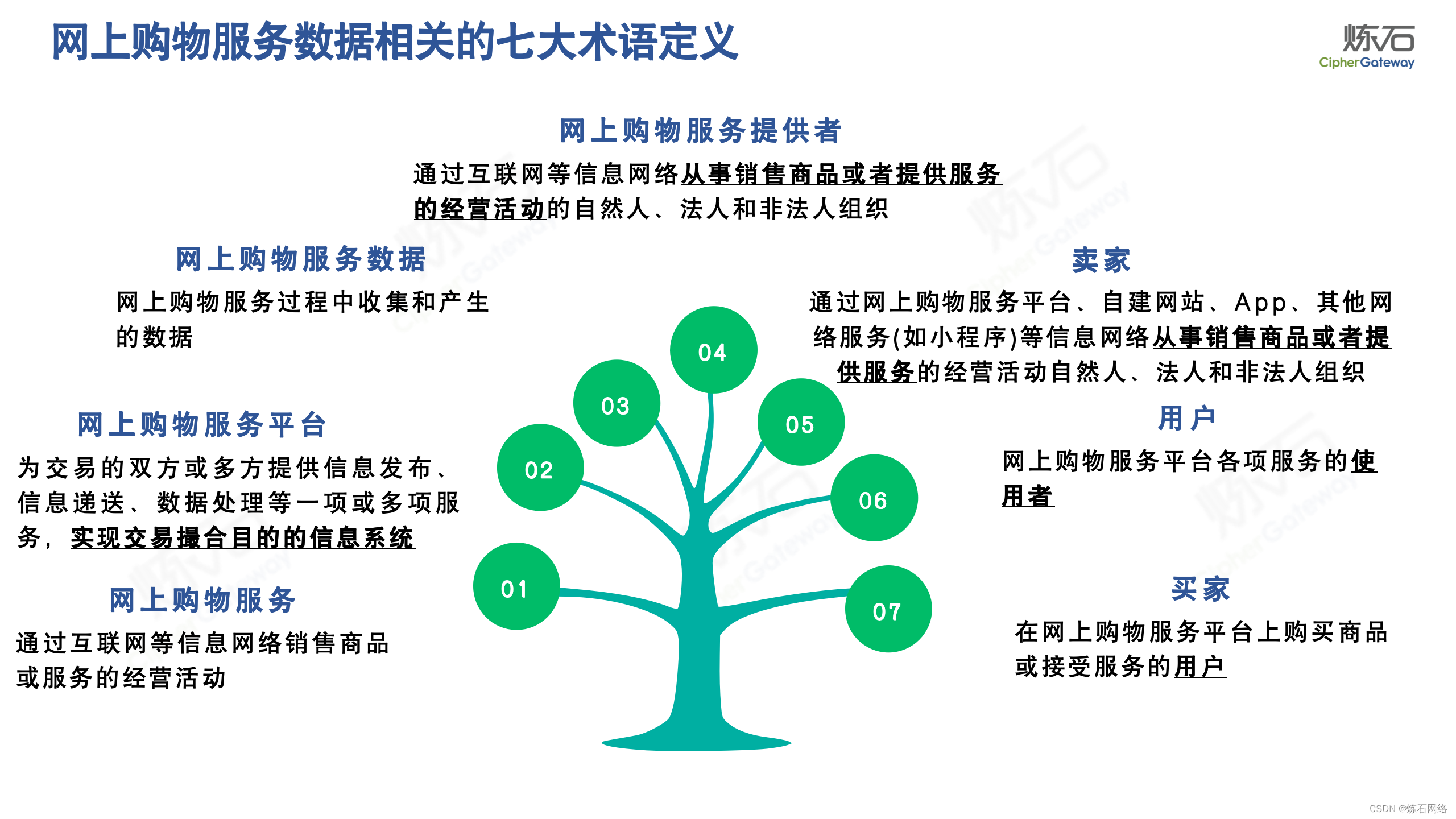

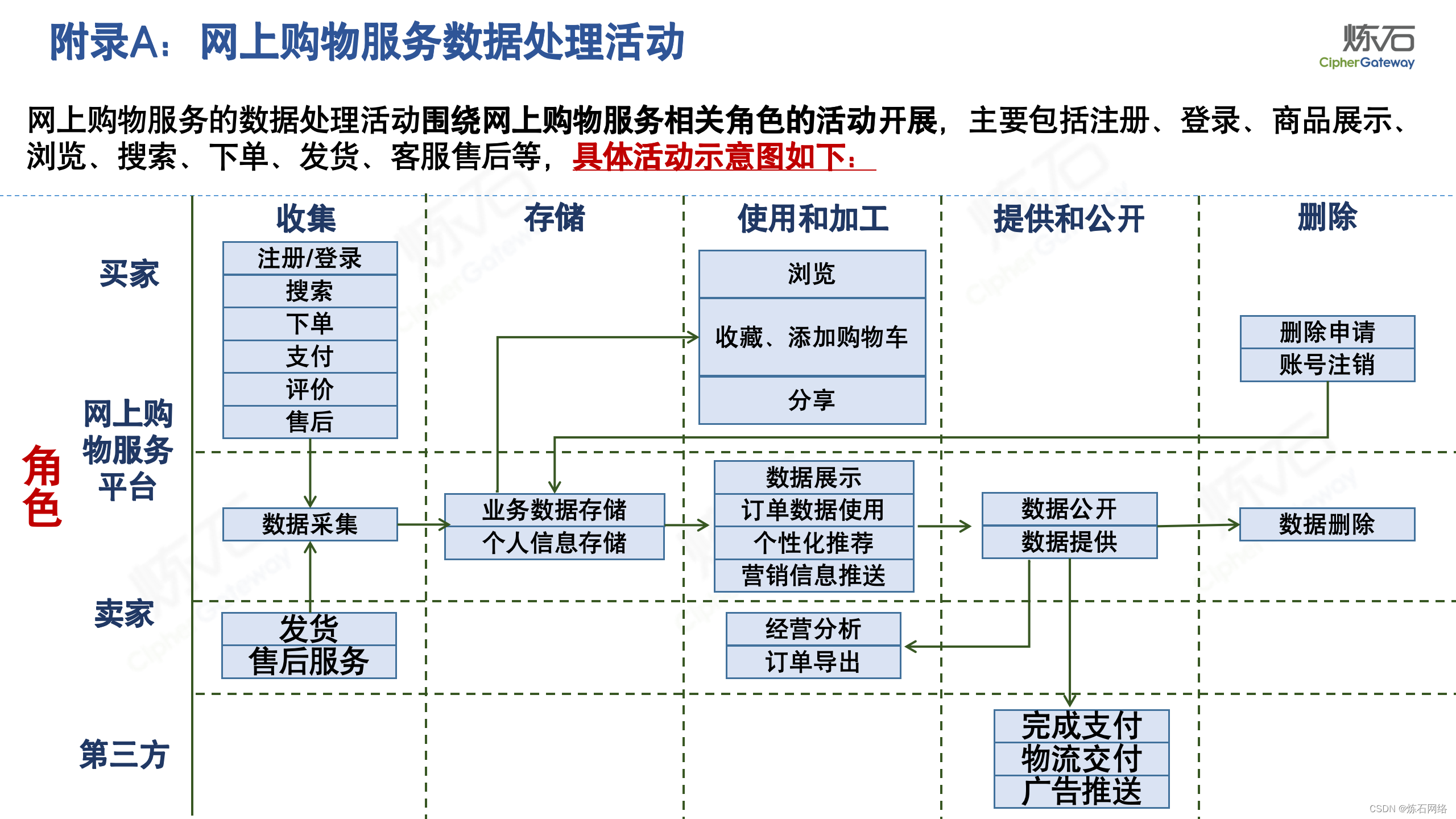





















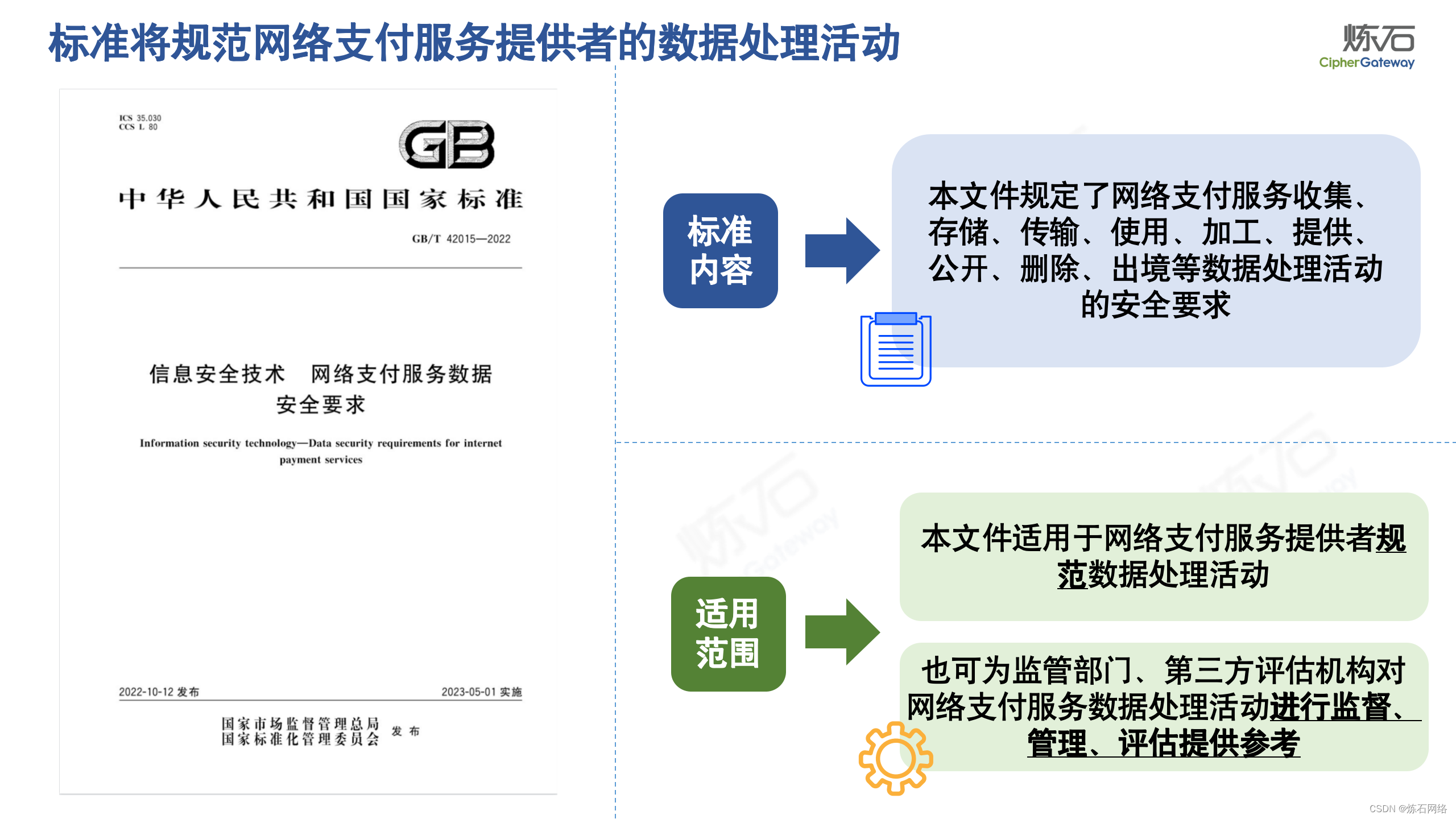

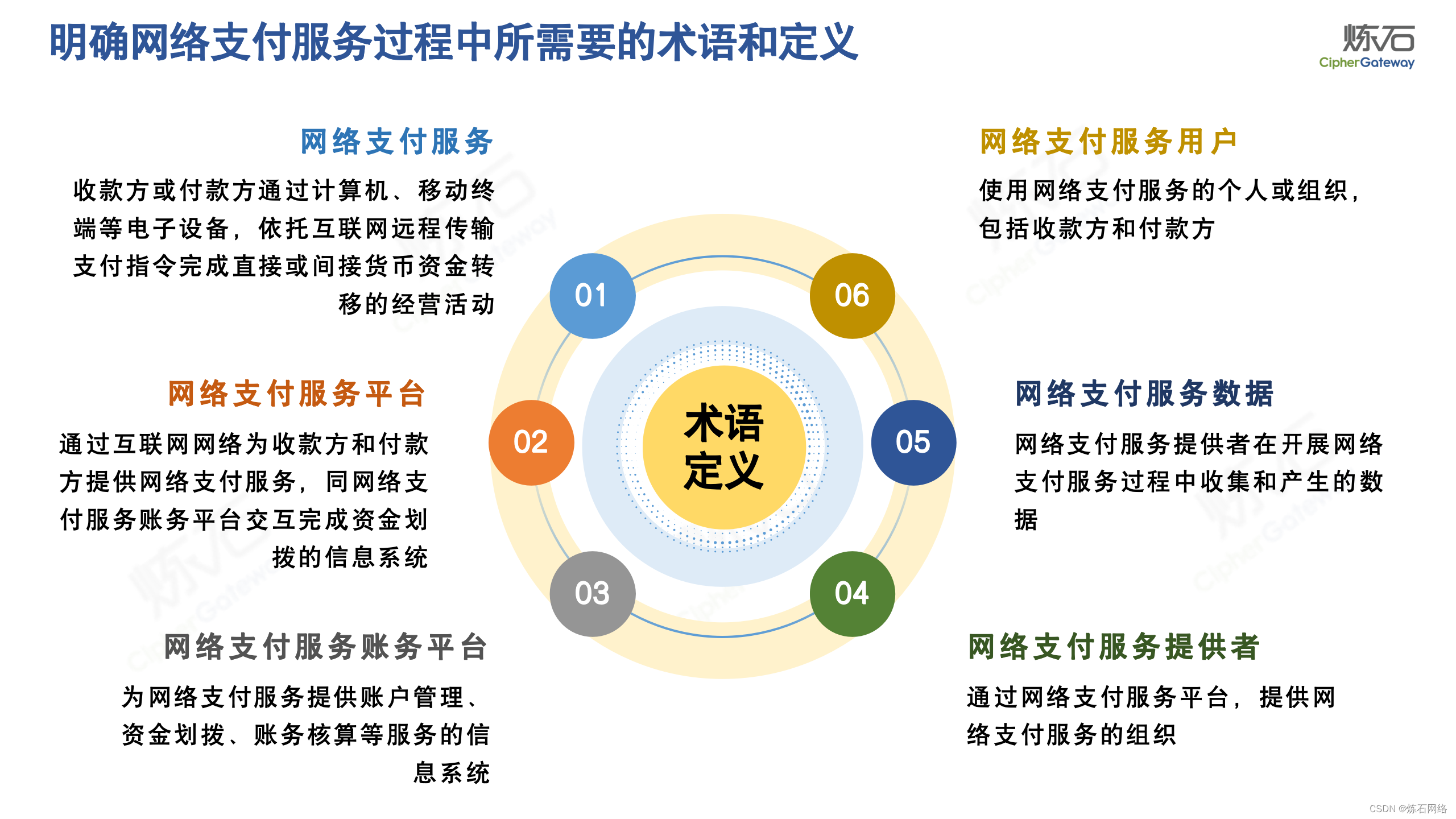




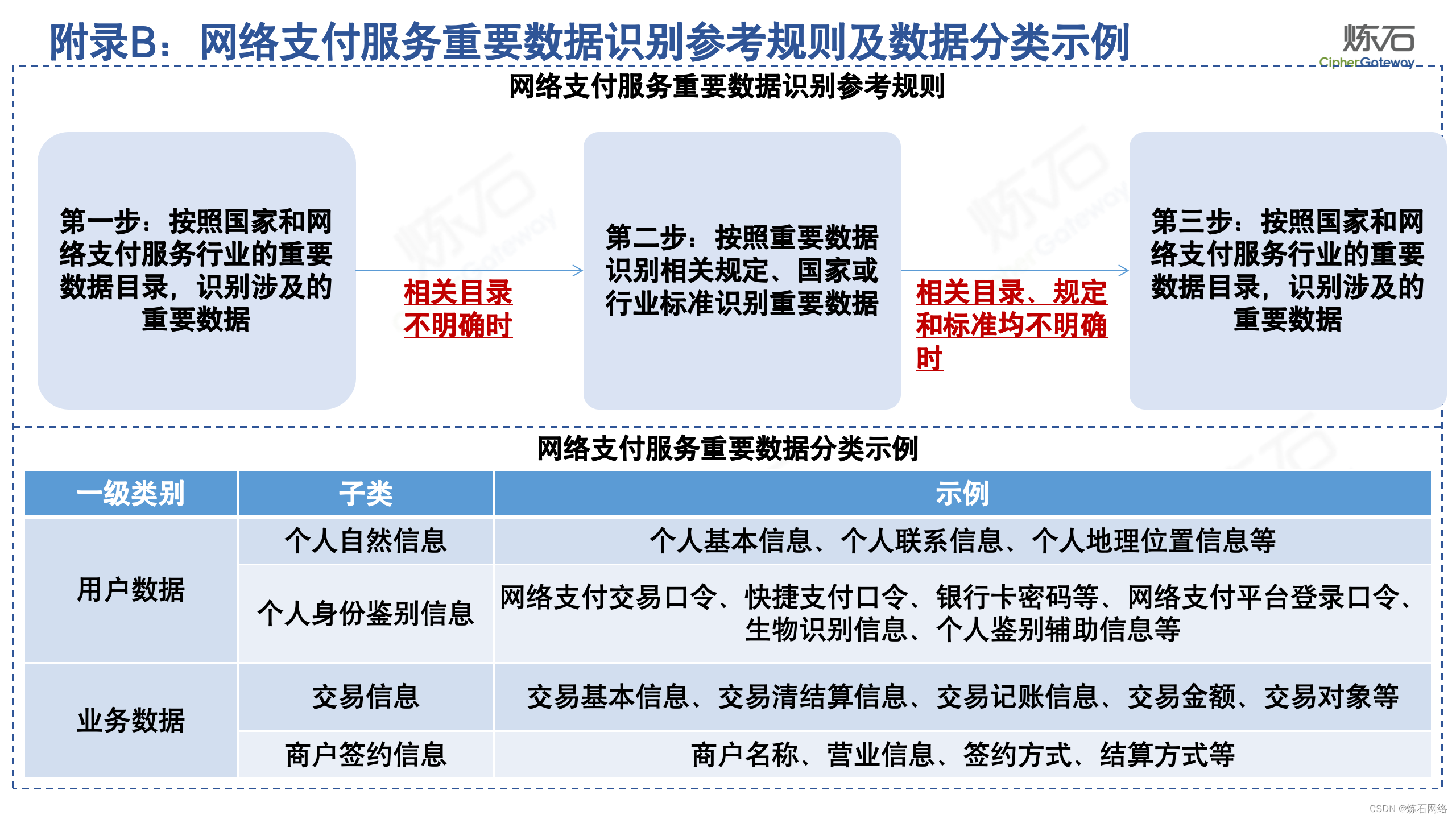















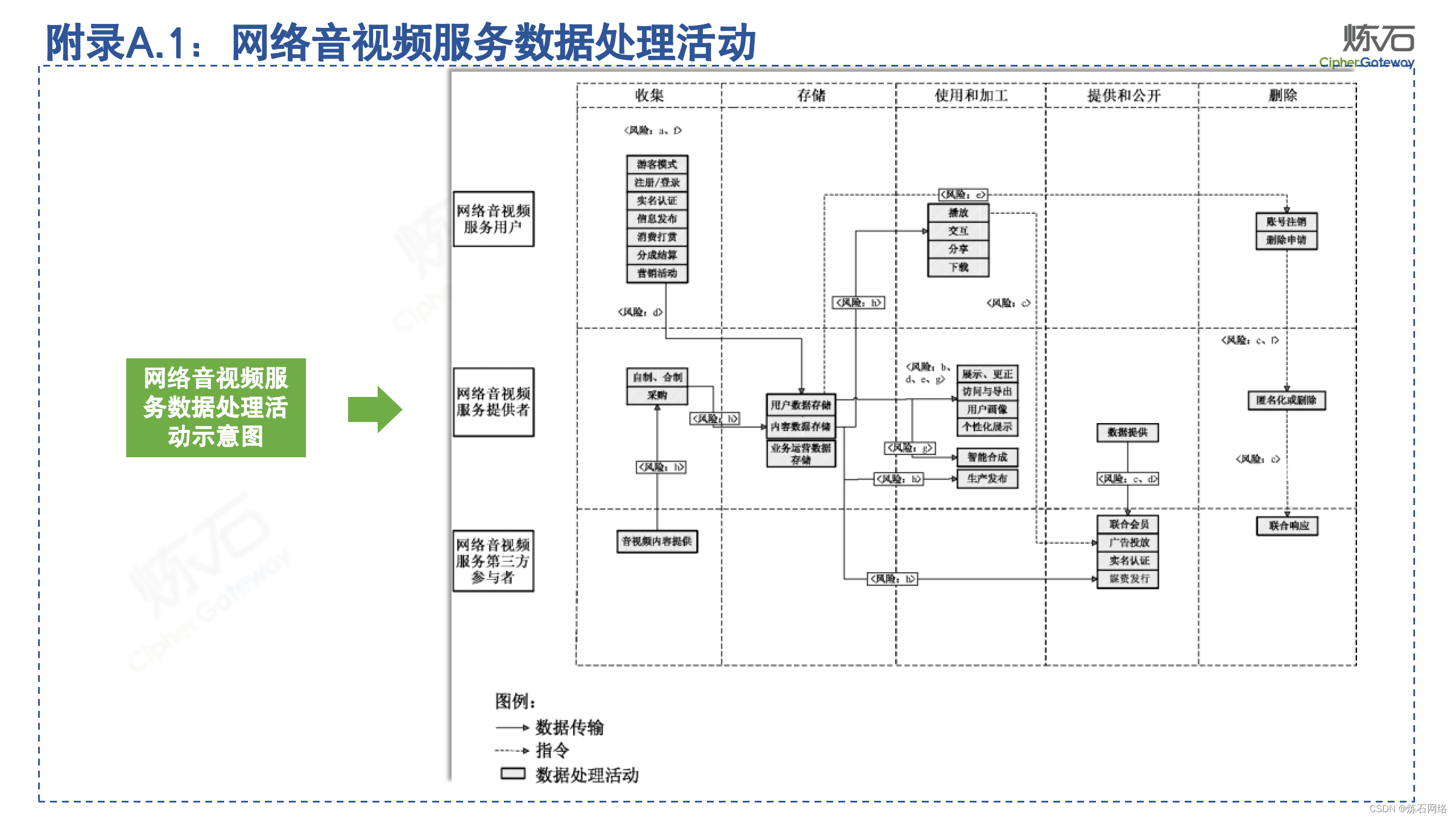












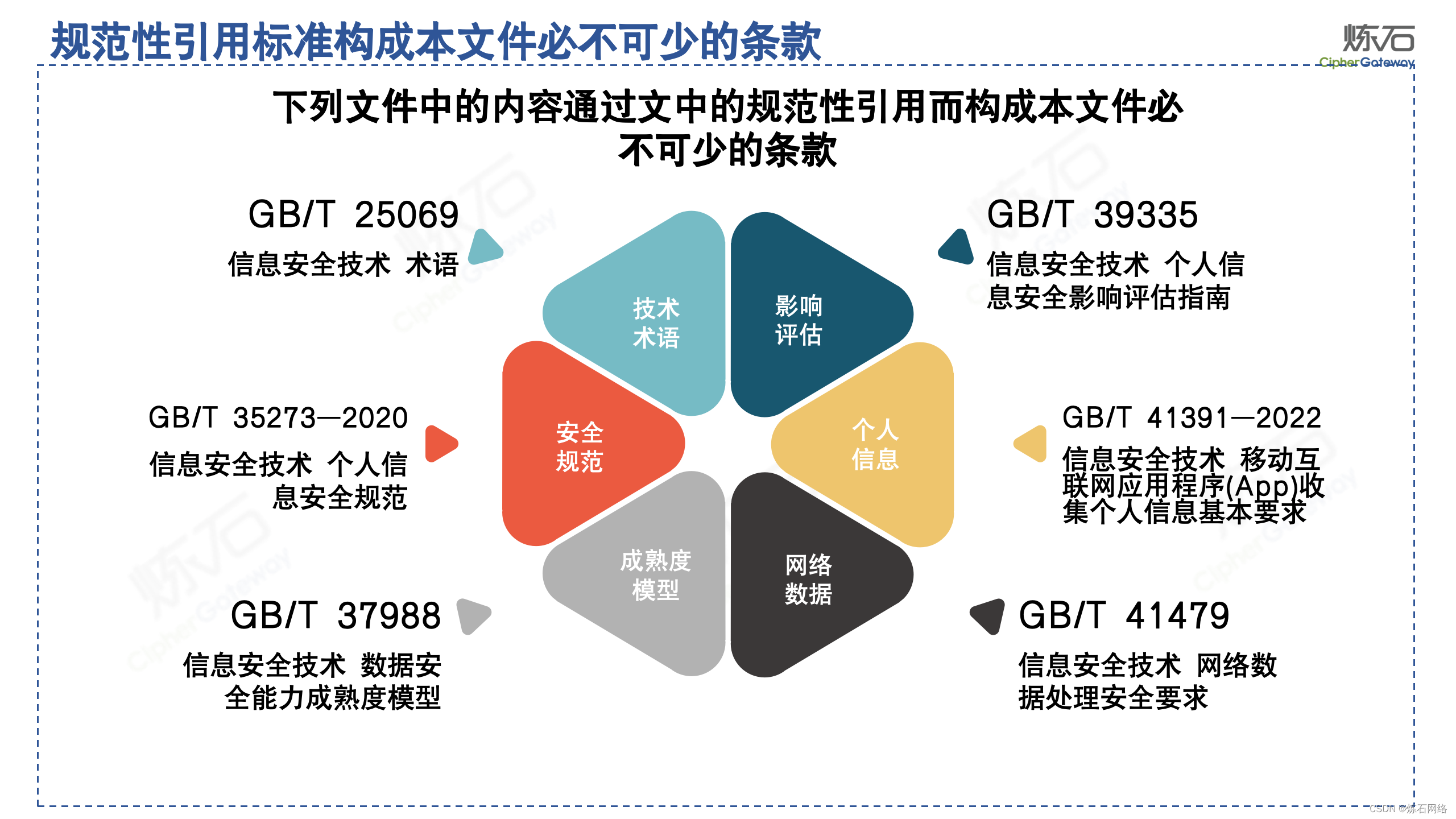




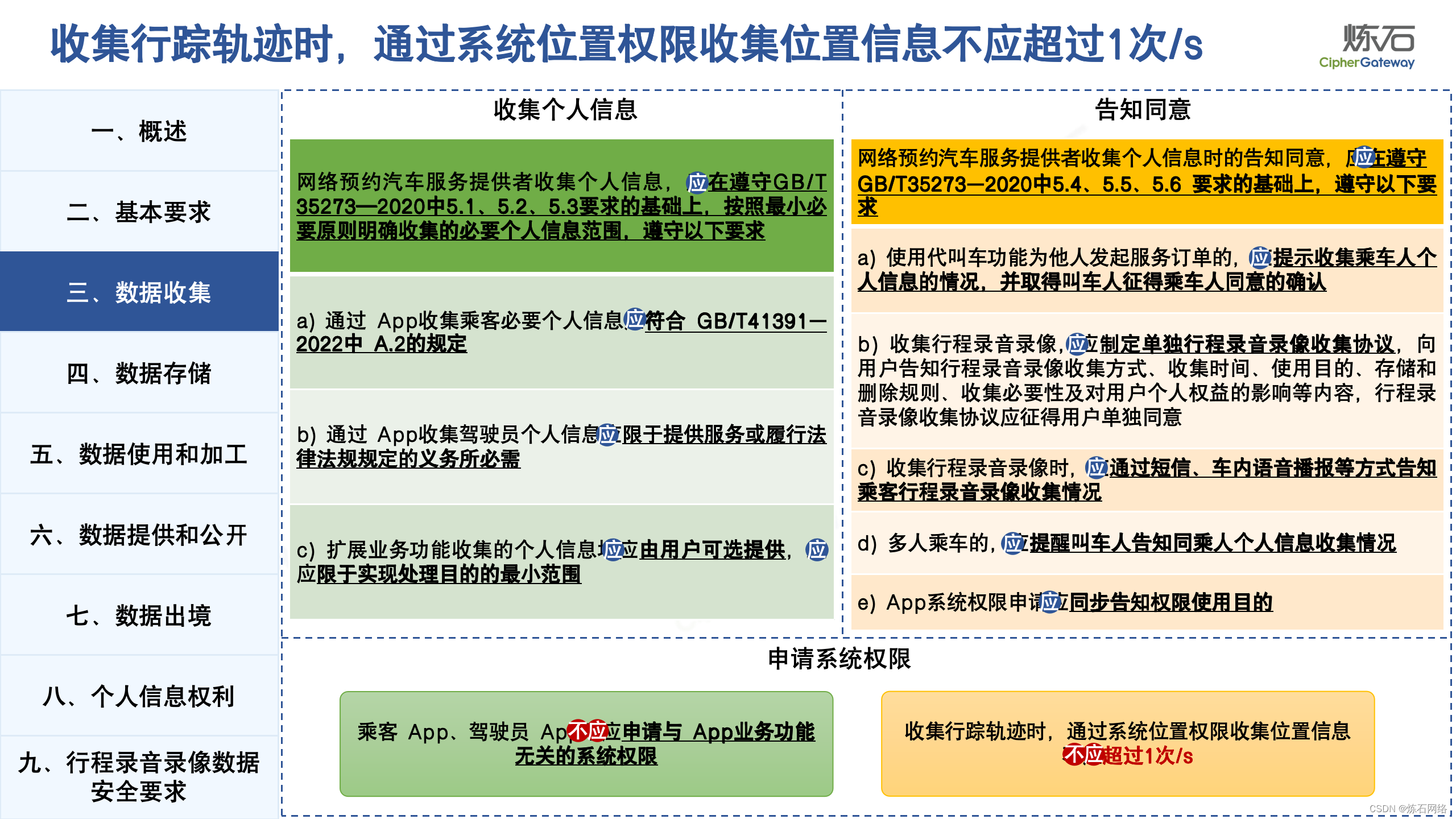



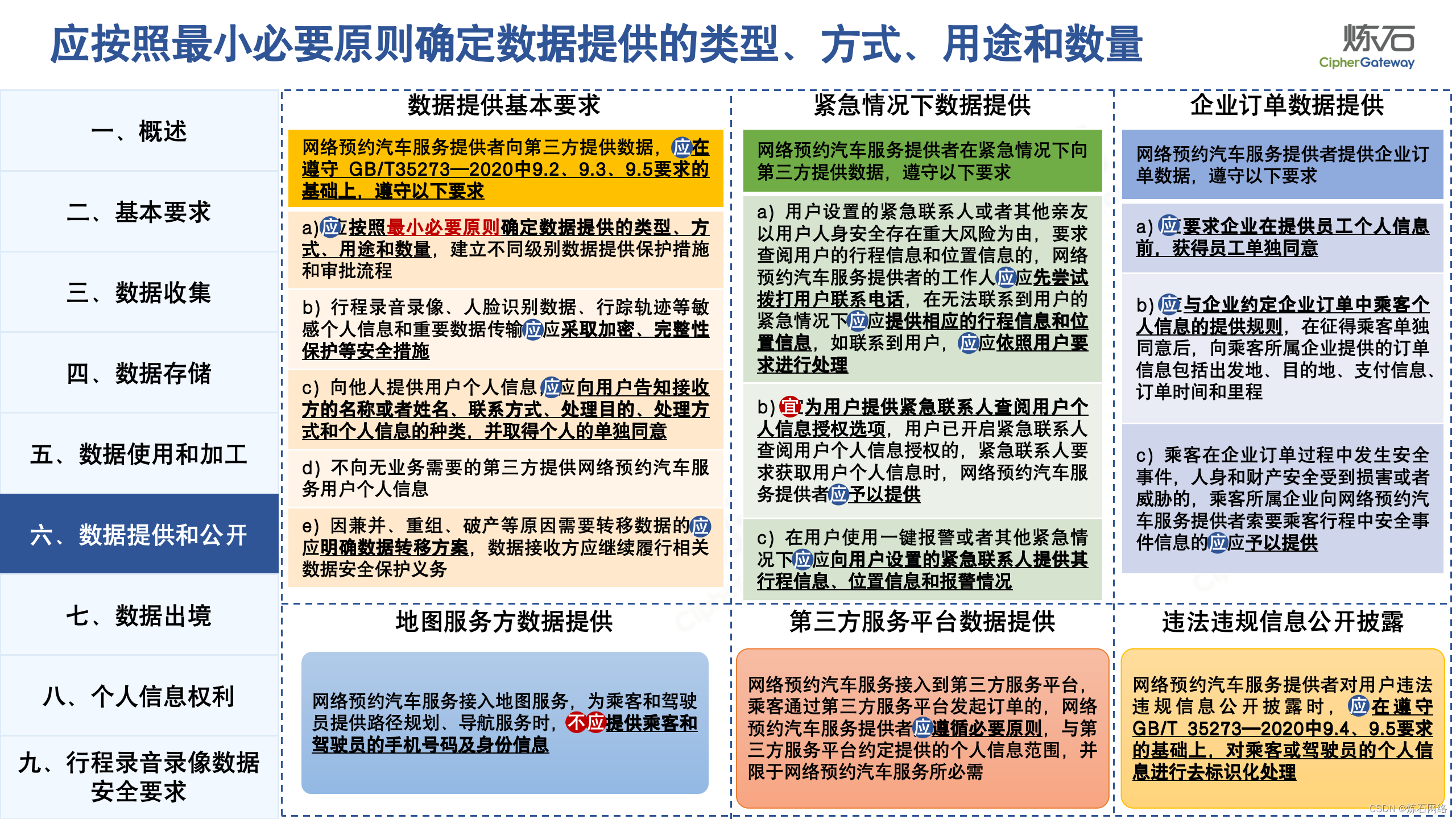


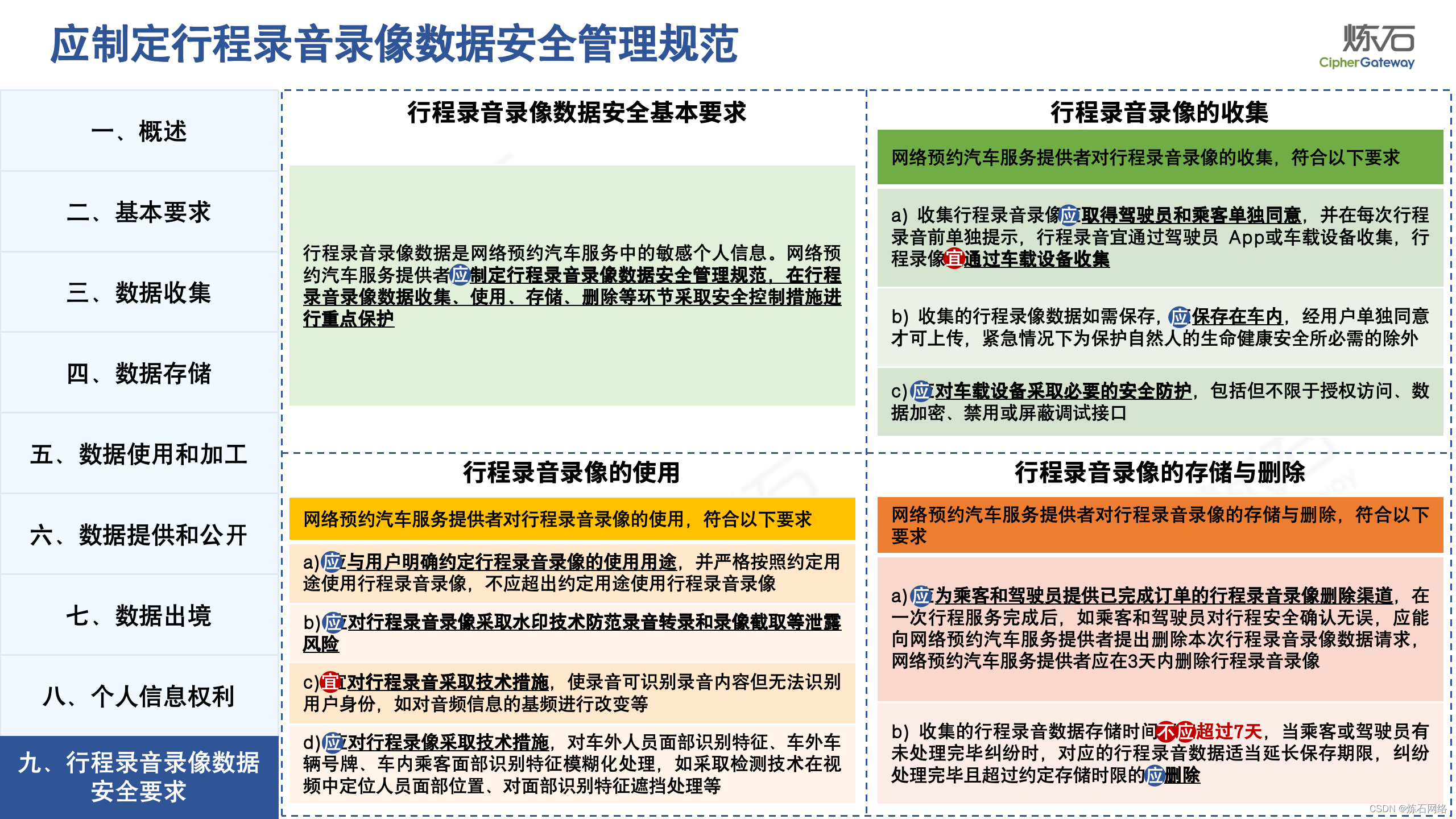








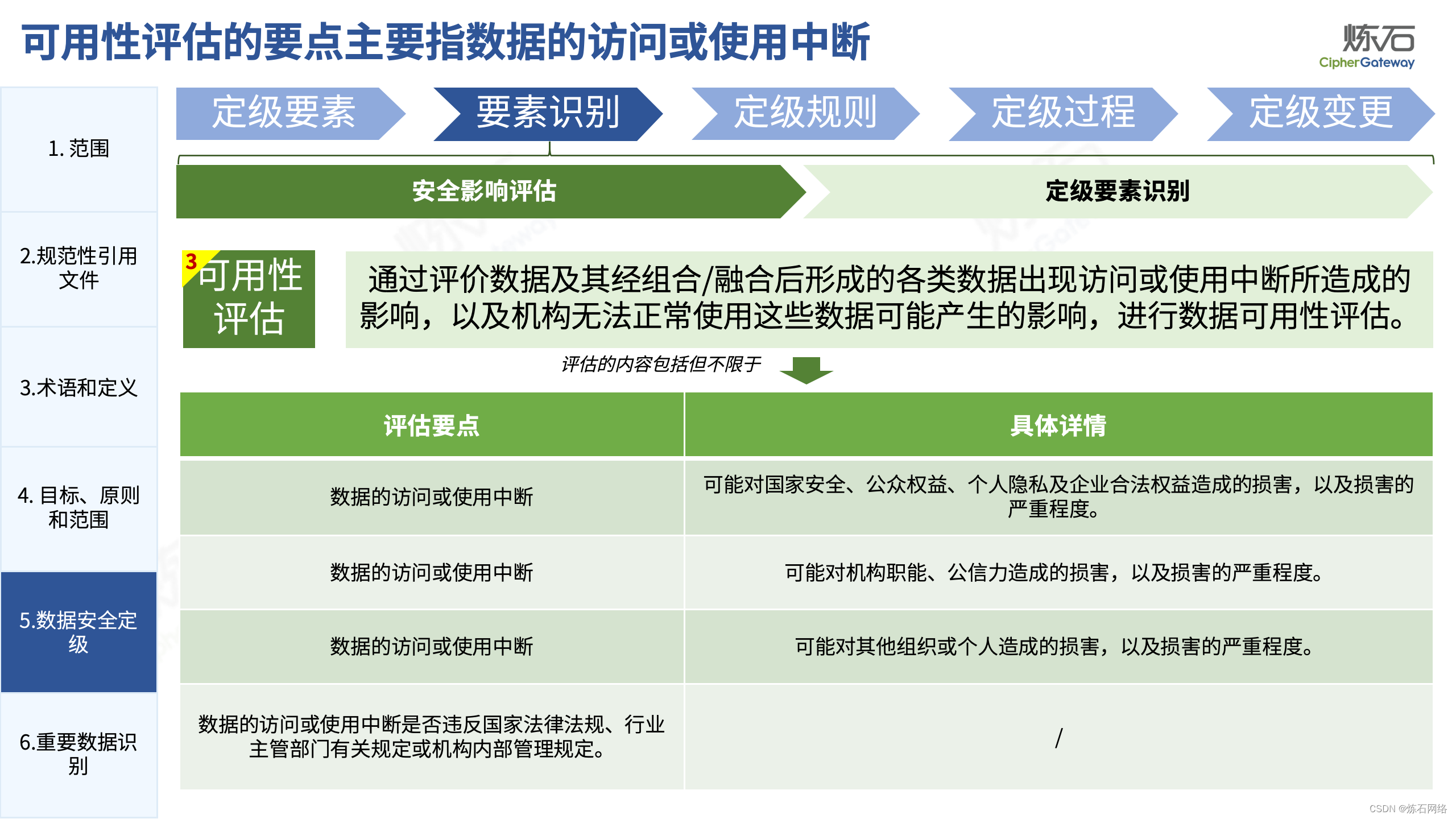







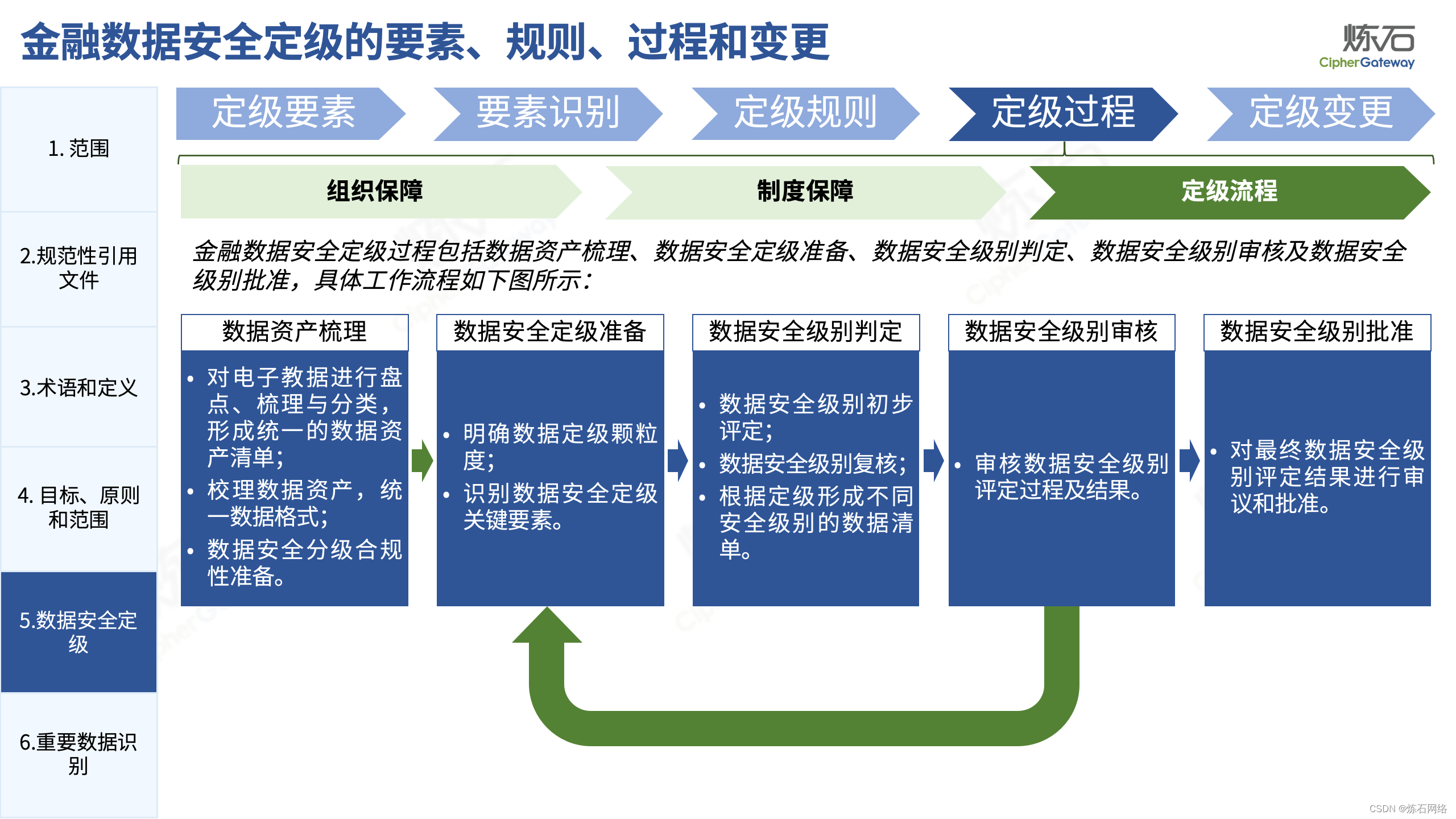



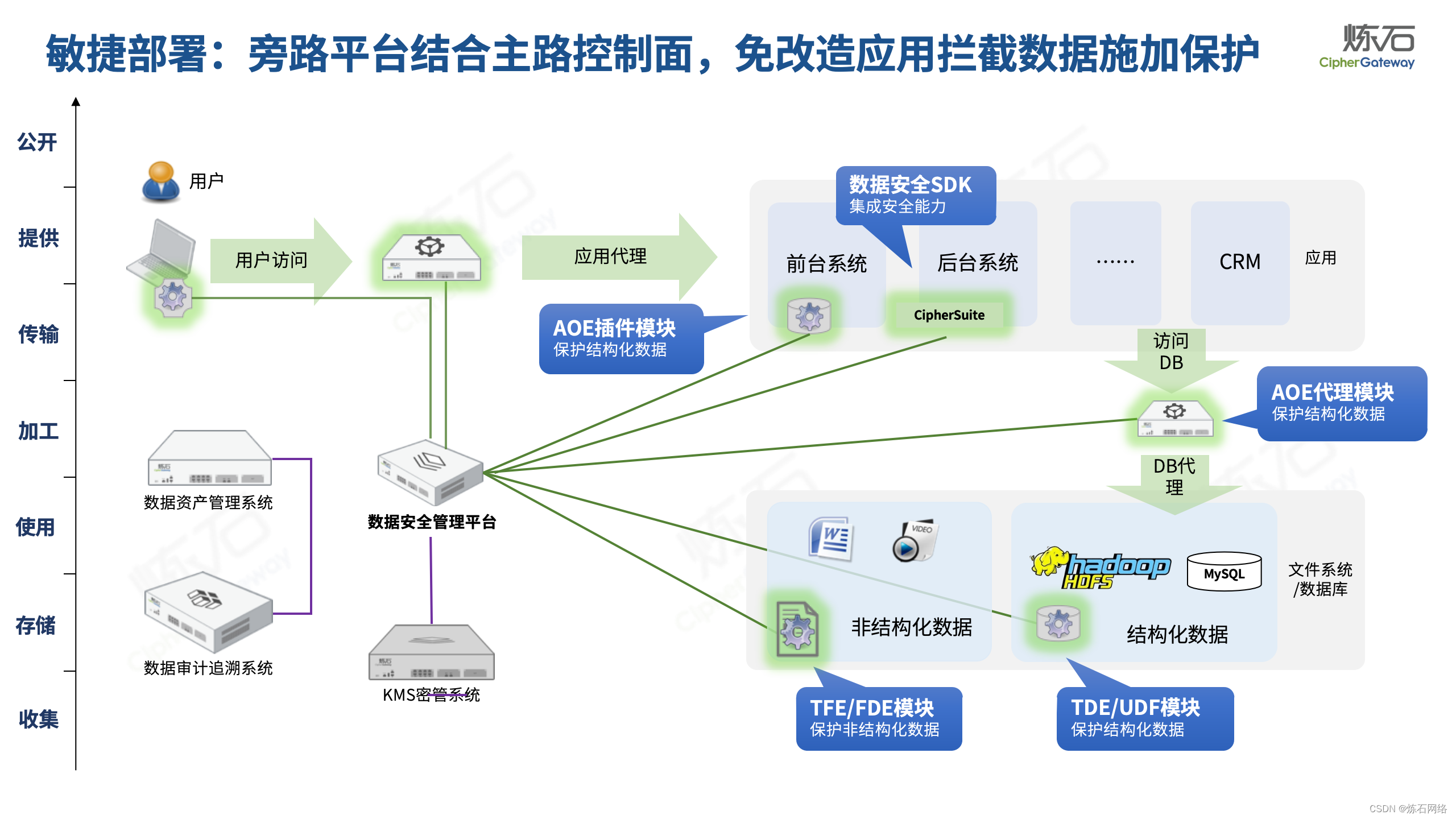

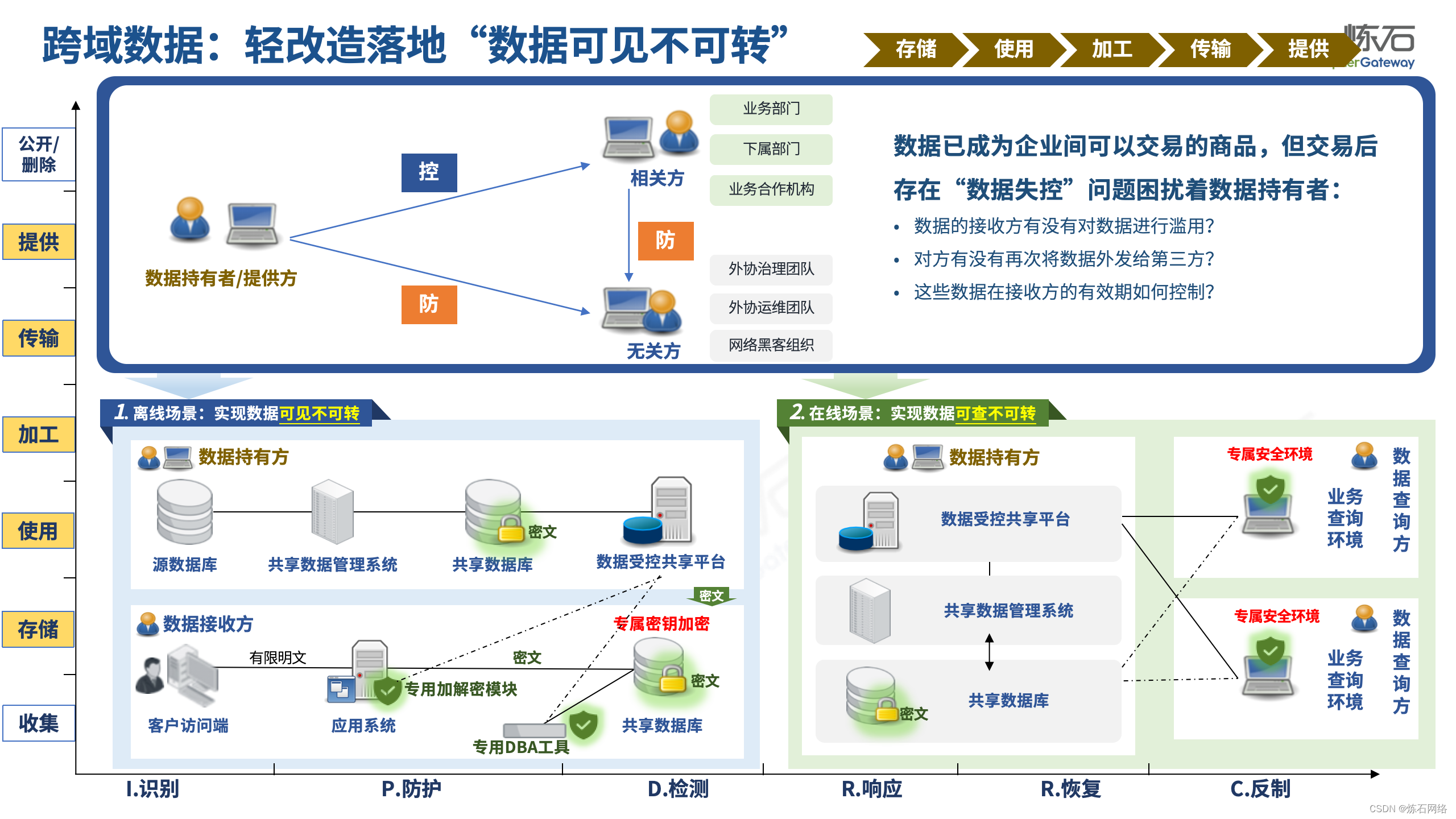
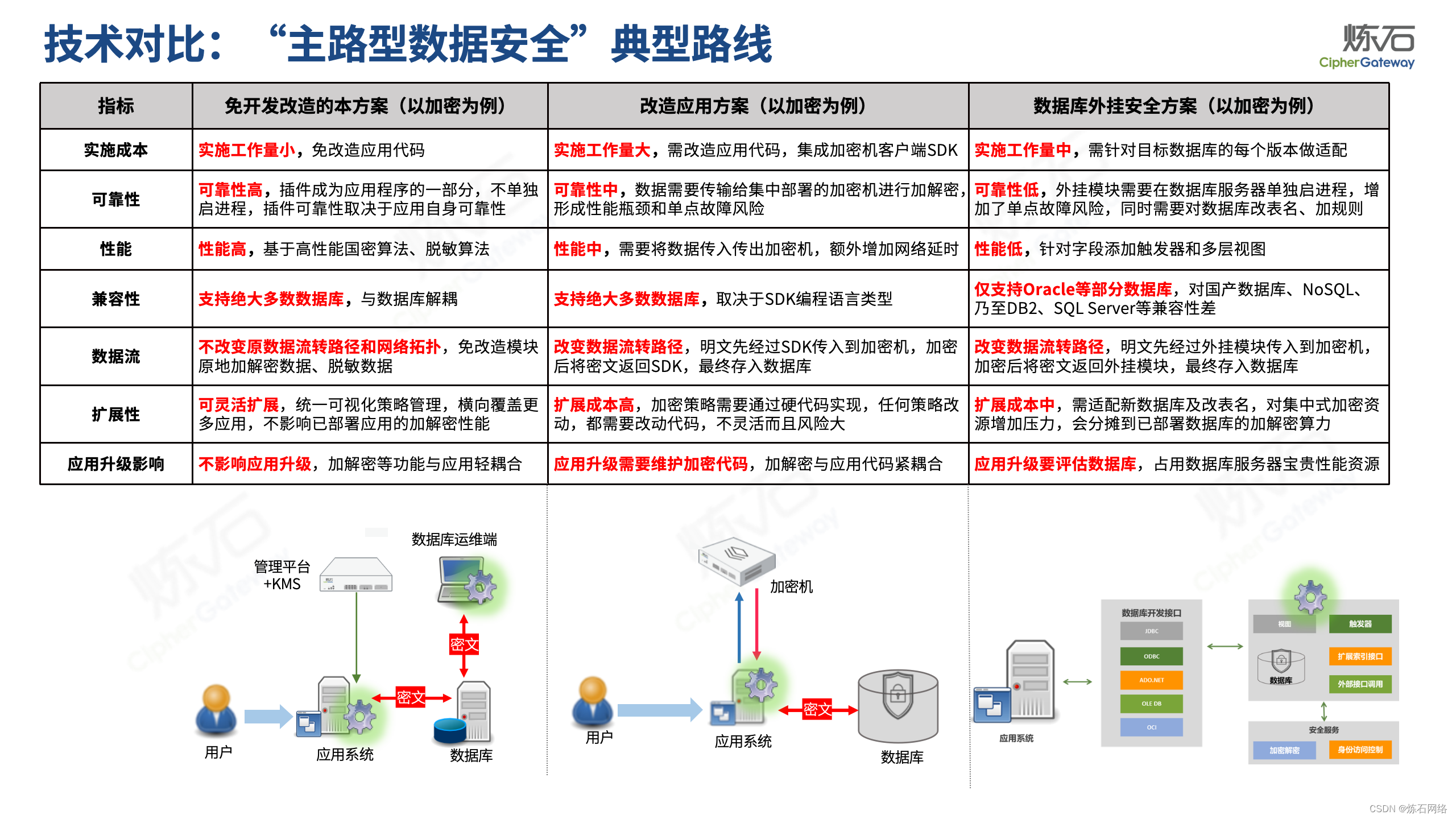

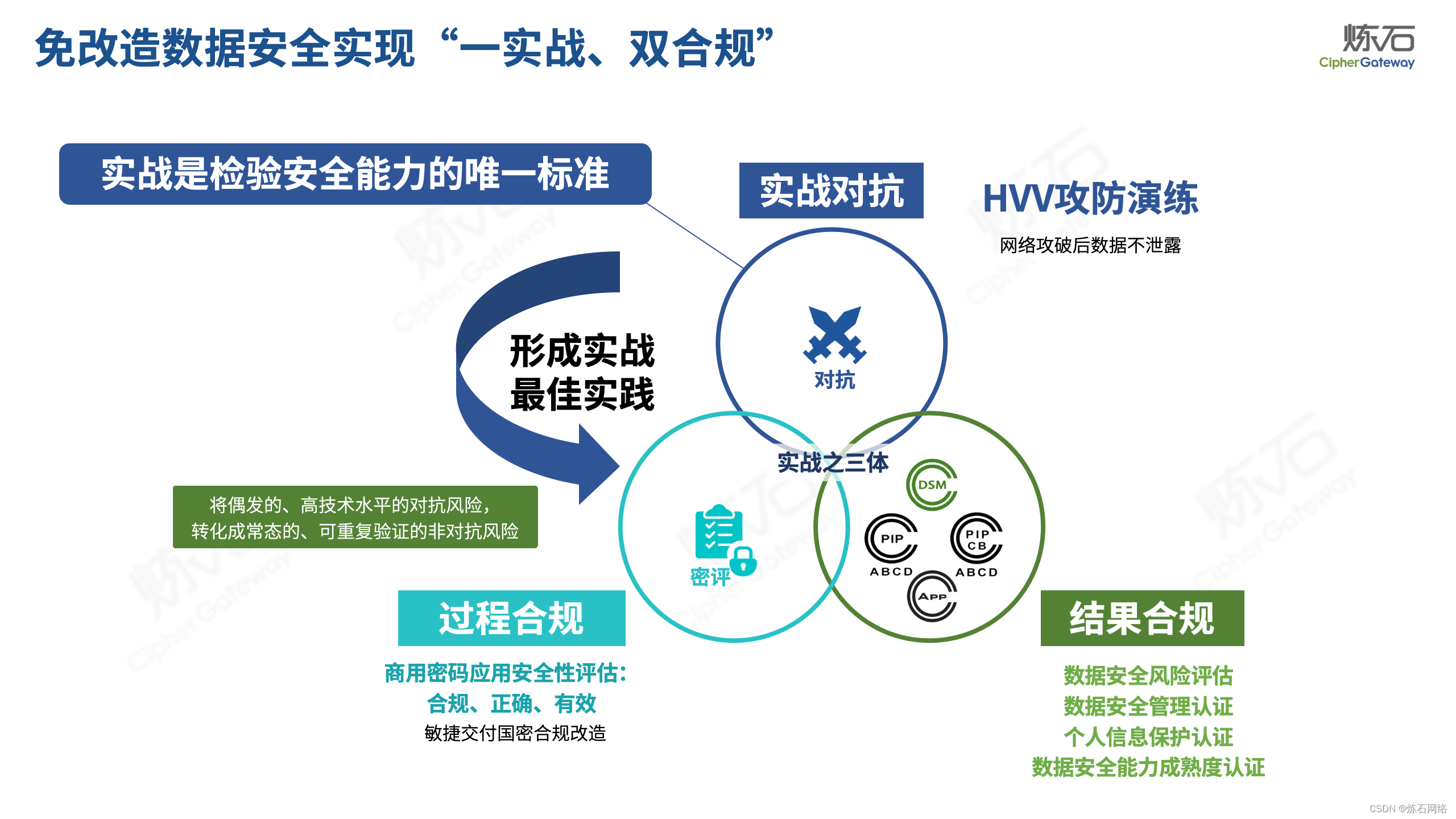



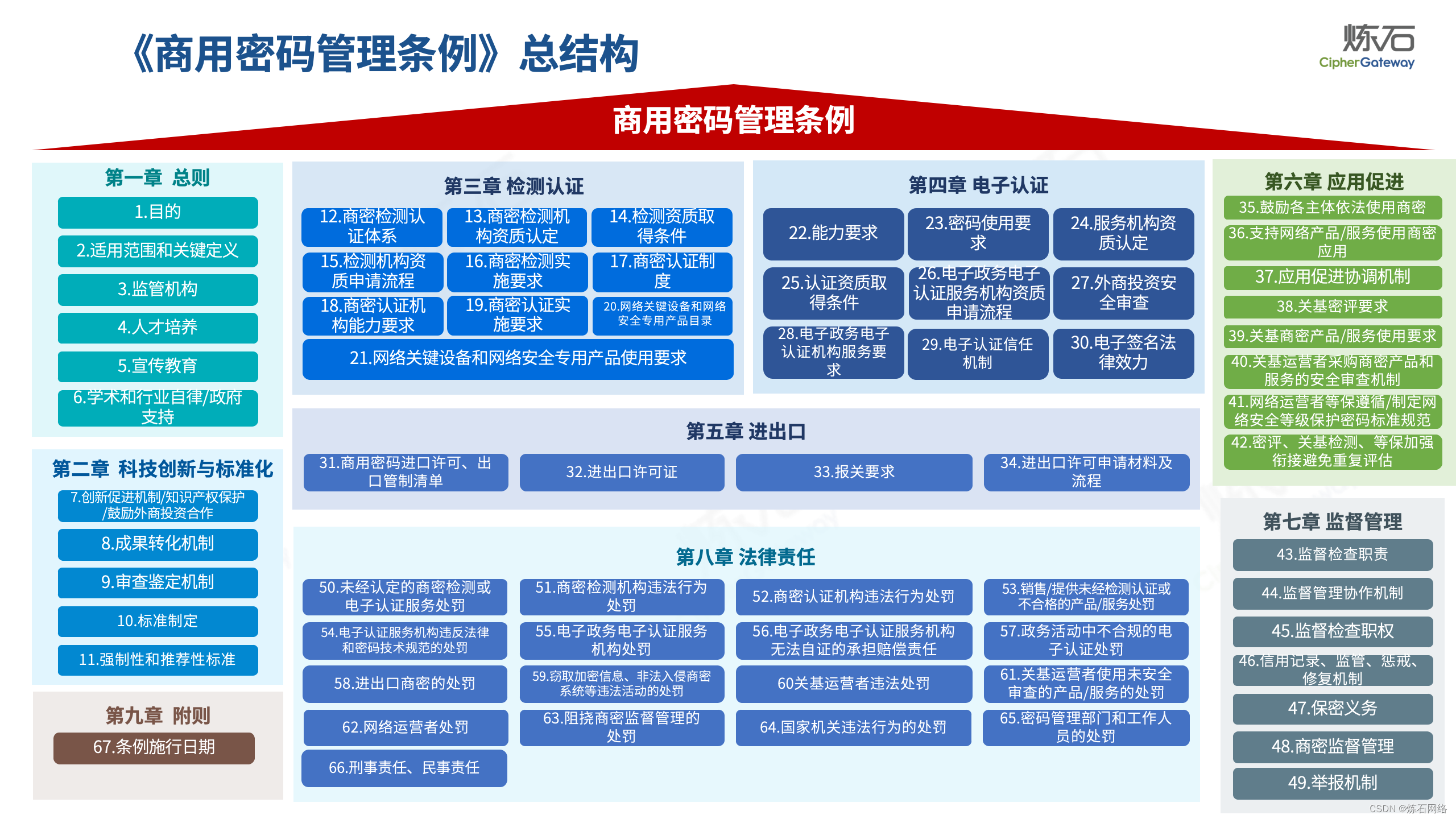

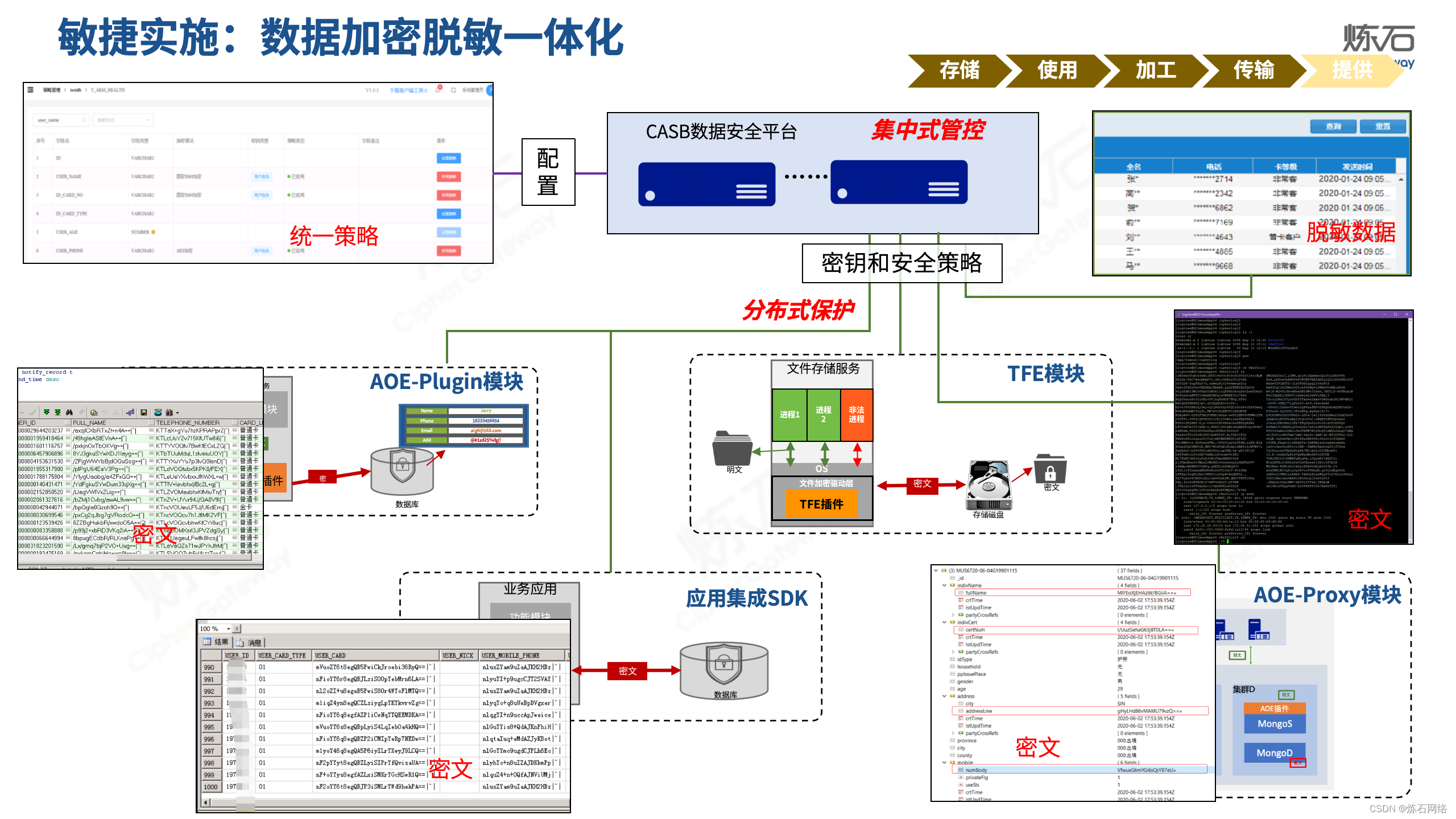
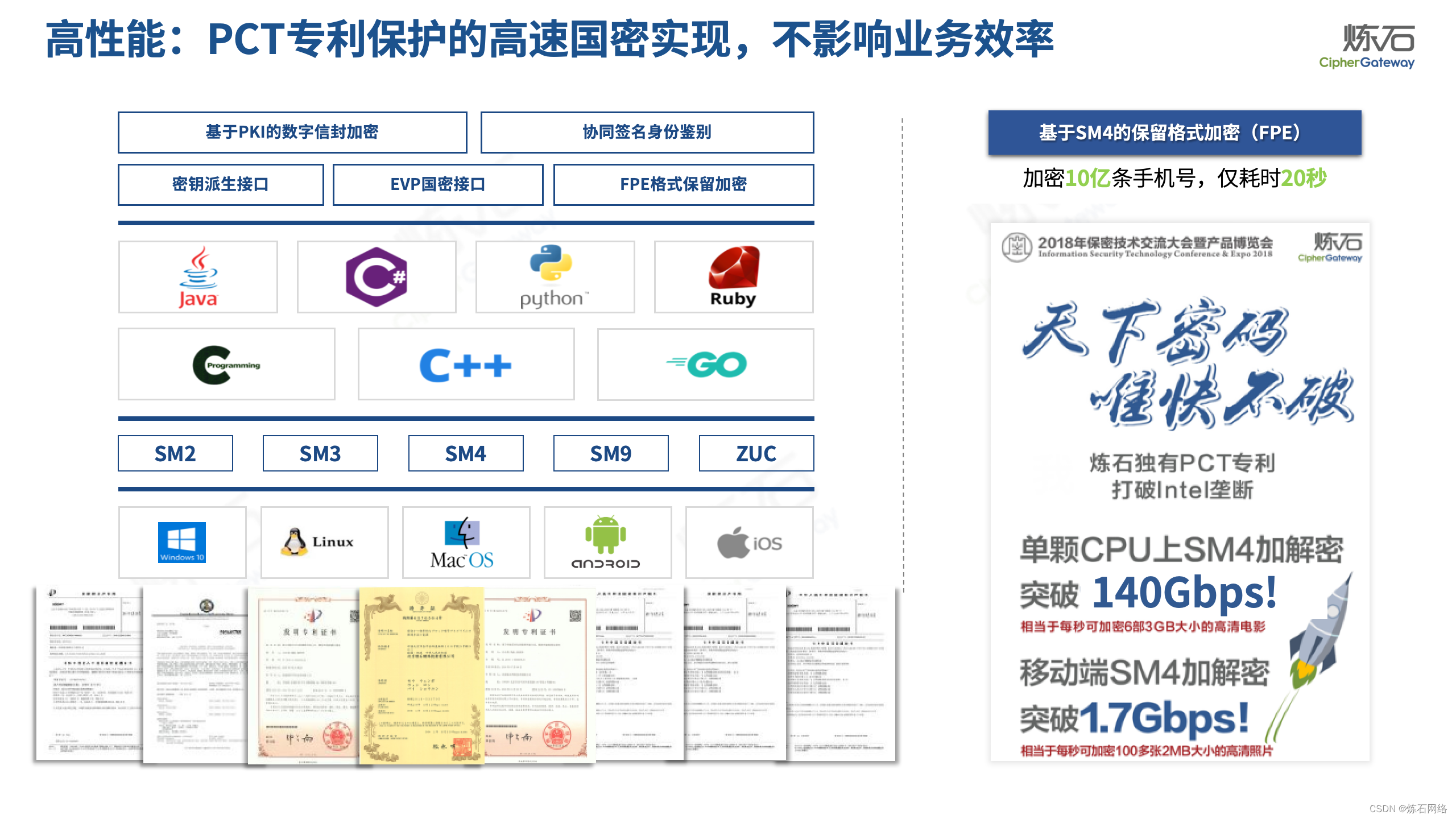
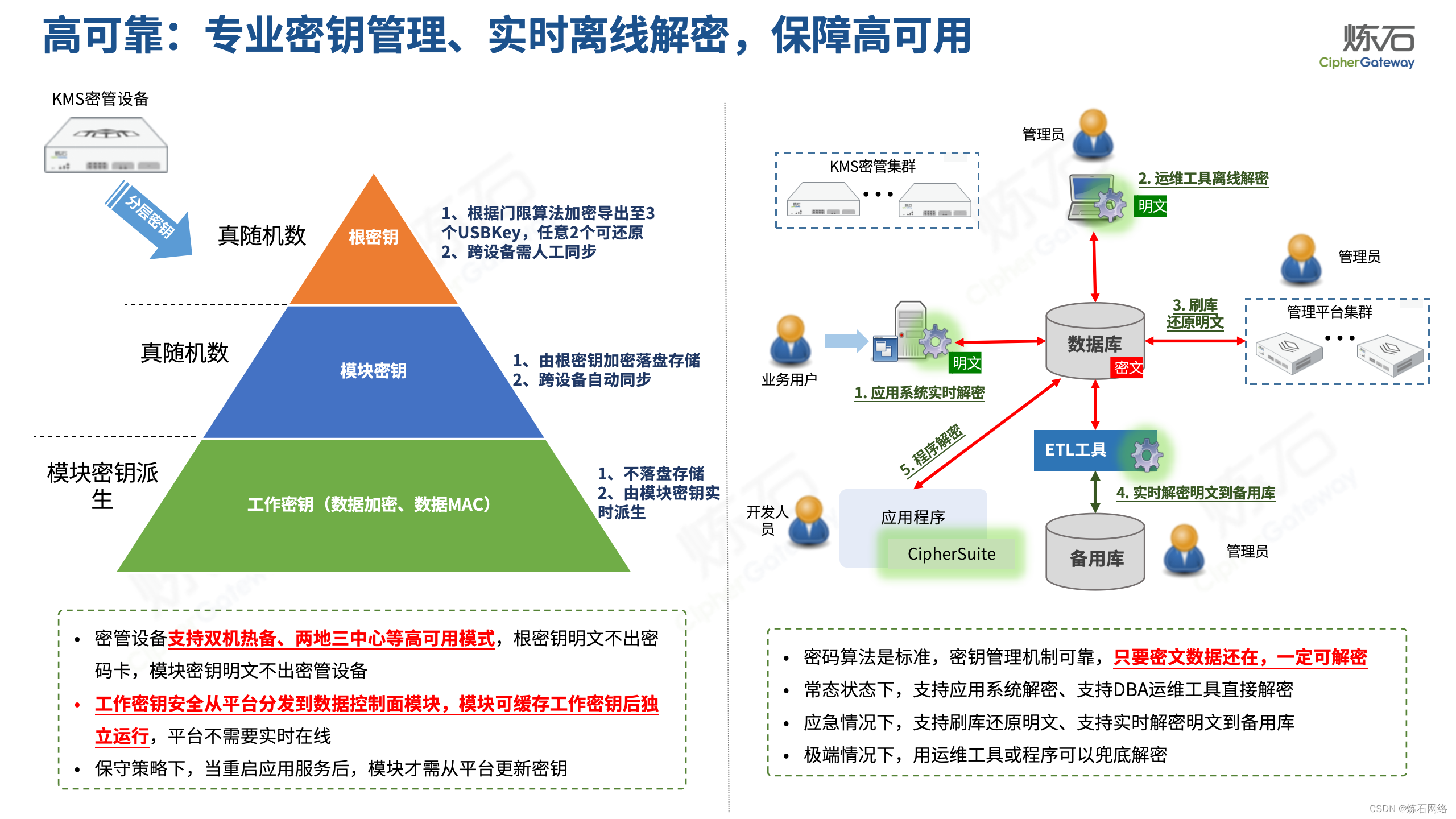


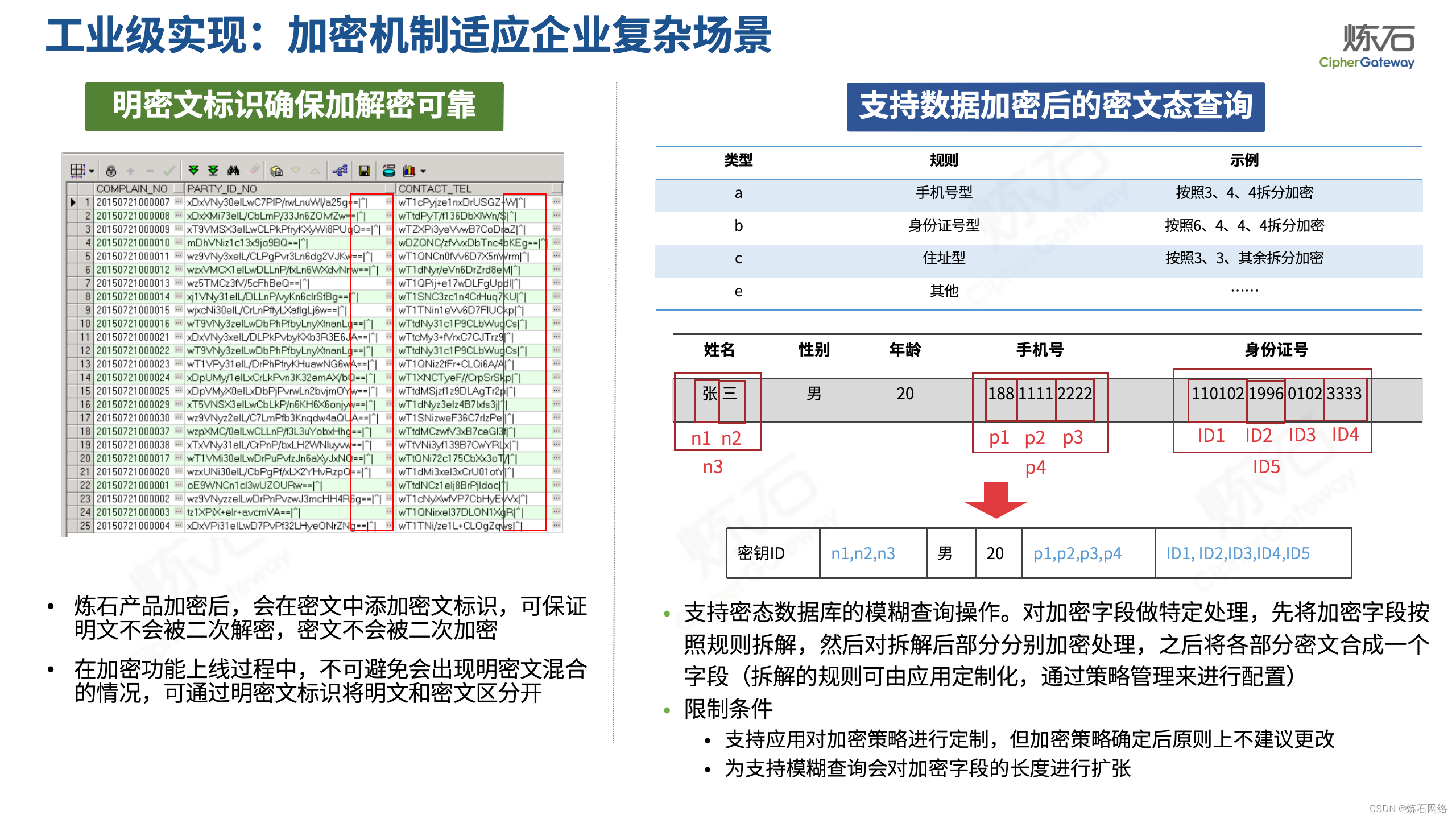

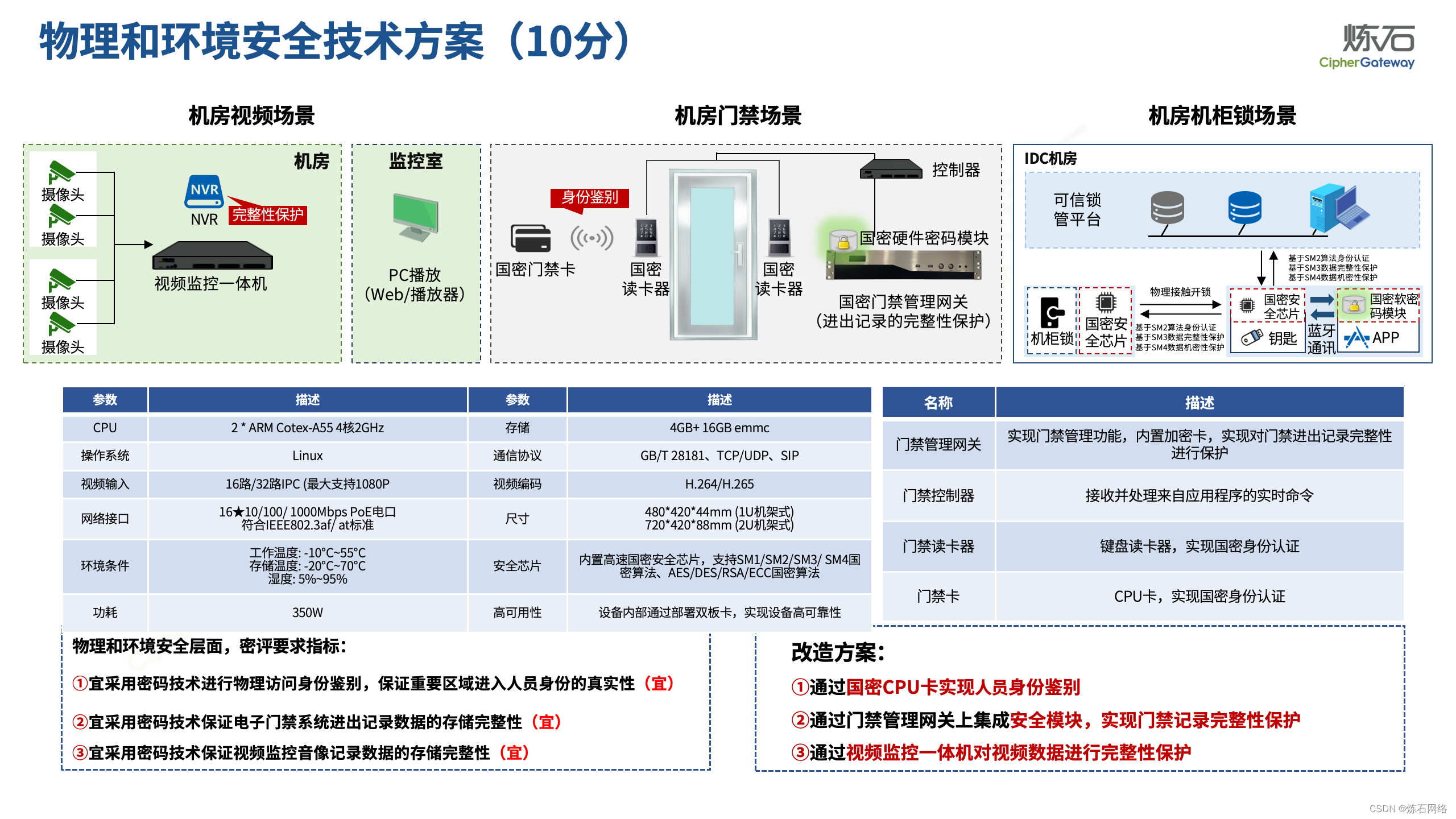
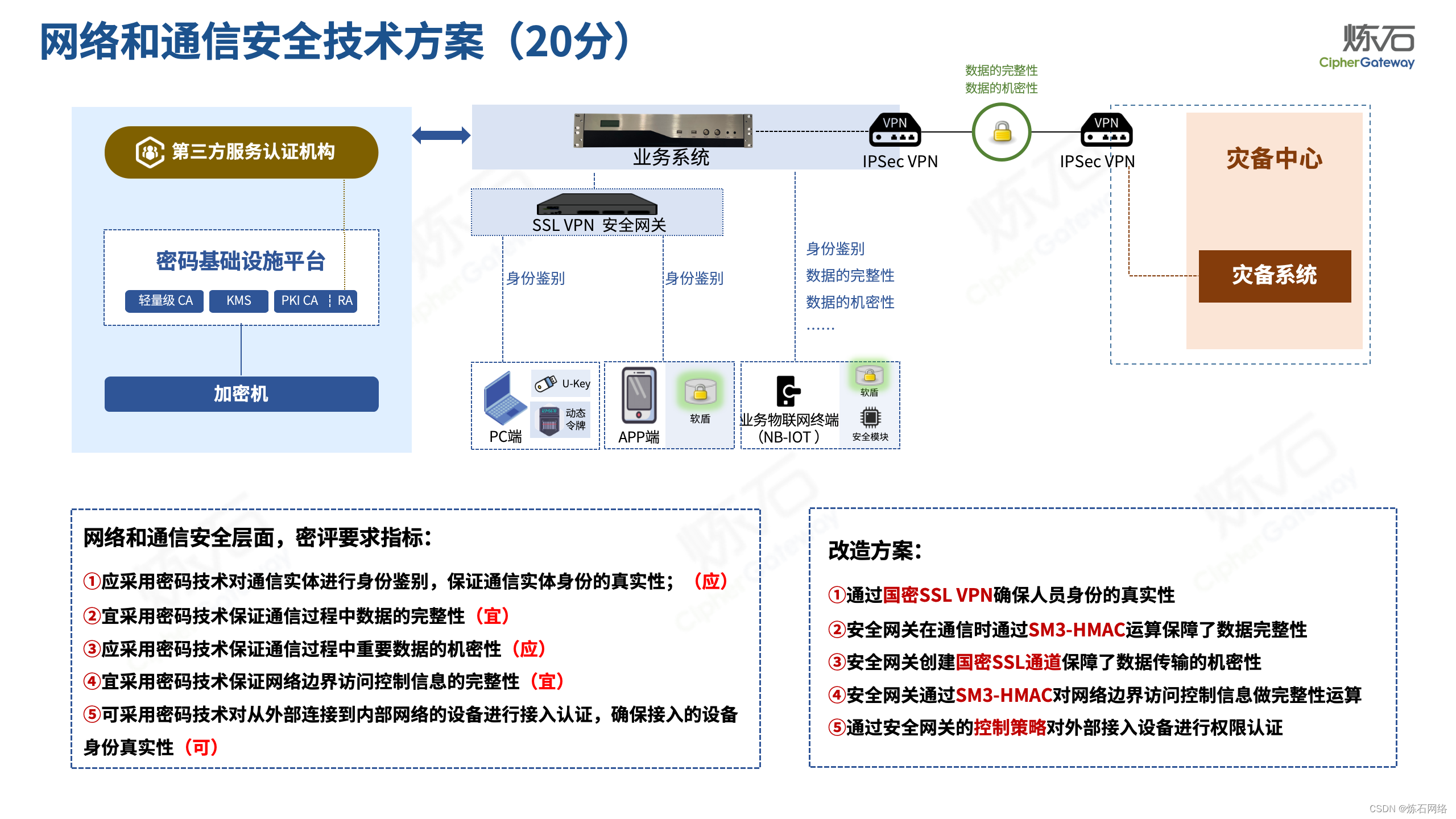

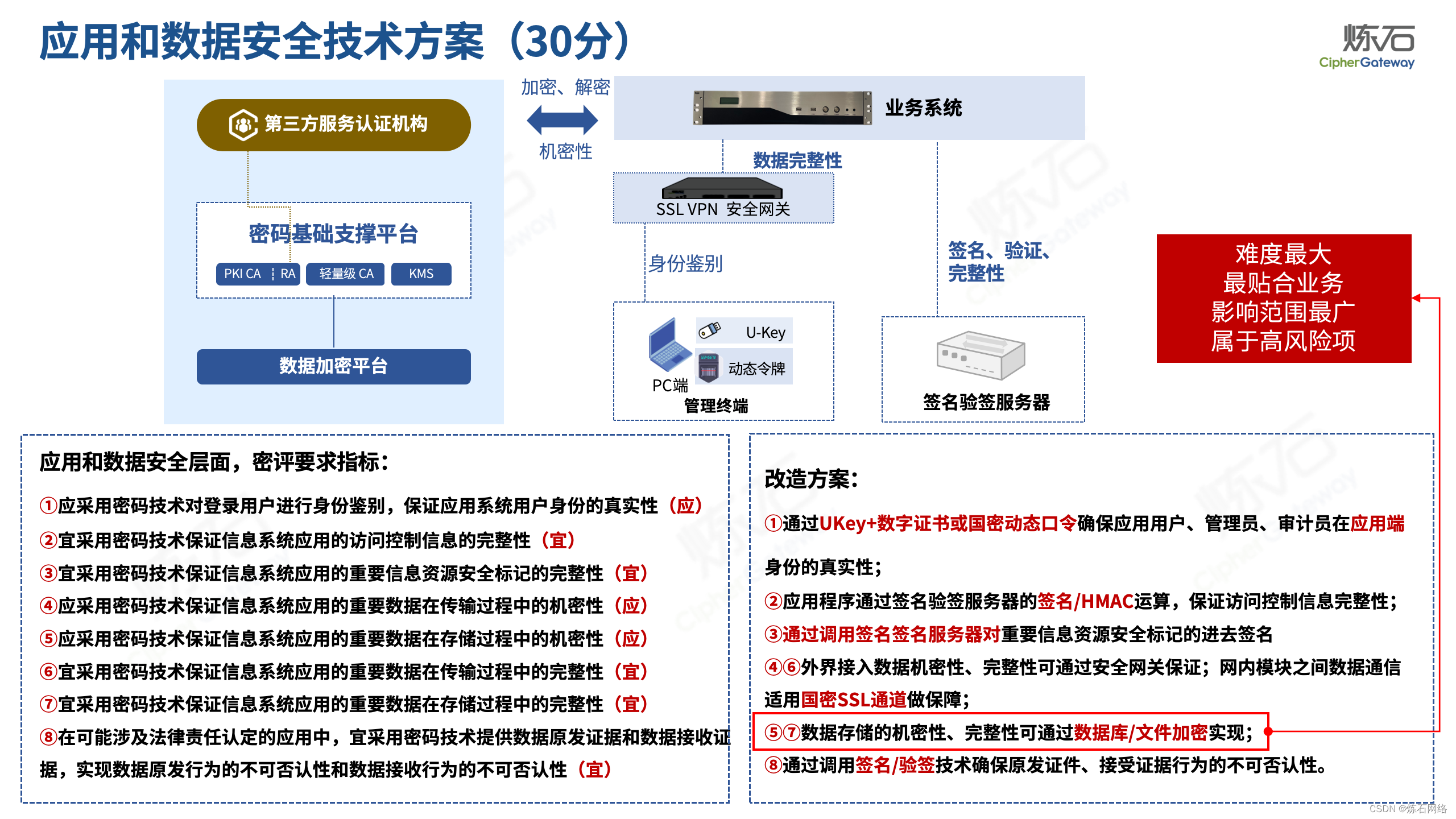

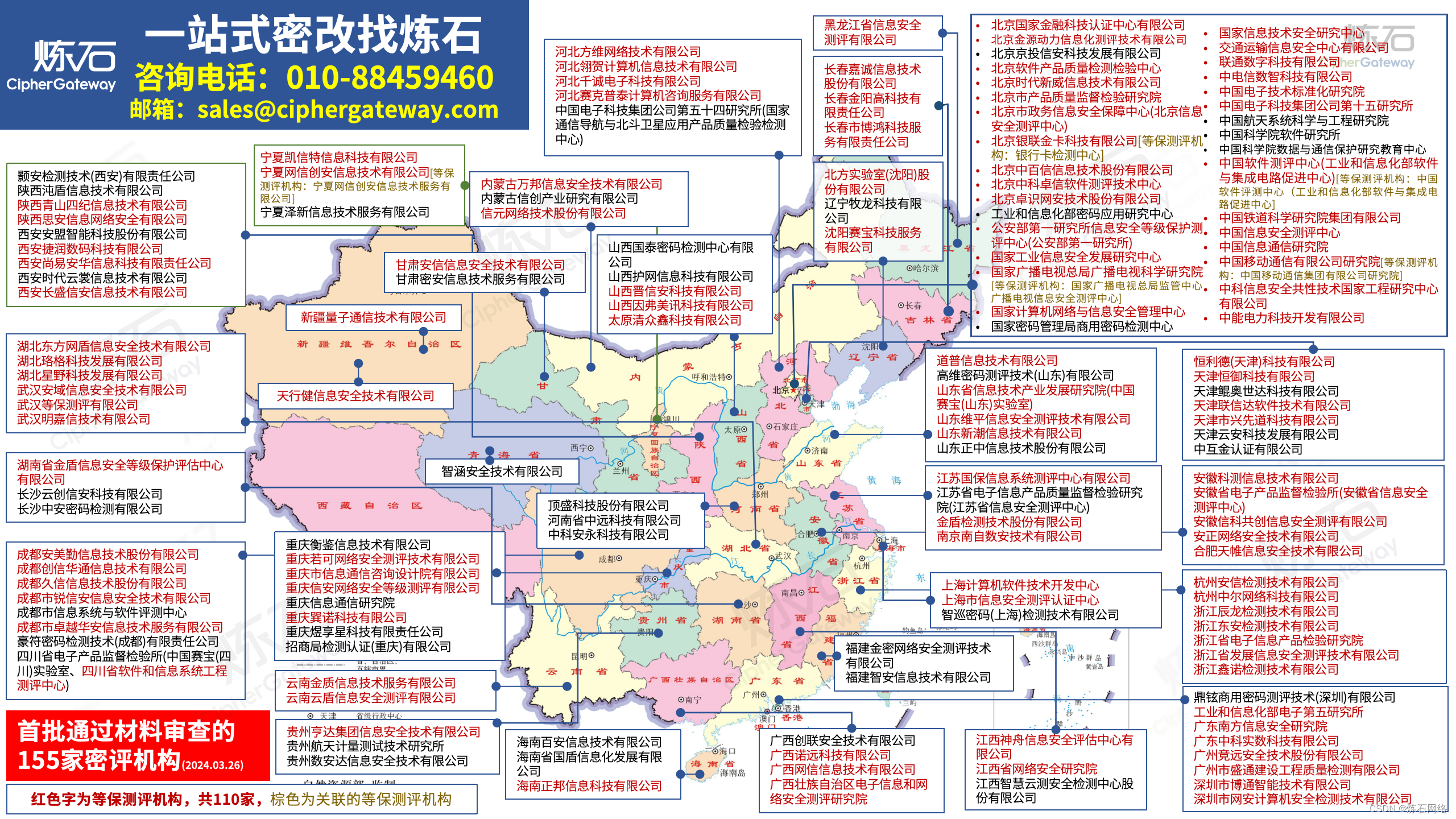













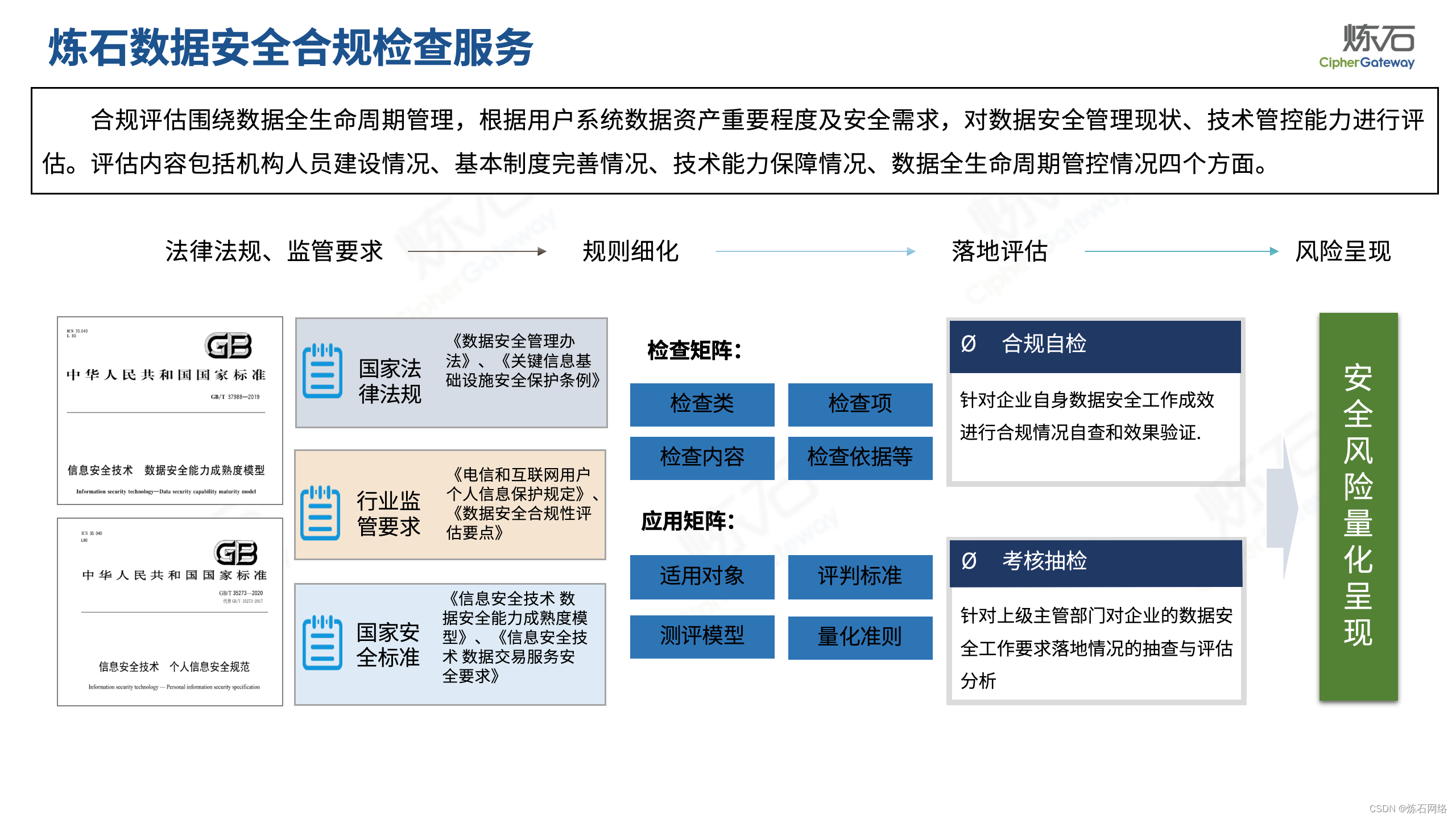



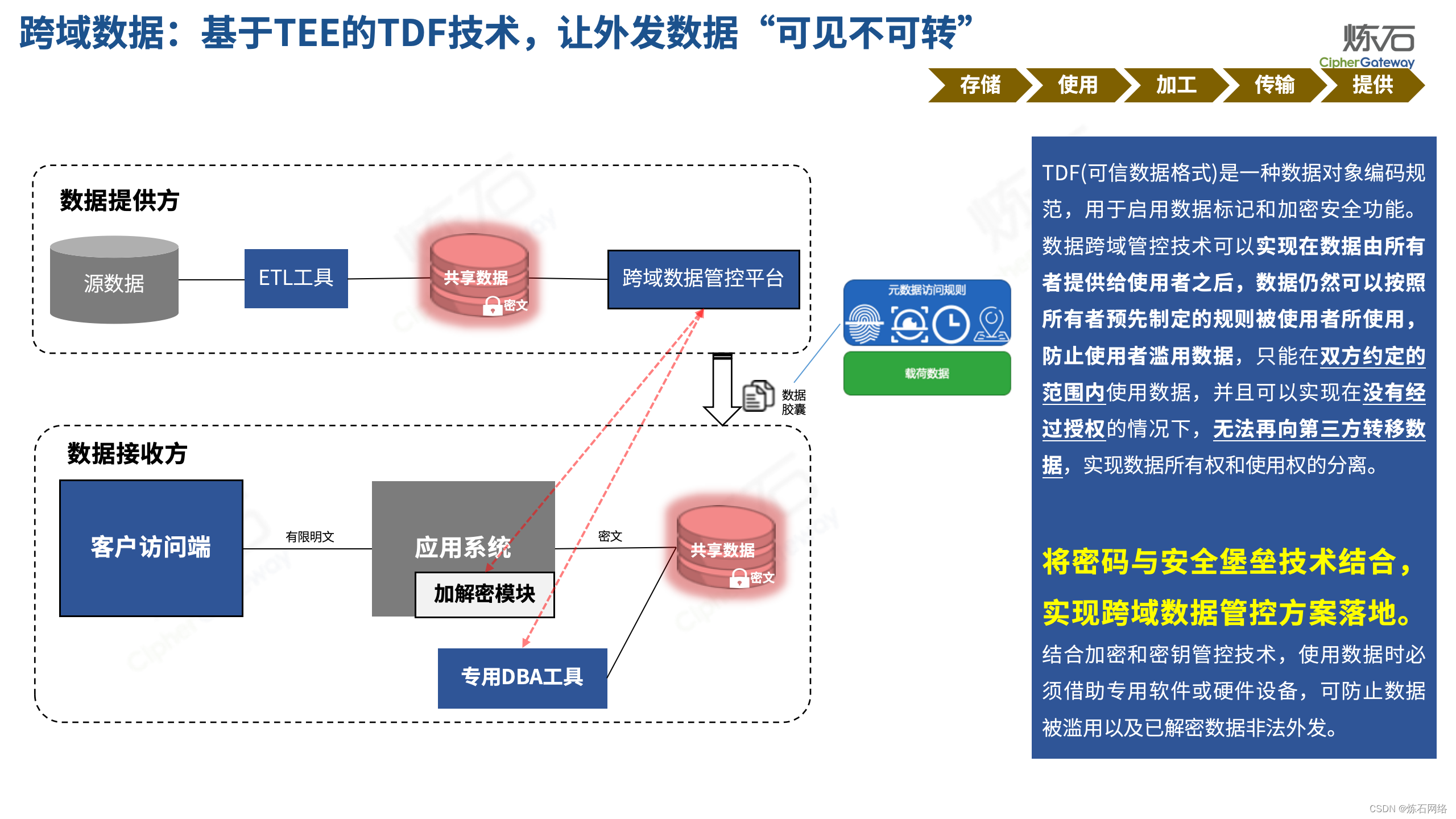


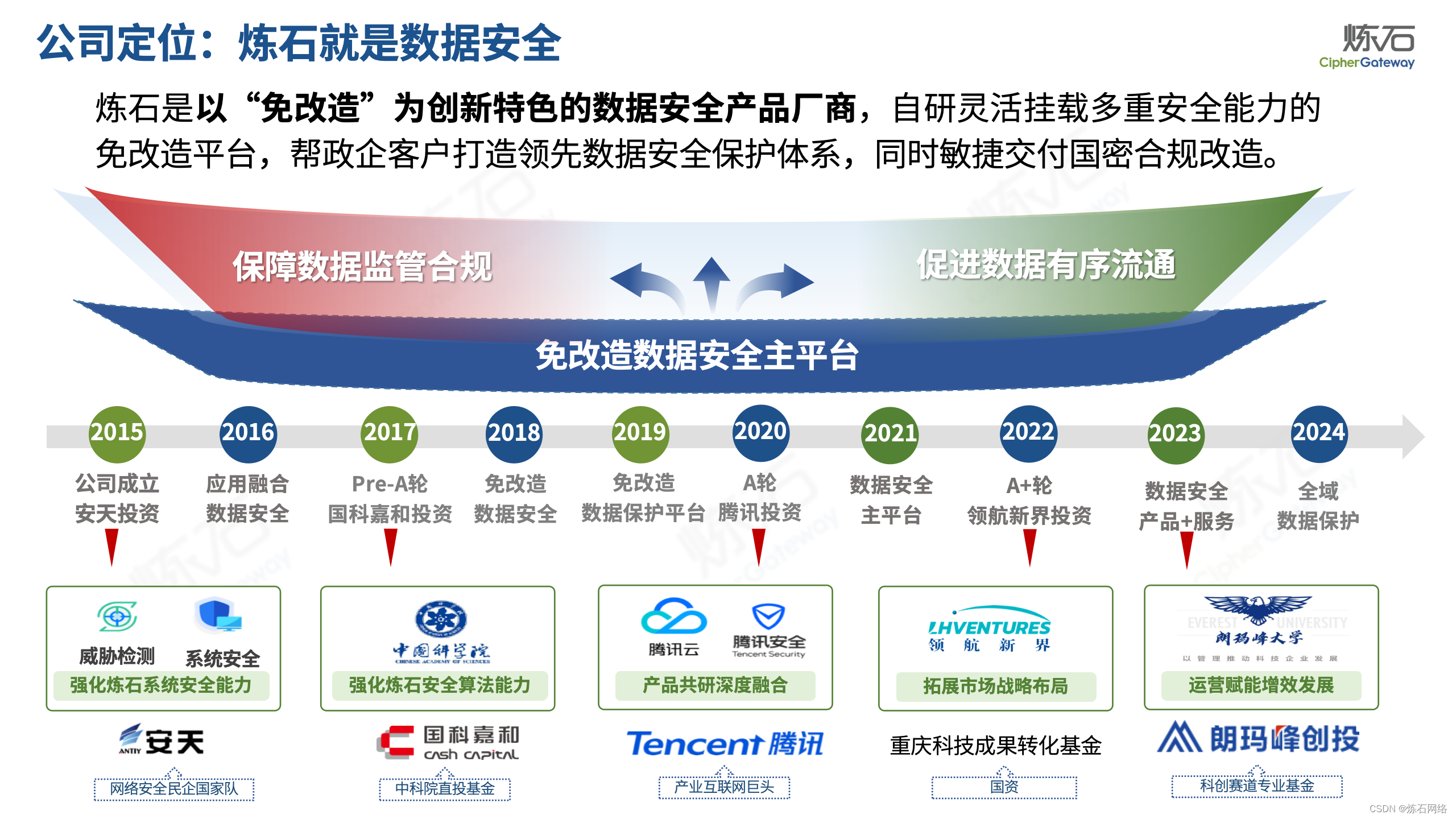

为了共同推动数据安全产业发展,欢迎行业同仁加入“[炼石]数据安全技术圈”微信群,探讨数据安全技术最新动态和最佳实践。
从微信中搜索公众号:炼石网络CipherGateway,并后台回复关键词“炼石就是数据安全104”,即可下载【正式版-炼石图解《数据安全技术 数据分类分级规则》PDF版及标准原文】
这篇关于200页图解国标《数据分类分级规则》正式稿,强化重要数据识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







