本文主要是介绍1997-2022年各省技术市场发展水平数据(原始数据+计算过程+计算结果),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1997-2022年各省技术市场发展水平数据(原始数据+计算过程+计算结果)
1、时间:2000-2022年
2、来源:国家统计局、统计年鉴
3、范围:30省
4、指标:技术市场成交额、国内生产总值、技术市场发展水平
5、计算说明:技术市场发展水平=技术市场成交额/国内生产总值
6、指标解释:
技术市场成交额是指在技术领域内的交易活动所形成的总额。它包括了各种技术产品和服务的销售额、技术许可费、技术转让费等各项收入。技术市场成交额可以作为一个指标来衡量一个国家或地区技术产业的发展水平和经济活力。高额的技术市场成交额通常代表着技术创新和竞争力的增强,对经济增长和就业的推动作用也较为显著。
7、下载链接:
1997-2022年各省技术市场发展水平数据(含原始数据+计算过程+计算结果)![]() https://download.csdn.net/download/m0_71334485/89135718
https://download.csdn.net/download/m0_71334485/89135718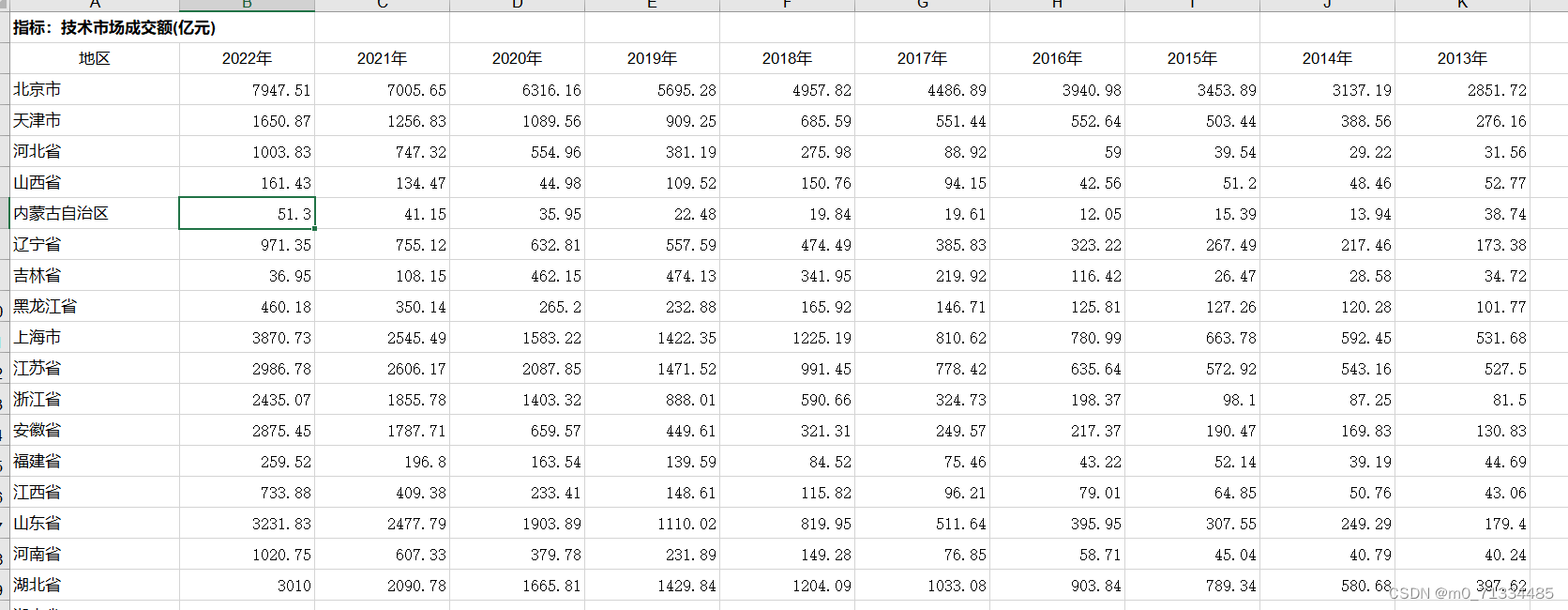
这篇关于1997-2022年各省技术市场发展水平数据(原始数据+计算过程+计算结果)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






