本文主要是介绍Detect AI Generated(Kaggle竞赛),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLM - 检测 AI 生成的文本确定哪篇文章是由大型语言模型撰写的
数据集说明
竞赛数据集包括大约 10,000 篇论文,其中一些由学生撰写,一些由各种大型语言模型 (LLM) 生成。比赛的目的是确定论文是否由法学硕士生成。
所有的文章都是根据七个论文提示之一写的。在每个提示中,学生被指示阅读一个或多个源文本,然后写一个回答。在生成论文时,这些信息可能已作为 LLM 的输入提供,也可能没有提供。
来自两个提示的论文组成了训练集;其余的论文组成了隐藏的测试集。几乎所有的训练集论文都是由学生撰写的,只有少数生成的论文作为示例。您可能希望生成更多文章以用作训练数据。
请注意,这是一场代码竞赛。中的数据只是虚拟数据,可帮助你创作解决方案。当您提交的内容被评分时,此示例测试数据将替换为完整的测试集。测试集中大约有 9,000 篇论文,包括学生撰写的和 LLM 生成的。test_essays.csv
文件和字段信息
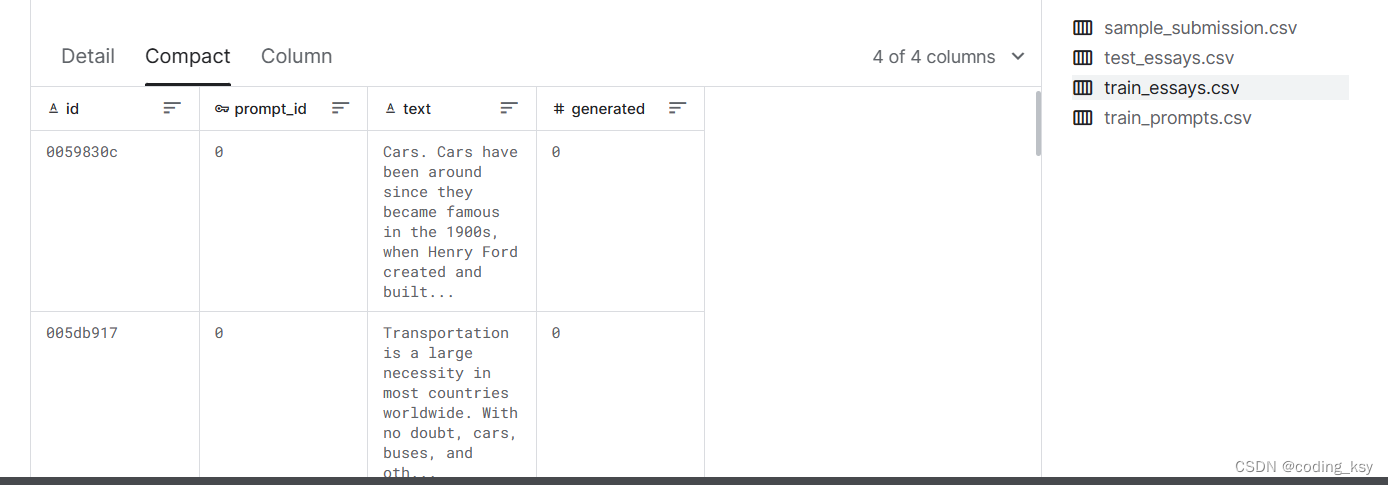
{test|train}_essays.csv
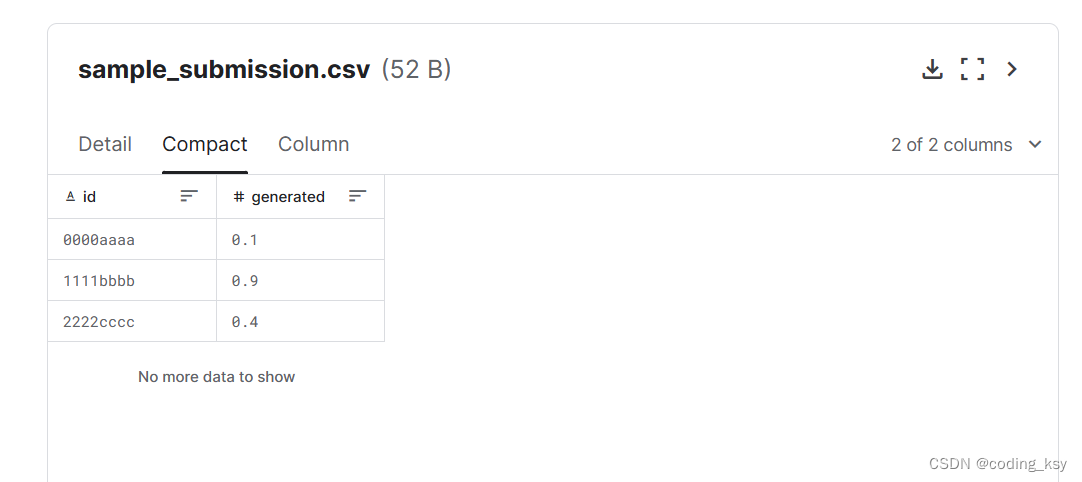
id- 每篇文章的唯一标识符。
prompt_id- 确定撰写文章时所响应的提示。
text- 论文文本本身。
generated- 论文是由学生()撰写的,还是由法学硕士()撰写的。此字段是目标,在 中不存在。01test_essays.csv
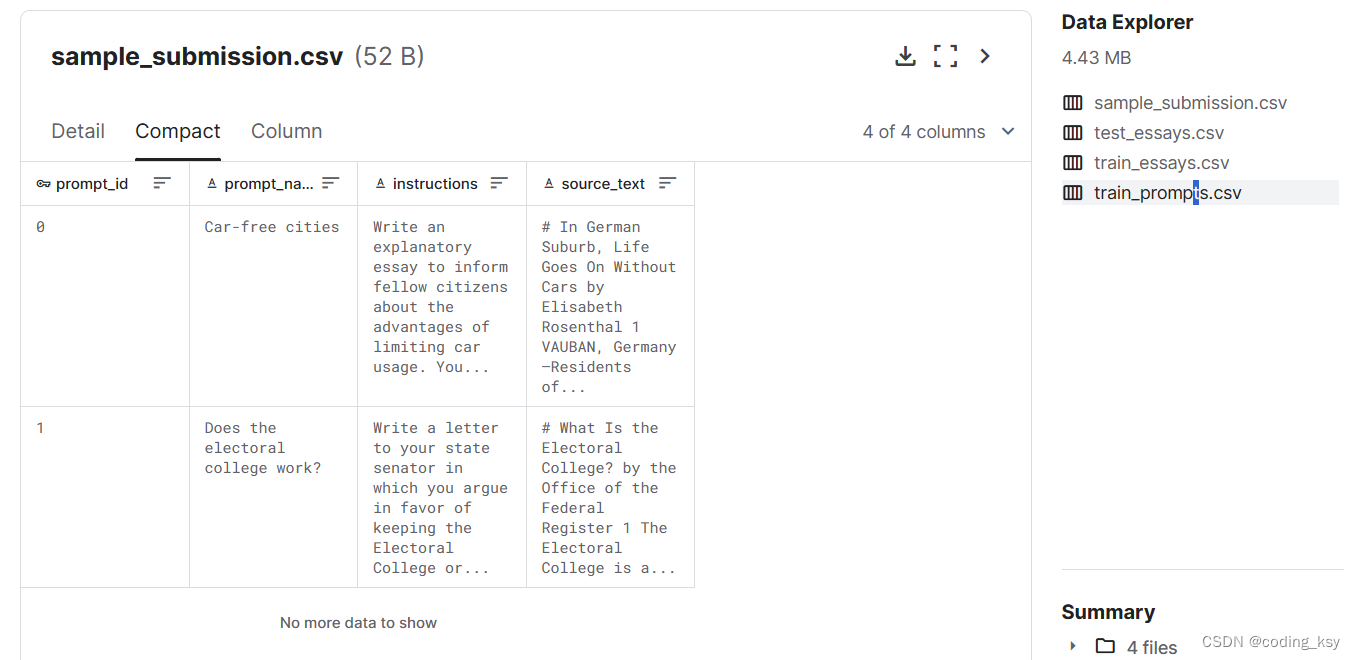
train_prompts.csv - 论文是针对这些领域的信息而写的。
prompt_id- 每个提示的唯一标识符。
prompt_name- 提示的标题。
instructions- 给学生的指示。
source_text- 文章的文本是以 Markdown 格式撰写的。重要段落在同一行的段落前用数字枚举,如 中所示。散文有时通过数字来指代一个段落。每篇文章的标题前面都有一个标题,如 .当注明作者时,他们的名字将在标题中给出。并非所有文章都注明了作者。一篇文章的副标题可能如下所示。0 Paragraph one.\n\n1 Paragraph two.# Titleby## Subheading
sample_submission.csv - 格式正确的提交文件。有关详细信息,请参阅评估页面。

baseline代码
import warnings
warnings.filterwarnings('ignore')
# TfidfVectorizer用于将文本数据转换为TF-IDF特征,这是一种常用的文本特征表示方法。
from sklearn.feature_extraction.text import TfidfVectorizer# StratifiedKFold和train_test_split用于数据分割,前者用于分层抽样的交叉验证,后者用于随机分割数据成训练集和测试集。
from sklearn.model_selection import StratifiedKFold, train_test_split# SGDClassifier是随机梯度下降分类器,适用于大规模和高维度数据的分类问题。
from sklearn.linear_model import SGDClassifier# MultinomialNB是多项式朴素贝叶斯分类器,通常用于文本分类任务。
from sklearn.naive_bayes import MultinomialNB# VotingClassifier用于实现投票机制的集成学习,结合多个模型的预测结果来提高整体的预测准确度。
# RandomForestClassifier是随机森林分类器,它使用多个决策树对样本进行分类,并通过投票得到最终结果,非常适合处理高维度数据。
from sklearn.ensemble import VotingClassifier, RandomForestClassifier# roc_auc_score是一种评估二分类模型性能的指标,计算真正率和假正率之间的关系。
from sklearn.metrics import roc_auc_score# CatBoostClassifier是一个基于梯度提升决策树的机器学习算法,专为处理类别特征而设计。
from catboost import CatBoostClassifier# LGBMClassifier是LightGBM的分类器,一个高效的梯度提升框架,它使用基于梯度的一致决策树算法。
from lightgbm import LGBMClassifier
# 导入PreTrainedTokenizerFast类,这是transformers库中用于高效分词的类,可以加载和使用预训练的分词器。
from transformers import PreTrainedTokenizerFast# 导入一系列从tokenizers库中的模块,这是一个为快速文本分词设计的库。
from tokenizers import (decoders, # decoders用于将分词后的输出转换回可读文本。models, # models提供了分词模型的基础架构,如BPE(Byte-Pair Encoding)。normalizers, # normalizers用于文本的预处理,如将所有文本转换为同一格式(如NFC)或大小写规范化。pre_tokenizers, # pre_tokenizers进行文本的初步分词处理,如按字节分割。processors, # processors用于在分词后对令牌进行后处理,如添加特定的令牌(如[CLS]、[SEP]等)。trainers, # trainers用于训练自定义的分词器模型。Tokenizer, # Tokenizer是一个用于创建和使用自定义分词器的类。
)
# 导入datasets库,用于处理数据集
from datasets import Dataset
from tqdm.auto import tqdm # 进度条库,用于显示进度
import pandas as pd # 数据处理库
import numpy as np # 数值计算库
import sys
import gc # 垃圾回收库,用于手动管理内存
# 读取测试数据集
test = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/test_essays.csv')
# 读取提交样本
sub = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/sample_submission.csv')
# 读取训练数据集
train = pd.read_csv("/kaggle/input/daigt-v2-train-dataset/train_v2_drcat_02.csv", sep=',')
# 删除重复的文本数据
train = train.drop_duplicates(subset=['text'])
# 重置索引
train.reset_index(drop=True, inplace=True)
# 显示前几行数据以便检查
train.head()
# 定义要排除的提示名列表
excluded_prompt_name_list = ['Distance learning','Grades for extracurricular activities','Summer projects']
# 从训练数据中排除特定提示名的数据
train = train[~(train['prompt_name'].isin(excluded_prompt_name_list))]
# 再次删除重复数据并重置索引
train = train.drop_duplicates(subset=['text'])
train.reset_index(drop=True, inplace=True)
# 将文本数据转换为数组形式,方便处理
test.text.values# 设置是否将文本转换为小写
LOWERCASE = False
# 设置词汇表大小
VOCAB_SIZE = 14_000_000
# 创建一个Tokenizer对象,使用BPE模型。BPE是一种常用于NLP的子词分词方法,可以有效地处理未知词汇或稀有词。
raw_tokenizer = Tokenizer(models.BPE(unk_token="[UNK]"))
Tokenizer: 这是tokenizers库中的一个类,它允许创建和管理自定义的分词器。
models.BPE: 这指定使用Byte-Pair Encoding模型作为分词的基础算法。BPE通过合并频繁出现的字节对来减少词汇表的大小,同时有效处理未知字符和词汇。
unk_token=“[UNK]”: 这设置了一个特殊的未知词标记(UNK token)。当分词器遇到它在词汇表中找不到的单词时,会用这个标记来代替。
使用BPE算法的优点之一是它可以平衡词汇表大小与处理未见词的能力,使得模型能够更好地泛化到新文本上。这种方法特别适用于词汇丰富或者包含大量稀有词汇的语言处理任务。
# 设置分词器的正规化处理流程。这里使用了一个条件语句来决定是否将文本转化为小写。
# normalizers.NFC() 确保文本遵循Unicode的规范化形式C,这有助于统一字符的表示,减少由于字符变体导致的不必要的文本差异。
# normalizers.Lowercase() 将所有文本转换为小写,这个步骤在LOWER_CASE为True时才会添加。
raw_tokenizer.normalizer = normalizers.Sequence([normalizers.NFC()] + [normalizers.Lowercase()] if LOWERCASE else []
)# 设置分词器的预分词器为字节级别处理。
# ByteLevel预分词器按字节切分文本,这对于一些需要处理未知或罕见字符的语言或文本格式特别有效。
raw_tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel()
# 定义一个列表,包含将在分词过程中使用的特殊令牌。
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
[UNK] (Unknown Token): 当遇到不在词汇表中的单词时使用。
[PAD] (Padding Token): 用于文本序列的填充,使所有输入的长度匹配,常用于处理成批数据。
[CLS] (Classification Token): 常用于分类任务的开始位置,表示整个输入序列的聚合状态。
[SEP] (Separator Token): 用于分隔不同的序列,例如在问答任务中分隔问题和答案。
[MASK] (Mask Token): 在进行遮蔽语言模型训练时使用,表示被遮蔽的单词。
接下来,创建训练器实例:
# 创建BPE模型的训练器,指定词汇表大小和包含的特殊令牌。
trainer = trainers.BpeTrainer(vocab_size=VOCAB_SIZE, special_tokens=special_tokens
)
设置特殊令牌并初始化分词器的训练器。
dataset = Dataset.from_pandas(test[['text']])
将测试集文本转换为datasets库格式。
def train_corp_iter():for i in range(0, len(dataset), 1000):yield dataset[i : i + 1000]["text"]
raw_tokenizer.train_from_iterator(train_corp_iter(), trainer=trainer)
定义一个生成器函数来分批提供数据,并训练分词器。
tokenizer = PreTrainedTokenizerFast(tokenizer_object=raw_tokenizer,unk_token="[UNK]", pad_token="[PAD]", cls_token="[CLS]", sep_token="[SEP]", mask_token="[MASK]",
)
创建一个快速的预训练分词器实例。
tokenized_texts_test = [tokenizer.tokenize(text) for text in tqdm(test['text'].tolist())]
tokenized_texts_train = [tokenizer.tokenize(text) for text in tqdm(train['text'].tolist())]
使用分词器处理测试集和训练集文本。
vectorizer = TfidfVectorizer(ngram_range=(3, 5), lowercase=False, sublinear_tf=True,analyzer='word', tokenizer=dummy, preprocessor=dummy,token_pattern=None, strip_accents='unicode'
)
vectorizer.fit(tokenized_texts_test)
vocab = vectorizer.vocabulary_
使用TF-IDF向量化方法处理分词后的文本,提取特征,并获取词汇表。
vectorizer = TfidfVectorizer(ngram_range=(3, 5), lowercase=False, sublinear_tf=True,vocabulary=vocab, analyzer='word', tokenizer=dummy,preprocessor=dummy, token_pattern=None, strip_accents='unicode'
)
tf_train = vectorizer.fit_transform(tokenized_texts_train)
tf_test = vectorizer.transform(tokenized_texts_test)
重用测试集的词汇表来向量化训练集文本,以保持特征空间的一致性。
if len(test.text.values) <= 5:sub.to_csv('submission.csv', index=False)
else:# 初始化各种分类模型并组成一个投票分类器clf = MultinomialNB(alpha=0.0225)sgd_model = SGDClassifier(max_iter=9000, tol=1e-4, random_state=6743, loss="modified_huber")p = {'verbose': -1, 'n_iter': 3000, 'colsample_bytree': 0.7800, 'colsample_bynode': 0.8000, 'random_state': 6743, 'metric': 'auc', 'objective': 'cross_entropy', 'learning_rate': 0.00581909898961407}lgb = LGBMClassifier(**p)cat = CatBoostClassifier(iterations=3000, verbose=0, subsample=0.35, random_seed=6543, allow_const_label=True, loss_function='CrossEntropy', learning_rate=0.005599066836106983)ensemble = VotingClassifier(estimators=[('mnb', clf), ('sgd', sgd_model), ('lgb', lgb), ('cat', cat)],weights=[0.1, 0.31, 0.28, 0.67], voting='soft', n_jobs=-1)ensemble.fit(tf_train, y_train_label)final_preds = ensemble.predict_proba(tf_test)[:,1]sub['generated'] = final_predssub.to_csv('submission.csv', index=False)sub.head()
这篇关于Detect AI Generated(Kaggle竞赛)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








