本文主要是介绍【机器学习300问】72、神经网络的隐藏层数量和各层神经元节点数如何影响模型的表现?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
评估深度学习的模型的性能依旧可以用偏差和方差来衡量。它们反映了模型在预测过程中与理想情况的偏离程度,以及模型对数据扰动的敏感性。我们简单回顾一下什么是模型的偏差和方差?
一、深度学习模型的偏差和方差
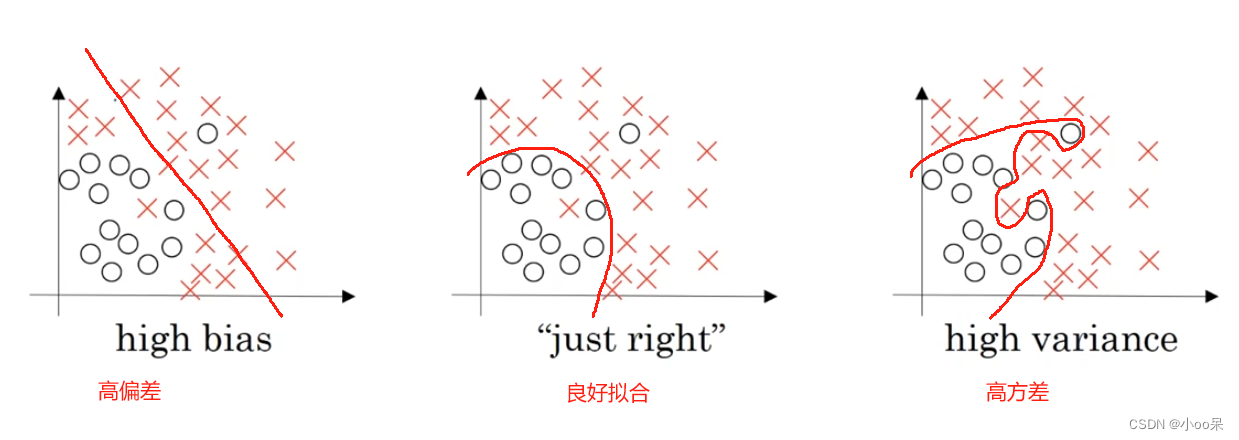
- 偏差:衡量模型预测结果的期望值与真实值之间的差异;
- 方差:度量模型预测结果的变动性或离散程度;
如果模型在训练集上都表现得很差,就说模型高偏差(High Bias),此时模型欠拟合。
如果模型在验证集上表现很差在测试集上表现很好,就说模型高方差(High Variance),此时模型过拟合。
| 第一种情况 | 第二种情况 | 第三种情况 | 第四种情况 | |
| 训练集误差 | 1% | 15% | 15% | 0.5% |
| 验证集误差 | 11% | 16% | 30% | 1% |
| 基准误差1 | 假设 | |||
| 模型性能评估1 | 高方差 | 高偏差 | 高偏差 高方差 | 低偏差 低方差 |
| 基准误差2 | 假设 | |||
| 模型性能评估2 | / | 低偏差 低方差 | 高方差 | / |
如果您想加深对这一知识点的理解,不妨看看我之前的文章哦:
【机器学习300问】27、高偏差与高方差是什么?他们对评估机器学习模型起何作用?![]() http://t.csdnimg.cn/I0USG
http://t.csdnimg.cn/I0USG
二、神经网络的深度和节点数对模型性能有何影响?
(1) 隐藏层层数(模型复杂度)
隐藏层的个数就是神经网络的深度,他是一个重要的超参数。
-
高偏差: 如果神经网络的隐藏层数过少或深度不足,模型的复杂度相对较低,可能无法充分捕捉数据中的复杂非线性关系和高级抽象特征。这样的模型倾向于产生简单的决策边界,对训练数据的拟合程度不足,表现为高偏差。具体来说,深度较浅的网络可能无法挖掘到数据中深层次的依赖关系,导致模型对训练数据的学习过于粗糙,预测结果与真实值存在较大偏差。
-
高方差: 反之,如果神经网络的隐藏层数过多,深度过大,模型的复杂度极高。这种情况下,网络可能过度拟合训练数据,学习到许多特定于训练集的细节和噪声,而不是数据中更稳定、更具泛化性的特征。过深的网络容易陷入对训练数据的局部最小值,对新样本的微小变化异常敏感,从而导致在测试集上表现出很大的方差。
(2)神经元节点数(模型容量)
各层神经元节点数也是影响模型性能的关键超参数。
-
高偏差: 当神经网络各层的神经元节点数过少时,模型的容量有限,可能无法充分表示数据的复杂性。节点数不足会导致网络的表达能力受限,无法捕捉到数据中的细微差异和复杂关系,造成模型过于简单化,无法适应数据分布,从而产生高偏差。如同一个容量有限的容器,只能装下数据的粗略轮廓,而忽视了重要的细节信息。
-
高方差: 相反,若各层神经元节点数过多,模型的容量过大,网络有很强的拟合复杂函数的能力。此时,模型容易过拟合训练数据,对噪声和偶然性特征过于敏感,记忆了训练集中的个体特例而非一般规律。过大的节点数使得网络在训练时能够轻易地“记住”每个训练样本,但在面对未见过的数据时,由于过度适应训练细节,模型的预测结果波动性增大,即表现出高方差。
(3)总结
- 神经网络层数少、神经元节点少,可能导致高偏差(欠拟合)
- 神经网络层数多,神经元节点多,可能导致高方差(过拟合)
这篇关于【机器学习300问】72、神经网络的隐藏层数量和各层神经元节点数如何影响模型的表现?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







