本文主要是介绍基于对抗学习(域适应)的脑电信号SEEG/EEG分类算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很久没有更新博客了,手头上有一些工作,发论文不是很顺利(论文已经中了,虽然是水刊,但还是很高兴),但是还是想通过博客的方式分享处理。
对抗学习(Adversarial Learning)的思想最早可以追溯到博弈论里面优化问题。GAN(Generative Adversarial Networks)网络是一种典型的基于对抗学习的神经网络。GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
这其实对于信号处理的工作是具有启发意义的。特别是对于脑电信号的处理,由于每个人的脑电信号受到个体因素的影响,信号中带有明显的个体特征。这些个体特征会影响到分类器的分类效果和模型的泛化能力。通俗来说,模型可能没有学会有意义的目标特征,而是学会了无关的信息导致模型在新人上的迁移能力较弱。
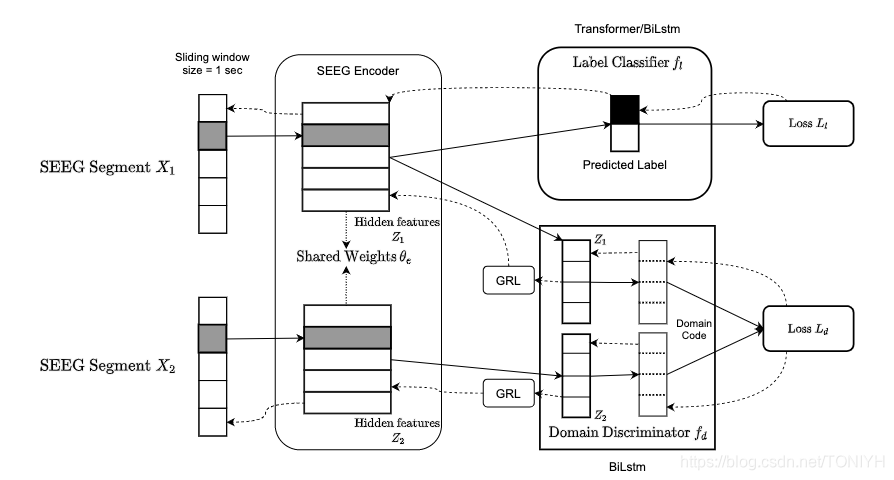
于是我们设计了上面的一个基于对抗学习的脑电分类模型。
域对抗分类模型(Epilepsy Domain Adversarial Neural Network,EDANN)主要包含三个模块:编码模块,域判别模块,类判别模块。编码模块可以提取脑电信号的特征,域鉴别器主要用于确定是否一对SEEG片段来至于同一位患者,可以通过梯度逆转层(Gradient Reversal Layer,GRL)模块以对抗性方式对域鉴别器进行优化。 它确保了网络无法基于领域知识进行分类,并减少了SEEG数据由于个体差异而对模型的干扰;类判别器是对目标SEEG数据进行分类。我们可以将编码器表示为 f e ( X ; θ e ) f_{e}(X;\theta_{e}) fe(X;θe), 编码器用于提取多信道的脑电特征并降低原始脑电数据纬度。 θ e \theta_{e} θe表示的是编码器学习到的参数。
类别判别器可以表示为 f l ( f e ; θ l ) f_{l}(f_{e};\theta_{l}) fl(fe;θl),类判别器可以给出输入数据 X X X的预测标签, θ l \theta_{l} θl表示的是类别判别器学习到的参数。
域判别器可可以表示为 f d ( f e ; θ d ) f_{d}(f_{e};\theta_{d}) fd(fe;θd),域判别器是判别一对输入 X 1 X_{1} X1和 X 2 X_{2} X2是否来至于同一个病人。其中 X 2 X_{2} X2来至于数据的随机采样。最后的损失函数来至于两个部分,一个是来至于类别预测的损失函数 L l ( f l ( f e ; θ l ) ) \mathcal{L}_{l}(f_{l}(f_{e};\theta_{l})) Ll(fl(fe;θl)), 另外一部分的损失函数来至于域判别器的损失函数 L d ( f d ( f e ; θ d ) ) \mathcal{L}_{d}\left(f_{d}\left(f_{e} ; \theta_{d}\right)\right) Ld(fd(fe;θd))。对于一对输入 X 1 X_{1} X1和 X 2 X_{2} X2损失函数可以定义为:
L ( X 1 , X 2 ; θ e , θ l , θ d ) = L l ( f l ( f e ( X 1 ; θ e ) ; θ l ) ) − γ L d ( f d ( f e ( X 1 ; θ e ) ; θ d ) , f d ( f e ( X 2 ; θ e ) ; θ d ) ) \mathcal{L}\left(X_{1}, X_{2} ; \theta_{e}, \theta_{l}, \theta_{d}\right) = \mathcal{L}_{l}\left(f_{l}\left(f_{e}\left(X_{1} ; \theta_{e}\right) ; \theta_{l}\right)\right) -\gamma \mathcal{L}_{d}\left(f_{d}\left(f_{e}\left(X_{1} ; \theta_{e}\right) ; \theta_{d}\right), f_{d}\left(f_{e}\left(X_{2} ; \theta_{e}\right) ; \theta_{d}\right)\right) L(X1,X2;θe,θl,θd)=Ll(fl(fe(X1;θe);θl))−γLd(fd(fe(X1;θe);θd),fd(fe(X2;θe);θd))
其中 γ \gamma γ是超参。为了方便起见,我们用 Z 1 Z_{1} Z1和 Z 2 Z_{2} Z2表示为输入数据 X 1 X_{1} X1和 X 2 X_{2} X2经过编码器 f e ( X ; θ e ) f_{e}(X;\theta_{e}) fe(X;θe)的输出。对于类别判别器的损失函数可以定义为二元交叉熵:
L l ( f l ( Z 1 ; θ l ) ) = − [ y 1 log f l ( Z 1 ) + ( 1 − y 1 ) log ( 1 − f l ( Z 1 ) ) ] \mathcal{L}_{l}\left(f_{l}\left(Z_{1} ; \theta_{l}\right)\right)=-\left[y_{1} \log f_{l}\left(Z_{1}\right)+\left(1-y_{1}\right) \log \left(1-f_{l}\left(Z_{1}\right)\right)\right] Ll(fl(Z1;θl))=−[y1logfl(Z1)+(1−y1)log(1−fl(Z1))]
其中 y 1 y_{1} y1表示的是输入数据 X 1 X_{1} X1的标签; f l ( Z 1 ) f_{l}(Z_{1}) fl(Z1)表示的是类别分类器给出的预测值。对于域判别器的损失函数 L d ( f d ( Z 1 ; θ d ) , f d ( Z 2 ; θ d ) ) \mathcal{L}_{d}\left(f_{d}\left(Z_{1} ; \theta_{d}\right), f_{d}\left(Z_{2} ; \theta_{d}\right)\right) Ld(fd(Z1;θd),fd(Z2;θd))可以定义如下:
L d ( f d ( Z 1 ; θ d ) , f d ( Z 2 ; θ d ) ) = 1 2 D ( f d ( Z 1 ) , f d ( Z 2 ) ) 2 I + 1 2 ( max { 0 , m − D ( f d ( Z 1 ) , f d ( Z 2 ) ) } ) 2 ( 1 − I ) \mathcal{L}_{d}\left(f_{d}\left(Z_{1} ; \theta_{d}\right), f_{d}\left(Z_{2} ; \theta_{d}\right)\right) =\frac{1}{2} D\left(f_{d}\left(Z_{1}\right), f_{d}\left(Z_{2}\right)\right)^{2} I +\frac{1}{2}\left(\max \left\{0, m-D\left(f_{d}\left(Z_{1}\right), f_{d}\left(Z_{2}\right)\right)\right\}\right)^{2}(1-I) Ld(fd(Z1;θd),fd(Z2;θd))=21D(fd(Z1),fd(Z2))2I+21(max{0,m−D(fd(Z1),fd(Z2))})2(1−I)
其中 I I I表示的是指示函数,它的取值范围为{0,1}; I = 1 I=1 I=1时表示两个样本 X 1 X_{1} X1和 X 2 X_{2} X2来至于同一个病人,相反, I = 0 I=0 I=0。 D ( ⋅ ) D(\cdot) D(⋅)是欧式距离函数, m m m是给定的数据的取值上界。对于所有的样本的损失函数 L t \mathcal{L}_{t} Lt定义如下:
L t = ∑ i , j N α L ( X i , X j ; θ e , θ l , θ d ) \mathcal{L}_{t}=\sum_{i, j}^{N} \alpha \mathcal{L}\left(X_{i}, X_{j} ; \theta_{e}, \theta_{l}, \theta_{d}\right) Lt=i,j∑NαL(Xi,Xj;θe,θl,θd)
其中 N N N表示的数据对的个数, X i X_{i} Xi和 X j X_{j} Xj表示的是输入的数据对; θ e \theta_{e} θe, θ l \theta_{l} θl和 θ d \theta_{d} θd分别表示的是编码器,类别判别器和域判别器的参数, α \alpha α表示的是学习率。
EDANN模型的域分类器是Bilstm模型。Bilstm的工作原理是首先通过卷积神经网络提取窗口SEEG信号空间(窗口大小=1s)的局部特征.CNN模型编码每个SEEG片段每个窗口的16维表示,因此原始 SEEG段可以表示为矩阵大小为 n × 15 n\times15 n×15的矩阵,其中N表示SEEG段的长度(n秒,n ∈ \in ∈[2, 15])。 然后利用BiLstm捕获两个方向表示之间的关系,然后及时学习SEEG信号的全局特性。根据全局特征,可以判断两个SEEG段是否来自同一域(两个SEEG段来自同一患者)。EDANN的类别分类器为Lstm或Transformer模型,根据选择的不同模型,可以将EDANN模型进行划分EDANN-Lstm和EDANN-Transformer,标签分类器可以根据编码器学习到的表示对目标SEEG片段进行分类。
数据集,我们从华山医院采集到了几位病人的数据:
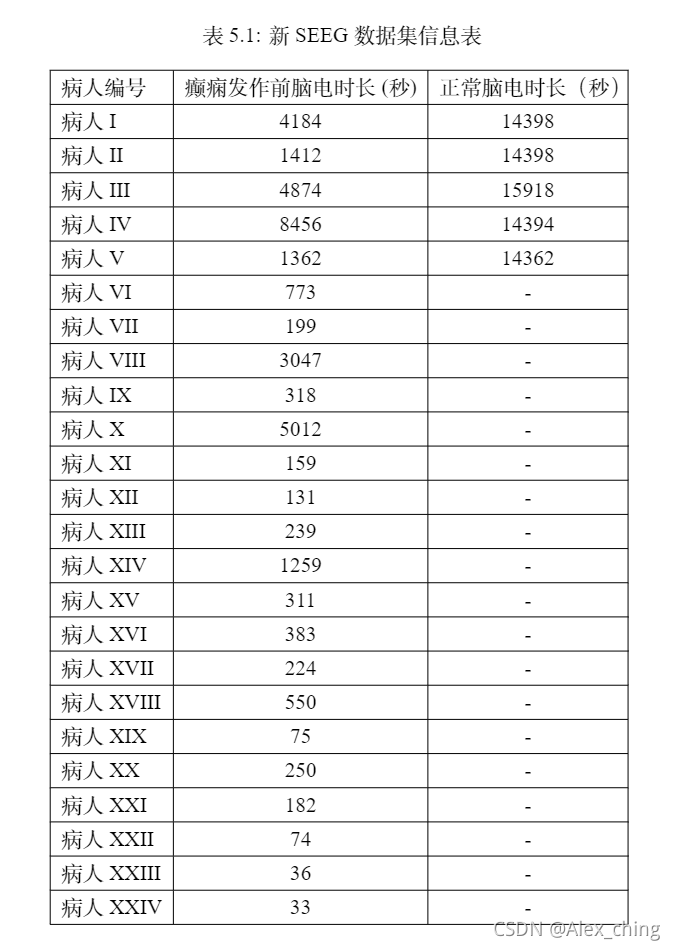
将其进行随机切位不等的片段如下:
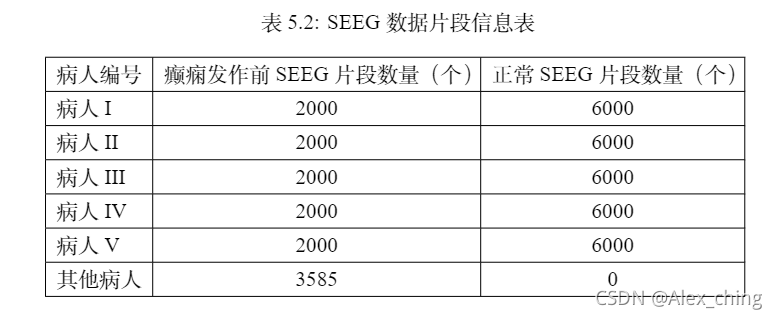
用留一法在不同病人的实验结果如下:
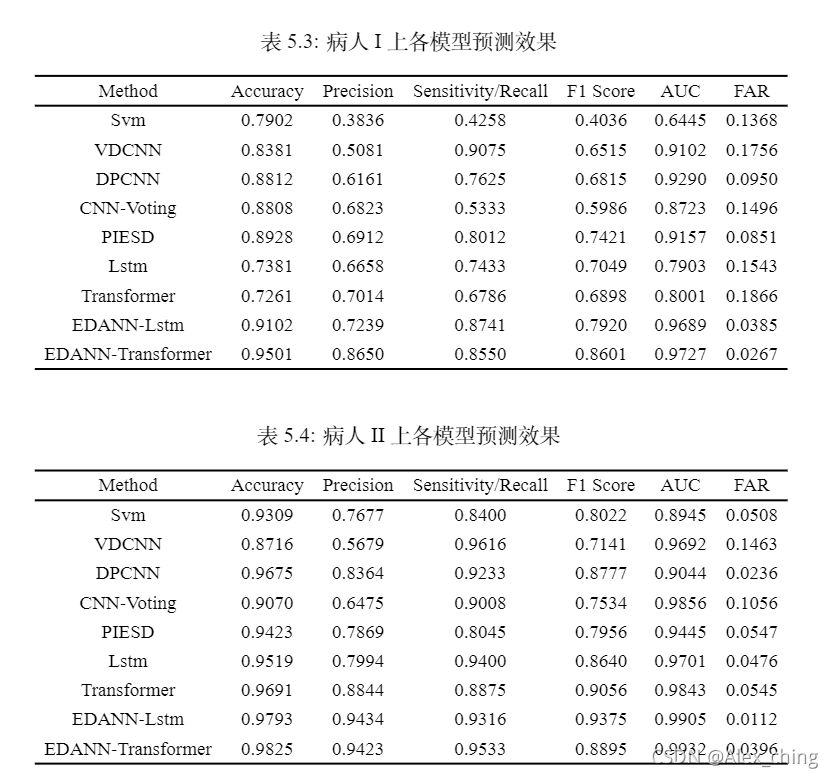

可以看到我们的模型取得最好的结果。
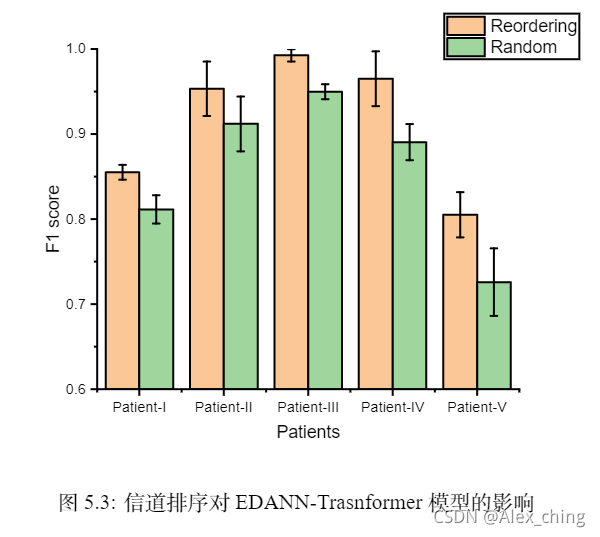
同时我们研究了信道排序和不排序的实验结果,这表明我们的数据预处理是合理的。
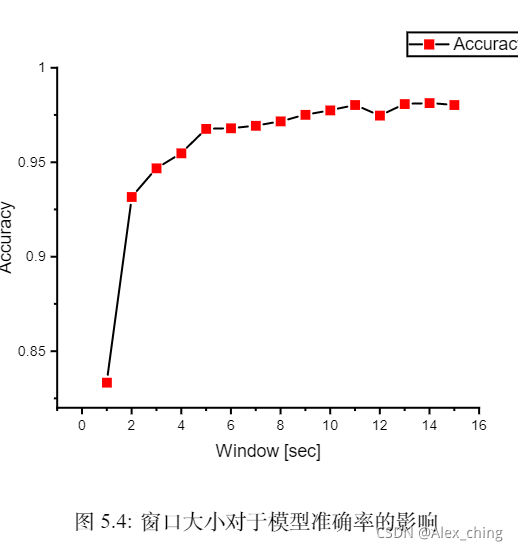
另外,我同时研究了窗口大小对于模型准确率的影响;
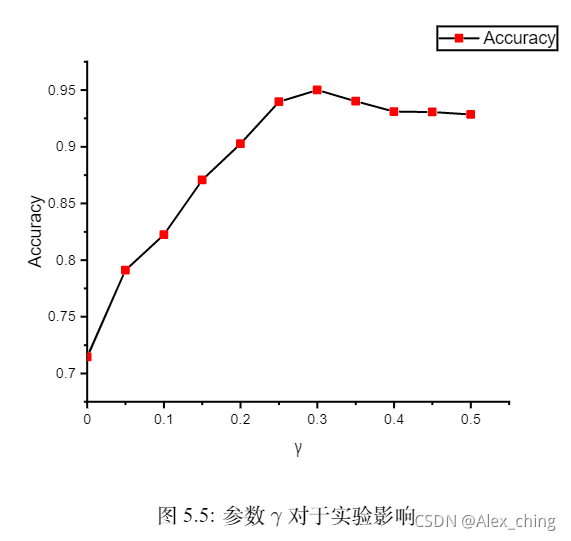
和超参对于模型的影响
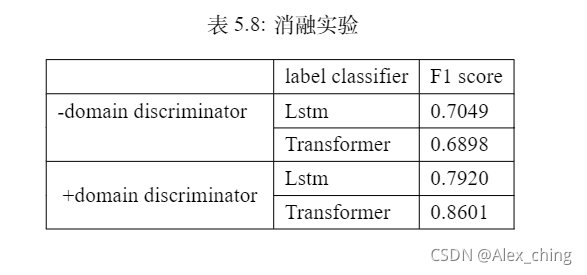
最后做了消融实验
以上是我的实验,如果想看细节,可以看我的论文:Epilepsy SEEG Data Classification Based On Domain Adversarial Learning
这篇关于基于对抗学习(域适应)的脑电信号SEEG/EEG分类算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




