本文主要是介绍YOLO算法改进Backbone系列之:HorNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在基于点积自注意的新空间建模机制的推动下,视觉变形器的最新进展在各种任务中取得了巨大成功。在本文中,我们展示了视觉变形器背后的关键要素,即输入自适应、长距离和高阶空间交互,也可以通过基于卷积的框架有效实现。我们提出了递归门控卷积(gnConv),通过门控卷积和递归设计实现高阶空间交互。gnConv可作为即插即用模块,用于改进各种视觉转换器和基于卷积的模型。在此基础上,我们构建了一个新的通用视觉骨干系列,命名为 HorNet。在ImageNet分类、COCO物体检测和ADE20K语义分割方面的大量实验表明,在整体架构和训练配置相似的情况下,HorNet的性能明显优于Swin Transformers和ConvNeXt。HorNet还显示出良好的可扩展性,可以适应更多的训练数据和更大的模型规模。除了在视觉编码器中的有效性,我们还证明了gnConv 可以应用于特定任务的解码器,并以更少的计算量持续提高密集预测性能。我们的研究结果表明,gnConv 可以成为视觉建模的一个新的基本模块,它有效地结合了视觉变换器和CNN的优点。
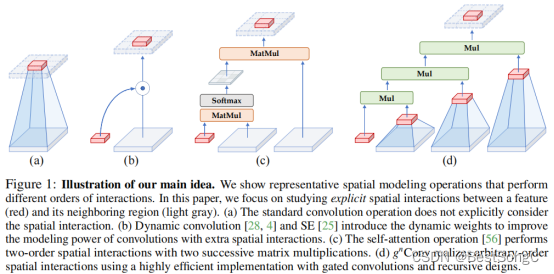
如下图所示是本文核心思想图解:通过这张图分析不同操作中特征 (红色块) 和它周围的区域 (灰色块) 的交互。(a) 普通卷积操作不考虑空间的信息交互。(b) 动态卷积操作借助动态权重,考虑周边的区域的信息交互,使得模型性能更强。© Self-attention 操作通过 query,key 和 value 之间的两个连续的矩阵乘法实现了二阶的空间信息交互。(d) 本文所提出的方法可以借助门控卷积和递归操作高效地实现任意阶数的信息交互。可视化建模的基本操作趋势表明,模型的表达能力可以通过增加空间相互作用的阶数来提高。
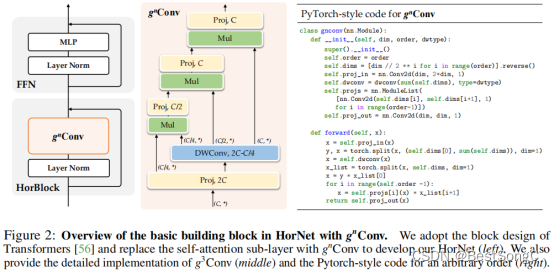
门控卷积结构如下图所示,括号中表示输出通道数。门控卷积就是首先通过两个卷积层来调整特征通道数。接着将深度可分离卷积的输出特征沿着特征分成多块,每一块与前一块交互的特征进一步进行逐元素相乘的方式进行交互,最终得到输出特征。这里递归就是不断地进行逐元素相乘操作,通过这种递归方式特征越在后面的特征高阶信息保存越多,这样在高阶中特征交互就会足够多
作者使用了典型 Transformer 网络的四阶段架构如下表所示,把 attention 替换为 gnConv;直接沿用了 SWIN 各个阶段 block 的数量,并额外在 stage2 加了一个 block 使整体复杂度接近,各个stage的block数是[2, 3, 18, 2];在每个stage中,gnConv空间阶数分别为[2,3,4,5],四个stage的通道数依次为[C, 2C, 4C, 8C]

在YOLOv5项目中添加模型作为Backbone使用的教程:
(1)将YOLOv5项目的models/yolo.py修改parse_model函数以及BaseModel的_forward_once函数
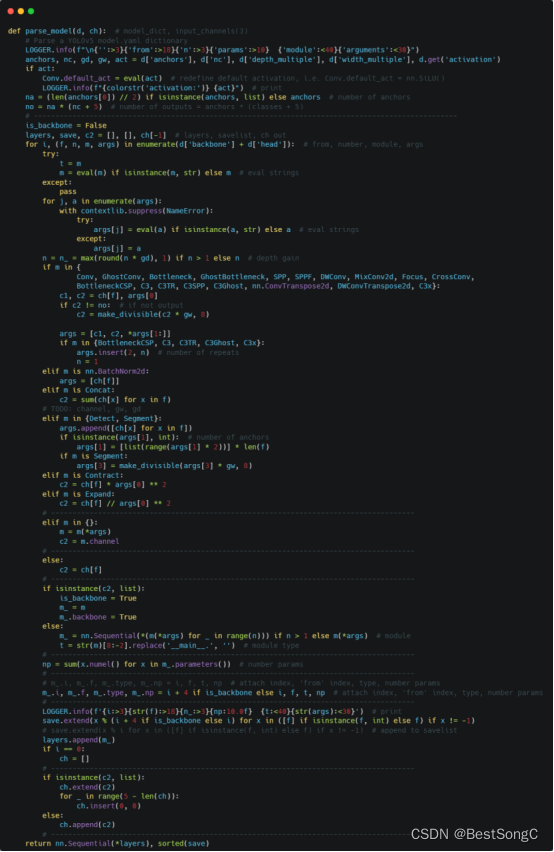
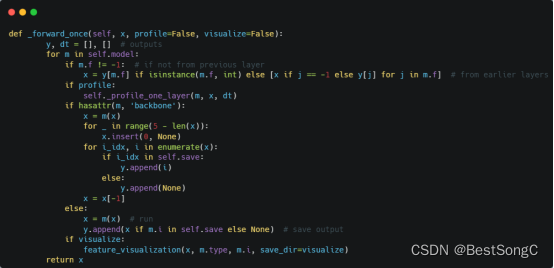
(2)在models/backbone(新建)文件下新建Hornet.py,添加如下的代码:

(3)在models/yolo.py导入模型并在parse_model函数中修改如下(先导入文件):
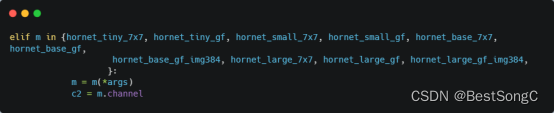
(4)在model下面新建配置文件:yolov5_hornet.yaml
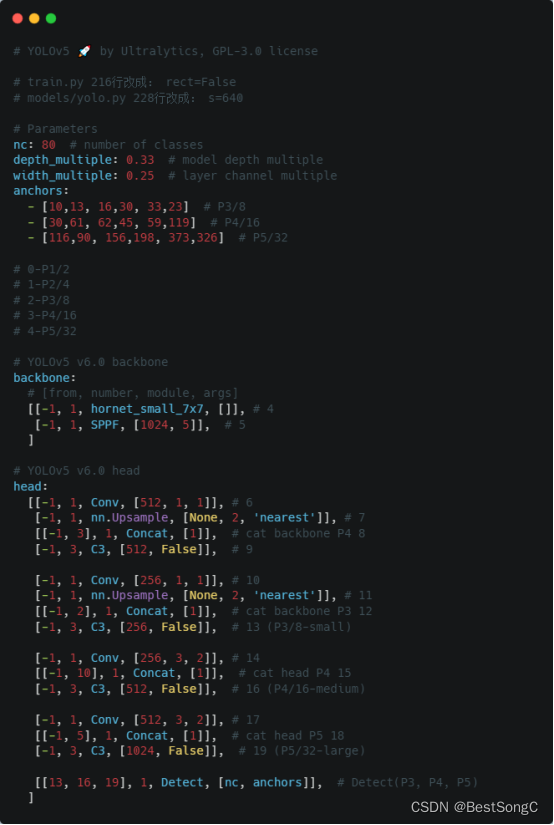
(5)运行验证:在models/yolo.py文件指定–cfg参数为新建的yolov5_hornet.yaml

这篇关于YOLO算法改进Backbone系列之:HorNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








