本文主要是介绍《Kubernetes部署篇:基于Kylin V10+ARM架构CPU使用containerd部署K8S 1.26.15集群(一主多从)》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总结:整理不易,如果对你有帮助,可否点赞关注一下?
更多详细内容请参考:企业级K8s集群运维实战
1、在当前实验环境中安装K8S1.25.14版本,出现了一个问题,就是在pod中访问百度网站,大概时间有10s多,这个时间太长了,尝试了各种办法,都解决不了,后面尝试安装了了1.26.15版本就没这个问题,很神奇,希望这个问题能帮到一些朋友,如果你也有遇到这个问题并有解决方案,可以告诉我,本人不胜感激!!!
2、此外在安装K8S1.26.15版本后,安装完calico v3.26.4后,测试dns,无法ping通百度,将control-plane节点和worker节点主机进行重启,就可以ping通,虽然重启解决了,但是不明白为什么?如果你能知道,并告知我,本人将非常感谢!
一、架构图
如下图所示:
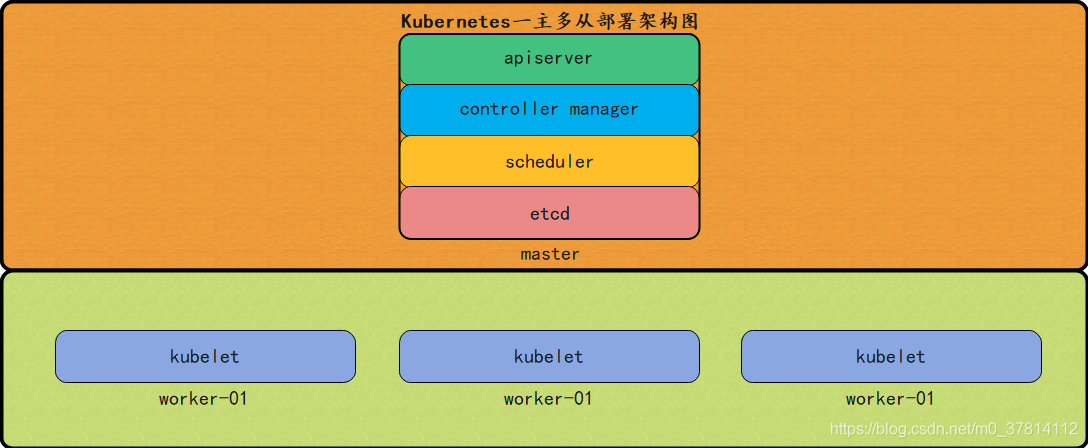
二、环境信息
1、资源下载
2、部署规划
| 主机名 | K8S版本 | 系统版本 | CPU架构 | 内核版本 | I IP地址 | 备注 |
|---|---|---|---|---|---|---|
| k8s-master-42 | 1.26.15 | Kylin Linux Advanced Server V10 | aarch64 | 4.19.90-17.5.ky10.aarch64 | 172.18.1.42 | control-plane节点 |
| k8s-worker-67 | 1.26.15 | Kylin Linux Advanced Server V10 | aarch64 | 4.19.90-17.5.ky10.aarch64 | 172.18.1.67 | worker节点 |
| k8s-worker-97 | 1.26.15 | Kylin Linux Advanced Server V10 | aarch64 | 4.19.90-17.5.ky10.aarch64 | 172.18.1.97 | worker节点 |
3、集群网段
| 宿主机 | 集群Pod网段 | 集群Service网段 |
|---|---|---|
| 172.18.1.0/24 | 10.48.0.0/16 | 10.96.0.0/16 |
4、基础软件版本
| 软件 | 版本 | 安装方式 |
|---|---|---|
| kubeadm | 1.26.15 | 二进制 |
| kubectl | 1.26.15 | 二进制 |
| kubelet | 1.26.15 | 二进制 |
| cri-containerd-cni | 1.7.2 | 二进制 |
| ipvsadm | 1.29 | yum |
| ipset | 7.3 | yum |
| conntrack | 1.4.4 | yum |
| socat | 1.7.3.2 | yum |
| ebtables | 2.0.10 | yum |
| sysstat | 12.1.6 | yum |
说明
1、cri-containerd-cni包包含containerd、runc、cni打工插件。安装containerd,需要同时安装runc及cni网络插件。 containerd不能直接操作容器,需要通过runc来运行容器。默认Containerd管理的容器仅有lo网络(无法访问容器之外的网络), 如果需要访问容器之外的网络则需要安装CNI网络插件。CNI(Container Network Interface) 是一套容器网络接口规范,用于为容器分配ip地址,通过CNI插件Containerd管理的容器可以访问容器之外的网络。
2、ipvsadm:这是一个用于管理Linux内核中的IP虚拟服务器(IPVS)的工具。它允许您配置和管理负载均衡、网络地址转换(NAT)和透明代理等功能。
3、ipset:这是一个用于管理Linux内核中的IP集合的工具。它允许您创建和管理IP地址、IP地址范围和端口号的集合,以便在防火墙规则中使用。
4、conntrack:这是一个用于连接跟踪的内核模块和工具。它允许您跟踪网络连接的状态和信息,如源IP地址、目标IP地址、端口号等。
5、socat(网络工具):这是一个用于在Linux系统中建立各种类型网络连接的工具。在Kubernetes网络中,socat可以 用于创建端口转发、代理和转发等网络连接。
6、ebtables(以太网桥规则管理工具):这是一个用于在Linux系统中管理以太网桥规则的工具。在Kubernetes中,ebtables 用于在网络分区中实现容器之间的隔离和通信。
7、sysstat:这是一个用于系统性能监控和报告的工具集。它包括一些实用程序,如sar、iostat和mpstat,用于收集和显示系统资源使用情况的统计信息。
5、K8S镜像
| K8S镜像 | calico镜像 |
|---|---|
| registry.k8s.io/kube-apiserver:v1.26.15 | docker.io/calico/cni:v3.26.4 |
| registry.k8s.io/kube-controller-manager:v1.26.15 | docker.io/calico/kube-controllers:v3.26.4 |
| registry.k8s.io/kube-scheduler:v1.26.15 | docker.io/calico/node:v3.26.4 |
| registry.k8s.io/kube-proxy:v1.26.15 | - |
| registry.k8s.io/pause:3.9 | - |
| registry.k8s.io/coredns/coredns:v1.9.3 | - |
| registry.k8s.io/etcd:3.5.10-0 | - |
6、k8s版本与calico版本对应关系
| calico版本 | calico yml文件下载 | 支持K8S版本 |
|---|---|---|
| v3.24.x | calico.yml | v1.22、v1.23、v1.24、v1.25 |
| v3.25.x | calico.yml | v1. |
这篇关于《Kubernetes部署篇:基于Kylin V10+ARM架构CPU使用containerd部署K8S 1.26.15集群(一主多从)》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






