本文主要是介绍网页抽取技术和算法与WebCollector,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
网页抽取技术和算法,持续更新。本文由WebCollector提供,转载请标明出处。
转自:http://blog.csdn.net/AJAXHu/article/details/48382381
- 网页抽取简介
- 基于正则表达式的网页抽取
- 基于CSS选择器的网页抽取
- 基于机器学习的网页抽取
一. 网页抽取简介
网页抽取在大多数情况下,指提取网页中的结构化数据。网页抽取技术近十几年方法和工具变化都较快。
常见的网页抽取方法有 :
- 基于正则表达式的网页抽取
- 基于CSS选择器的网页抽取
- 基于XPATH的网页抽取
- 基于机器学习的网页抽取
由于CSS选择器和XPATH都是网页DOM树的特征,切较为相似,本教程不介绍基于XPATH的网页抽取。本文会着重介绍基于机器学习的网页抽取。
二. 基于正则表达式的网页抽取
利用正则表达式进行网页抽取,是在html源码的基础上做字符串级别的检索。要详细了解如何利用正则表达式进行网页抽取,只要了解正则表达式的基本用法即可,与网页特征无关。
基于正则表达式的网页抽取有下面几个缺点:
- 正则表达式不直观,维护较为困难
- 对于复杂的页面,正则规则编写较为复杂
- 正则表达式是字符串级别的信息检索,并没有利用网页的特征(例如DOM树中的CSS选择器或XPATH)
由于上面这些缺点,我们不推荐使用正则表达式进行网页抽取。因此这里我们只举一个简单的例子演示正则抽取。
原网页为:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在html中我们描述了待抽取的内容。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
对于结构复杂的网页,正则表达式的设计往往较为困难,上面例子中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如果仍使用<div class="main">(.*?)</div>作为正则表达式抽取,抽取结果会变为<p>xxxxx</p><div>xxxxxx,这时就需要重新设计正则表达式,例如<div class="main">(.*?)</div>\s*<div class="foot">(程序里,双引号和\之前要加\进行转义。
三. 基于CSS选择器的网页抽取
浏览器在收到服务器返回的html源码后,会将网页解析为DOM树。CSS选择器(CSS Selector)是基于DOM树的特征,被广泛用于网页抽取。目前最流行的网页抽取组件Jsoup(Java)和BeautifulSoup(Python)都是基于CSS选择器的。
对于上面的例子:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用CSS选择器将大大提升代码的可读性:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
CSS选择器有标准的规范,但Jsoup(Java)和BeautifulSoup(python)这些组件并没有完全按照规范实现CSS选择器。因此在使用每种组件之前,最好阅读一下组件文档中对于CSS选择器的描述。
Jsoup对于CSS选择器实现较好,如希望了解CSS选择器的使用,建议阅读Jsoup的CSS选择器规范文档。
浏览器中的JavaScript是直接支持CSS选择器的,如果电脑里装有firefox或者chrome,打开浏览器,按F12(调出开发者界面),随便打开一个网页,选择其中的控制台(Console)标签页,在Console里输入
- 1
- 1
回车后,发现输出了页面中所有的超链接,document.querySelectorAll(CSS选择器)获取页面中所有满足CSS选择器的元素,放到一个数组中返回。
如果只希望获取第一个满足CSS选择器的元素,可以使用document.querySelector(CSS选择器)这个方法。
浏览器js中的CSS选择器与Jsoup(Java)和BeautifulSoup(Python)中实现的CSS选择器有细微差别,不过大体相同。
四. 基于机器学习的网页抽取
基于正则或CSS选择器(或xpath)的网页抽取都基于属于基于包装器(wrapper)的网页抽取,这类抽取算法的通病就在于,对于不同结构的网页,要制定不同的抽取规则。如果一个舆情系统需要监控10000个异构网站,就需要编写并维护10000套抽取规则。从2000年左右就开始有人研究如何用机器学习的方法,让程序在不需要人工制定规则的情况下从网页中提取所需的信息。
从目前的科研成果看,基于机器学习的网页抽取的重心偏向于新闻网页内容自动抽取,即输入一个新闻网页,程序可以自动输出新闻的标题、正文、时间等信息。新闻、博客、百科类网站包含的结构化数据较为单一,基本都满足{标题,时间,正文}这种结构,抽取目标很明确,机器学习算法也较好设计。但电商、求职等类型的网页中包含的结构化数据非常复杂,有些还有嵌套,并没有统一的抽取目标,针对这类页面设计机器学习抽取算法难度较大。
本节主要描述如何设计机器学习算法抽取新闻、博客、百科等网站中的正文信息,后面简称为网页正文抽取(Content Extraction)。
基于机器学习的网页抽取算法大致可以分为以下几类:
- 基于启发式规则和无监督学习的网页抽取算法
- 基于分类器的网页抽取算法
- 基于网页模板自动生成的网页抽取算法
三类算法中,第一类算法是最好实现的,也是效果最好的。
我们简单描述一下三类算法,如果你只是希望在工程中使用这些算法,只要了解第一类算法即可。
下面会提到一些论文,但请不要根据论文里自己的实验数据来判断算法的好坏,很多算法面向早期网页设计(即以表格为框架的网页),还有一些算法的实验数据集覆盖面较窄。有条件最好自己对这些算法进行评测。
4.1 基于启发式规则和无监督学习的网页抽取算法
基于启发式规则和无监督学习的网页抽取算法(第一类算法)是目前最简单,也是效果最好的方法。且其具有较高的通用性,即算法往往在不同语种、不同结构的网页上都有效。
早期的这类算法大多数没有将网页解析为DOM树,而是将网页解析为一个token序列,例如对于下面这段html源码:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
程序将其转换为token序列:
- 1
- 1
早期有一种MSS算法(Maximum Subsequence Segmentation)以token序列为基础,算法有多个版本,其中一个版本为token序列中的每一个token赋予一个分数,打分规则如下:
- 一个标签给-3.25分
- 一个文本给1分
根据打分规则和上面的token序列,我们可以获取一个分数序列:
- 1
- 1
MSS算法认为,找出token序列中的一个子序列,使得这个子序列中token对应的分数总和达到最大,则这个子序列就是网页中的正文。从另一个角度来理解这个规则,即从html源码字符串中找出一个子序列,这个子序列应该尽量包含较多的文本和较少的标签,因为算法中给标签赋予了绝对值较大的负分(-3.25),为文本赋予了较小的正分(1)。
如何从分数序列中找出总和最大的子序列可以用动态规划很好地解决,这里就不给出详细算法,有兴趣可以参考《Extracting Article Text from the Web with Maximum Subsequence Segmentation》这篇论文,MSS算法的效果并不好,但本文认为它可以代表早期的很多算法。
MSS还有其他的版本,我们上面说算法给标签和文本分别赋予-3.25和1分,这是固定值,还有一个版本的MSS(也在论文中)利用朴素贝叶斯的方法为标签和文本计算分数。虽然这个版本的MSS效果有一定的提升,但仍不理想。
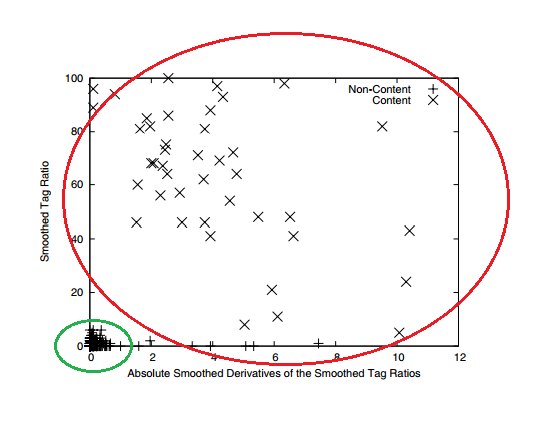
无监督学习在第一类算法中也起到重要作用。很多算法利用聚类的方法,将网页的正文和非正文自动分为2类。例如在《CETR - Content Extraction via Tag Ratios》算法中,网页被切分为多行文本,算法为每行文本计算2个特征,分别是下图中的横轴和纵轴,红色椭圆中的单元(行),大多数是网页正文,而绿色椭圆中包含的单元(行),大多数是非正文,使用k-means等聚类方法,就可以很好地将正文和非正文分为两类,然后再设计一些启发式算法,即可区分两类中哪一类是正文,哪一类是非正文。
早期的算法往往将token序列、字符序列作为计算特征的单元,从某种意义来说,这破坏了网页的结构,也没有充分利用网页的特征。在后来的算法中,很多使用DOM树的Node作为特征计算的基本单元,例如《Web news extraction via path ratios》、《Dom based content extraction via text density》,这些算法仍然是利用启发式规则和无监督学习,由于使用DOM树的Node作为特征计算的基本单元,使得算法可以获取到更好、更多的特征,因此可以设计更好的启发式规则和无监督学习算法,这些算法在抽取效果上,往往远高于前面所述的算法。由于在抽取时使用DOM树的Node作为单元,算法也可以较容易地保留正文的结构(主要是为了保持网页中正文的排版)。
我们在WebCollector(1.12版本开始)中,实现了一种第一类算法,可以到官网直接下载源码使用。
4.2 基于分类器的网页抽取算法(第二类机器学习抽取算法)
实现基于分类器的网页抽取算法(第二类算法),大致流程如下:
- 找几千个网页作为训练集,对网页的正文和非正文(即需要抽取和不需要抽取的部分)进行人工标注。
- 设计特征。例如一些算法将DOM树的标签类型(div,p,body等)作为特征之一(当然这是一个不推荐使用的特征)。
- 选择合适的分类器,利用特征进行训练。
对于网页抽取,特征的设计是第一位的,具体使用什么分类器有时候并不是那么重要。在使用相同特征的情况下,使用决策树、SVM、神经网络等不同的分类器不一定对抽取效果造成太大的影响。
从工程的角度来说,流程中的第一步和第二步都是较为困难的。训练集的选择也很有讲究,要保证在选取的数据集中网页结构的多样性。例如现在比较流行的正文结构为:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果训练集中只有五六个网站的页面,很有可能这些网站的正文都是上面这种结构,而恰好在特征设计中,有两个特征是:
- 节点标签类型(div,p,body等)
- 孩子节点标签类型频数(即孩子节点中,div有几个,p有几个…)
假设使用决策树作为分类器,最后的训练出的模型很可能是:
- 1
- 1
虽然这个模型在训练数据集上可以达到较好的抽取效果,但显而易见,有很多网站不满足这个规则。因此训练集的选择,对抽取算法的效果有很大的影响。
网页设计的风格一致在变,早期的网页往往利用表格(table)构建整个网页的框架,现在的网页喜欢用div构建网页的框架。如果希望抽取算法能够覆盖较长的时间段,在特征设计时,就要尽量选用那些不易变化的特征。标签类型是一个很容易变化的特征,随着网页设计风格的变化而变化,因此前面提到,非常不建议使用标签类型作为训练特征。
上面说的基于分类器的网页抽取算法,属于eager learning,即算法通过训练集产生了模型(如决策树模型、神经网络模型等)。与之对应的lazy learning,即事先不通过训练集产生模型的算法,比较有名的KNN就是属于lazy learning。
一些抽取算法借助KNN来选择抽取算法,可能听起来有些绕,这里解释一下。假设有2种抽取算法A、B,有3个网站site1,site2,site3。2种算法在3个网站上的抽取效果(这里用0%-100%的一个数表示,越大说明越好)如下:
| 网站 | A算法抽取效果 | B算法抽取效果 |
|---|---|---|
| site1 | 90% | 70% |
| site2 | 80% | 85% |
| site3 | 60% | 87% |
可以看出来,在site1上,A算法的抽取效果比B好,在site2和site3上,B算法的抽取效果较好。在实际中,这种情况很常见。所以有些人就希望设计一个分类器,这个分类器不是用来分类正文和非正文,而是用来帮助选择抽取算法。例如在这个例子中,分类器在我们对site1中网页进行抽取时,应该告诉我们使用A算法可以获得更好的效果。
举个形象的例子,A算法在政府类网站上抽取效果较好,B算法在互联网新闻网站上抽取效果较好。那么当我对政府类网站进行抽取时,分类器应该帮我选择A算法。
这个分类器的实现,可以借助KNN算法。事先需要准备一个数据集,数据集中有多个站点的网页,同时需要维护一张表,表中告诉我们在每个站点上,不同抽取算法的抽取效果(实际上只要知道在每个站点上,哪个算法抽取效果最好即可)。当遇到一个待抽取的网页,我们将网页和数据集中所有网页对比(效率很低),找出最相似的K个网页,然后看着K个网页中,哪个站点的网页最多(例如k=7,其中有6个网页都是来自CSDN新闻),那么我们就选择这个站点上效果最好的算法,对这个未知网页进行抽取。
4.3 基于网页模板自动生成的网页抽取算法
基于网页模板自动生成的网页抽取算法(第三类算法)有很多种。这里例举一种。在《URL Tree: Efficient Unsupervised Content Extraction from Streams of Web Documents》中,用多个相同结构页面(通过URL判断)的对比,找出其中异同,页面间的共性的部分是非正文,页面间差别较大的部分有可能是正文。这个很好理解,例如在一些网站中,所有的网页页脚都相同,都是备案信息或者版权申明之类的,这是页面之间的共性,因此算法认为这部分是非正文。而不同网页的正文往往是不同的,因此算法识别出正文页较容易。这种算法往往并不是针对单个网页作正文抽取,而是收集大量同构网页后,对多个网页同时进行抽取。也就是说,并不是输入一个网页就可以实时进行抽取。
注:本文尚在更新中。本文由WebCollector提供,转载请标明出处。
转自:http://blog.csdn.net/AJAXHu/article/details/48493107
WebCollector自2.10版起加入新闻网页正文自动提取功能(与hfut-dmic的ContentExtractor项目合并)。
WebCollector的正文抽取API都被封装为ContentExtractor类的静态方法。
可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在Element)。
正文抽取效果指标 :
- 比赛数据集CleanEval P=93.79% R=86.02% F=86.72%
- 常见新闻网站数据集 P=97.87% R=94.26% F=95.33%
- 算法无视语种,适用于各种语种的网页
标题抽取和日期抽取使用简单启发式算法,并没有像正文抽取算法一样在标准数据集上测试。
源码可在https://github.com/CrawlScript/WebCollector中下载,也可在https://github.com/CrawlScript/WebCollector中下载webcollector-version-bin.zip,解压后导入所有jar包。
需要了解的两个类 :
- ContentExtractor : 封装了正文抽取算法和正文抽取的API,正文抽取API都被封装为ContentExtractor类的静态方法
- News : 结构化新闻对应的模型
DEMO(TutorialContentExtractor.java)如下 :
import cn.edu.hfut.dmic.contentextractor.ContentExtractor;
import cn.edu.hfut.dmic.contentextractor.News;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;/*** 本教程演示了从WebCollector 2.10起添加的新闻网页正文自动提取功能** @author hu*/
public class TutorialContentExtractor {/*输入HTML,输出制定网页结构化信息*/public static void demo1() throws Exception {String url = "http://www.huxiu.com/article/121959/1.html";HttpRequest request = new HttpRequest(url);String html = request.getResponse().getHtmlByCharsetDetect();News news = ContentExtractor.getNewsByHtml(html, url);System.out.println(news);}/*输入URL,输出制定网页结构化信息*/public static void demo2() throws Exception {String url = "http://www.huxiu.com/article/121959/1.html";News news = ContentExtractor.getNewsByUrl(url);System.out.println(news);}/*输入HTML,输出制定网页的正文*/public static void demo3() throws Exception {String url = "http://www.huxiu.com/article/121959/1.html";HttpRequest request = new HttpRequest(url);String html = request.getResponse().getHtmlByCharsetDetect();String content = ContentExtractor.getContentByHtml(html, url);System.out.println(content);//也可抽取网页正文所在的Element//Element contentElement = ContentExtractor.getContentElementByHtml(html, url);//System.out.println(contentElement);}/*输入URL,输出制定网页的正文*/public static void demo4() throws Exception {String url = "http://www.huxiu.com/article/121959/1.html";String content = ContentExtractor.getContentByUrl(url);System.out.println(content);//也可抽取网页正文所在的Element//Element contentElement = ContentExtractor.getContentElementByUrl(url);//System.out.println(contentElement);}public static void main(String[] args) throws Exception {demo1();//demo2();//demo3();//demo4();}
}这篇关于网页抽取技术和算法与WebCollector的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







