本文主要是介绍ML在骨科手术术前、书中、术后方法应用综述【含数据集】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
达芬奇V手术机器人

近年来,人工智能(AI)彻底改变了人们的生活。人工智能早就在外科领域取得了突破性进展。然而,人工智能在骨科中的应用研究尚处于探索阶段。
本文综述了近年来深度学习和机器学习应用于骨科图像检测的最新成果,描述了其贡献、优势和不足。以及未来每项研究的改进方向。
同时对比传统骨科手术及AI尤其是ML在骨科手术中的现状、优势、前景。
最后总结局限性并提出解决方法。
Proj:202404 CMC; Group-2024 CMC
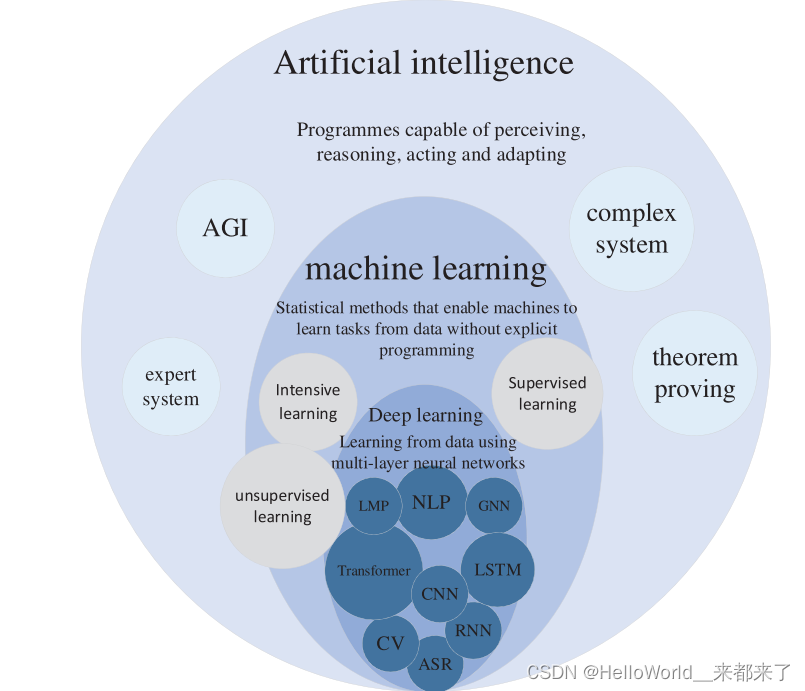
AI框架
1、AI应用于骨科检测
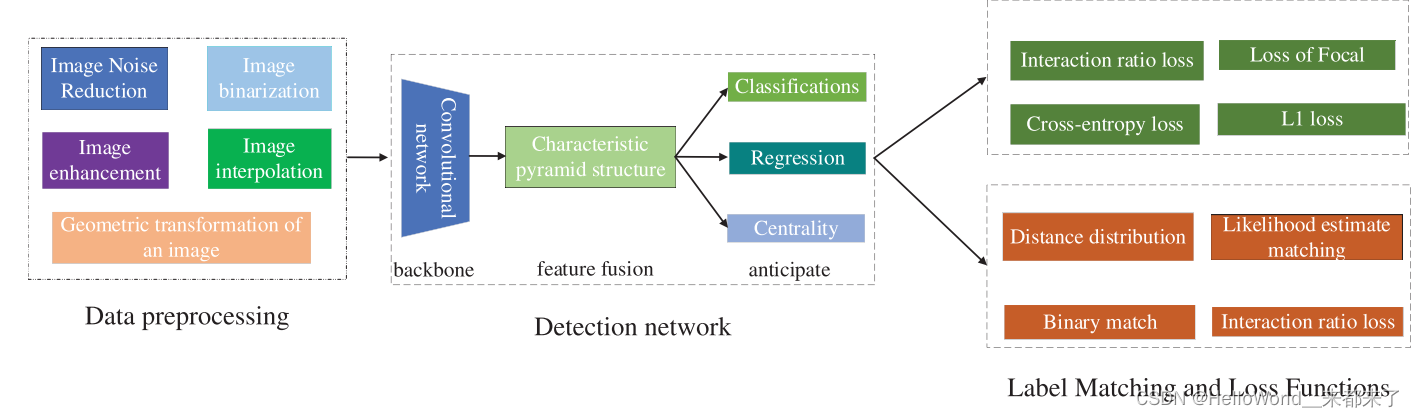
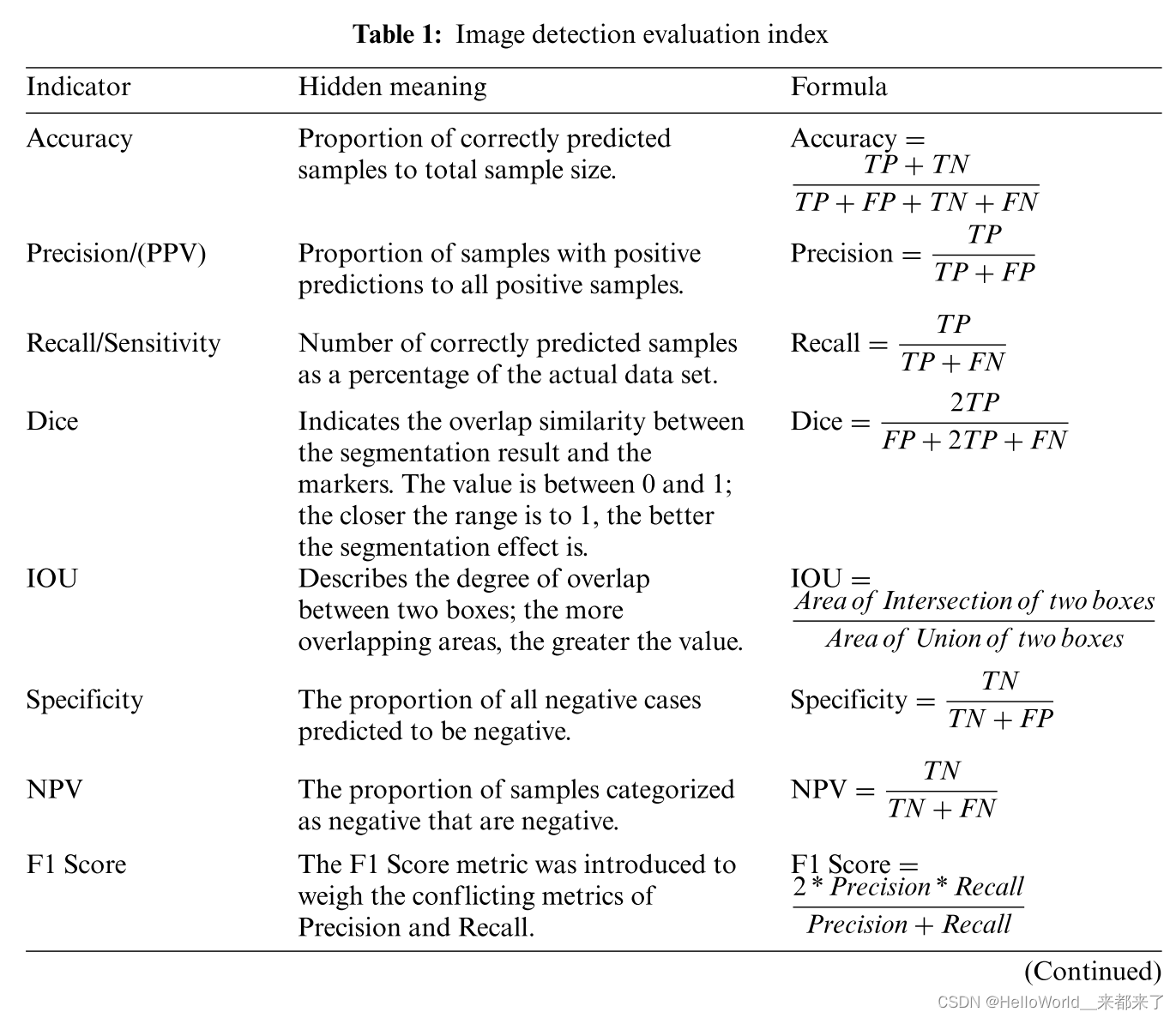
1.1 DL在骨科检测中的应用、评价指标、常用数据集和常用模型
这篇关于ML在骨科手术术前、书中、术后方法应用综述【含数据集】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








