本文主要是介绍R数据分析:生存分析的做法与解释续,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天更新续文,上篇文章写了生存曲线的画法,但是留了一个问题没有解决,就是Kaplan-Meier生存曲线实际上仅仅把病人分为两组做了生存率随时间的比较,但是它并没有考虑协变量。R数据分析:生存分析的做法和结果解释
那么,我们做研究的时候,你发现了两个组的生存情况不一样,是不是下一步你就要想看看到底是那些因素影响了我们的生存情况。今天的文章就尝试着解决这么样问题。
问题描述
我们今天要关注的问题变了,我们会想要探讨很多因素造成的病人生存情况的差异:
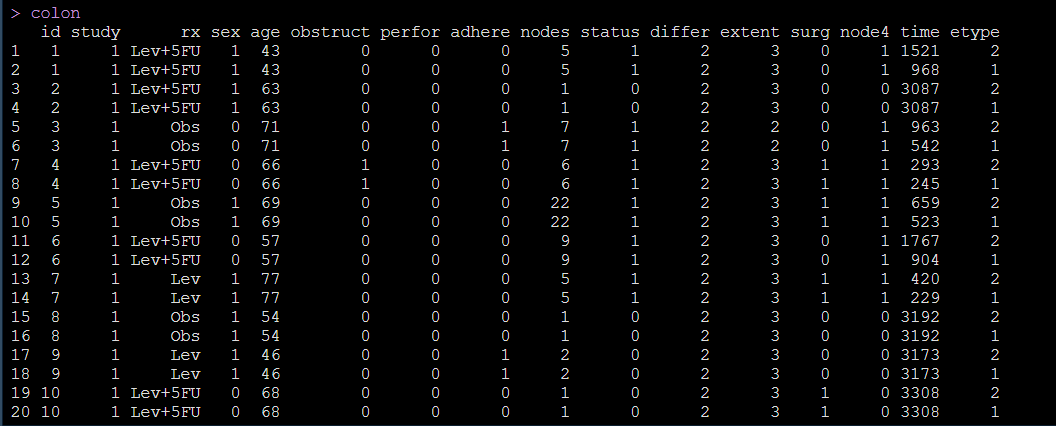
比如,我们今天想来探究一下究竟是哪些因素会影响结肠癌患者的生存情况,我们的备选因素有3个,分别是性别sex,治疗方法rx和癌肿附着情况adhere(是否附着到其他器官,2分类变量)。
那么数据集依然是survival包自带的colon数据集。
对于我们的研究问题,我可以很自然地想要做亚组分析,穷尽所有亚组来看差异,首先我们依然用Kaplan-Meier方法拟合生存曲线:
require("survival")
fit2 <- survfit( Surv(time, status) ~ sex + rx + adhere,data = colon )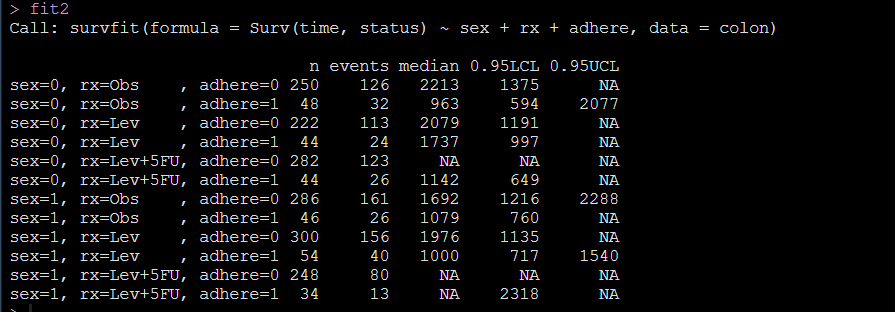
输出其实挺混乱的,我们依然可视化看看:
ggsurv <- ggsurvplot(fit2, fun = "event", conf.int = TRUE,ggtheme = theme_bw())ggsurv$plot +theme_bw() + theme (legend.position = "right")+facet_grid(rx ~ adhere)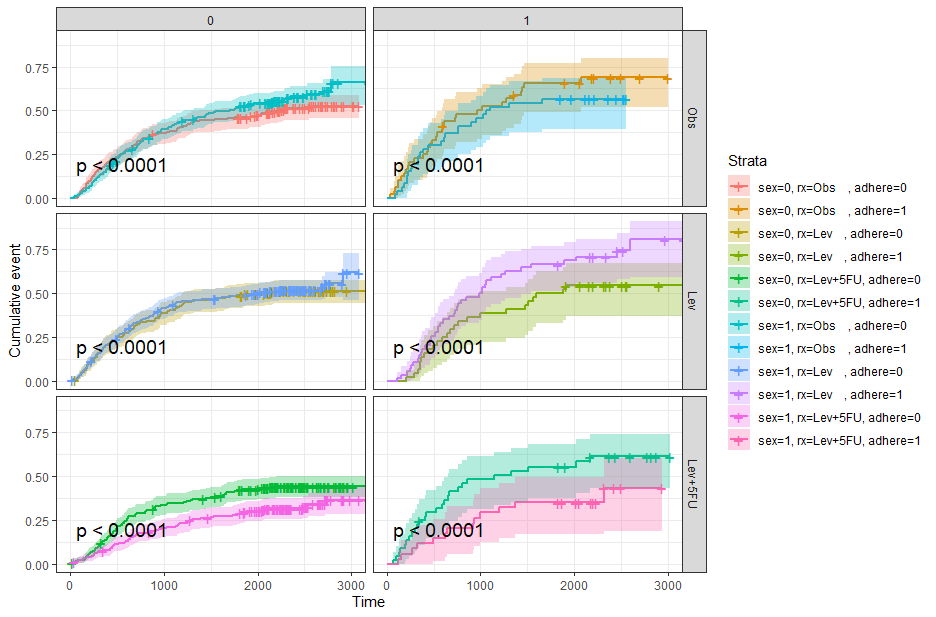
通过亚组分析的结果我们可以知道男女的生存情况在所有情况下都有差异,但是局限性在于我们还是不能知道不同的治疗方法或者癌肿附着是不是会影响病人的生存,因为我们的图都是在分组展示不同性别的差异。
当然了,你可以改公式自己再跑跑看,但这不是我们理想的方法。
风险比例模型
The Cox proportional-hazards model (Cox, 1972) is essentially a regression model commonly used statistical in medical research for investigating the association between the survival time of patients and one or more predictor variables.
Cox回归又称为比例风险模型,Cox回归比寿命表法和Kaplan-Meier法的应用范围更广,它能够同时考虑多个自变量对生存时间分布的影响。这个就是它最重要的优点。
想理解这个模型,必须要理解风险函数(上篇文章有提)Cox风险比例模型的基本形式如下:

上面的式子,一句话就是:t时间的风险等于基线风险乘以所有预测变量造成的风险的指数幂。上面式子做一个简单的数学变换就可以得到以lnHR为因变量,自变量为研究变量的线性组合的形式:

那么,写到这儿,大家肯定就知道了风险比例模型中自变量系数的解释,就是自变量每改变一个单位,风险比的自然对数的改变量。
那么具体到我们的例子,我们可以做一个风险比例模型瞅瞅:
fit.coxph <- coxph(Surv(time, status) ~ sex + rx + adhere, data = colon)
summary(fit.coxph)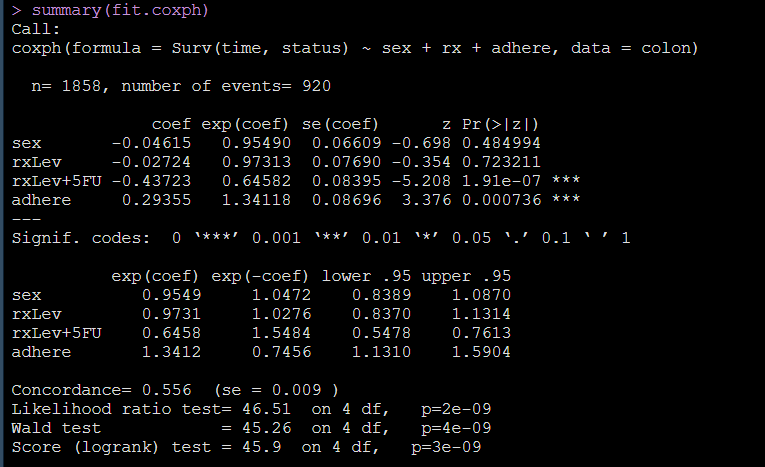
从输出结果看性别对死亡风险没有显著影响,图中的两种治疗方案相对于参照组都可以降低死亡风险,癌肿附着会增加死亡风险。
具体解释为:相对于观察组,施加rxlev治疗和relev+5FU治疗的病人发生结局(死亡)的风险会分别是基线风险的0.97和0.64,有癌肿附着的病人发生结局(死亡)的风险会是基线的1.34倍。
我们还可以画出变量对死亡风险影响的森林图:
ggforest(fit.coxph, data = colon)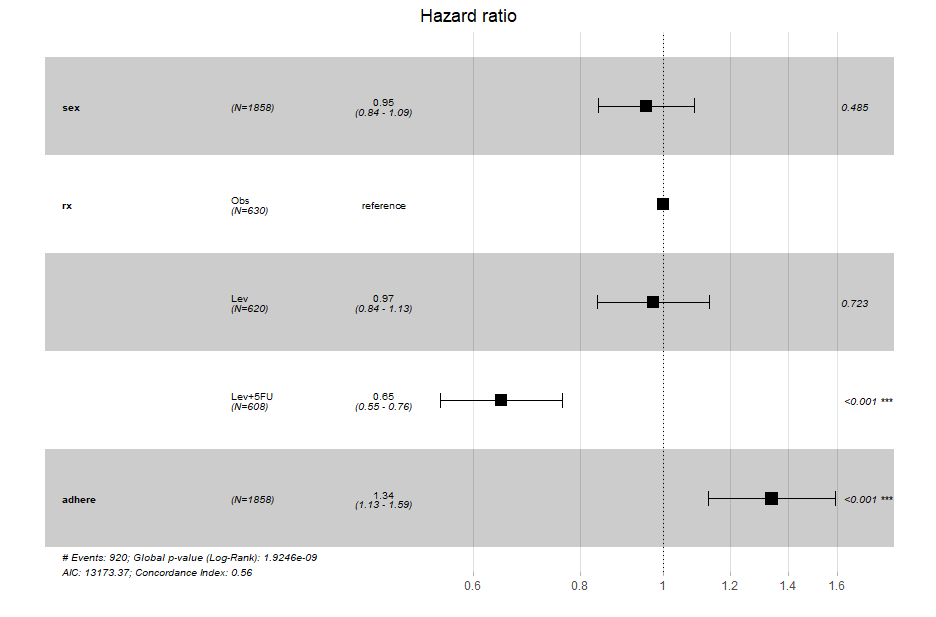
当然了这个森林图对我们这个例子并没有啥用哈,仅供看官一乐。
小结
今天主要给大家写了Cox风险比例模型的做法和解释,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、论文、报告、考试等发愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供最好的,最详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取最详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #reports, #composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
往期内容:
R数据分析:混合效应模型实例
R数据分析:倾向性评分匹配实例操作
R数据分析:一个真实的数据分析实例
R数据分析:ROC曲线与模型评价实例
R数据分析:线性回归的做法和优化实例
这篇关于R数据分析:生存分析的做法与解释续的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





