本文主要是介绍使用阿里云试用Elasticsearch学习:使用内置模型 lang_ident_model_1 创建管道并使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文档:https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-deploy-model.html
部署刚刚下载好的内置模型

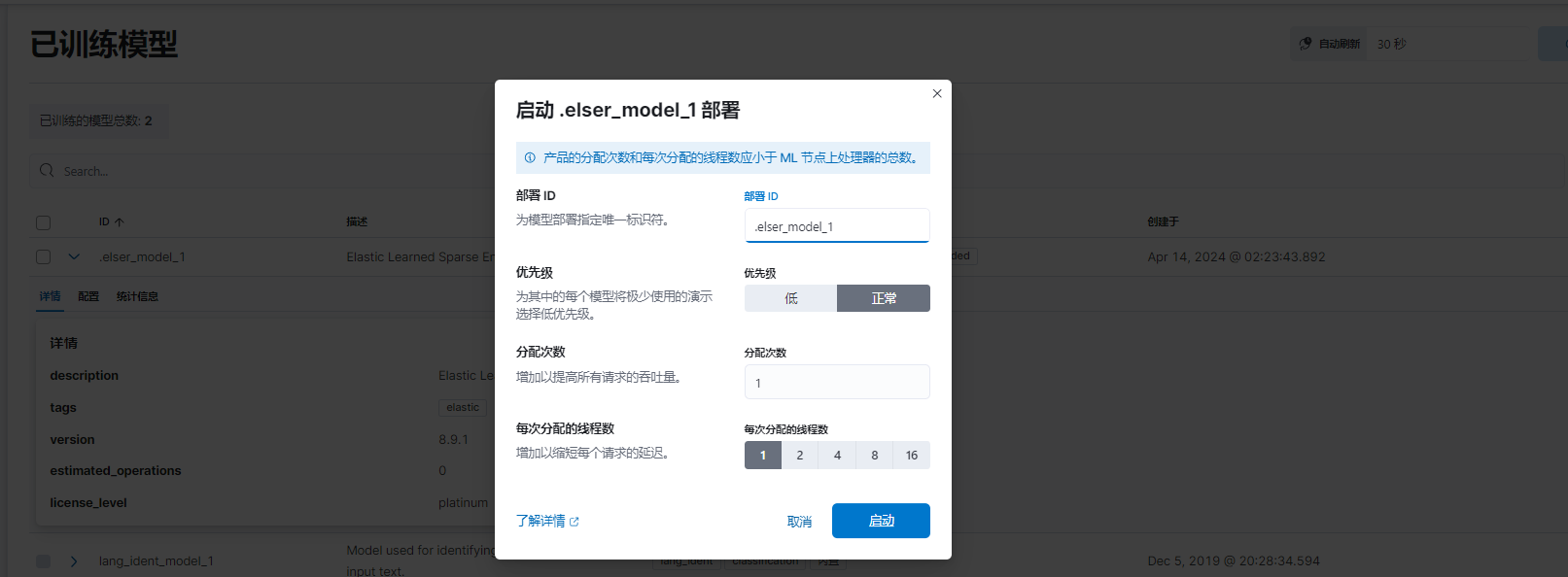
部署内存不够用
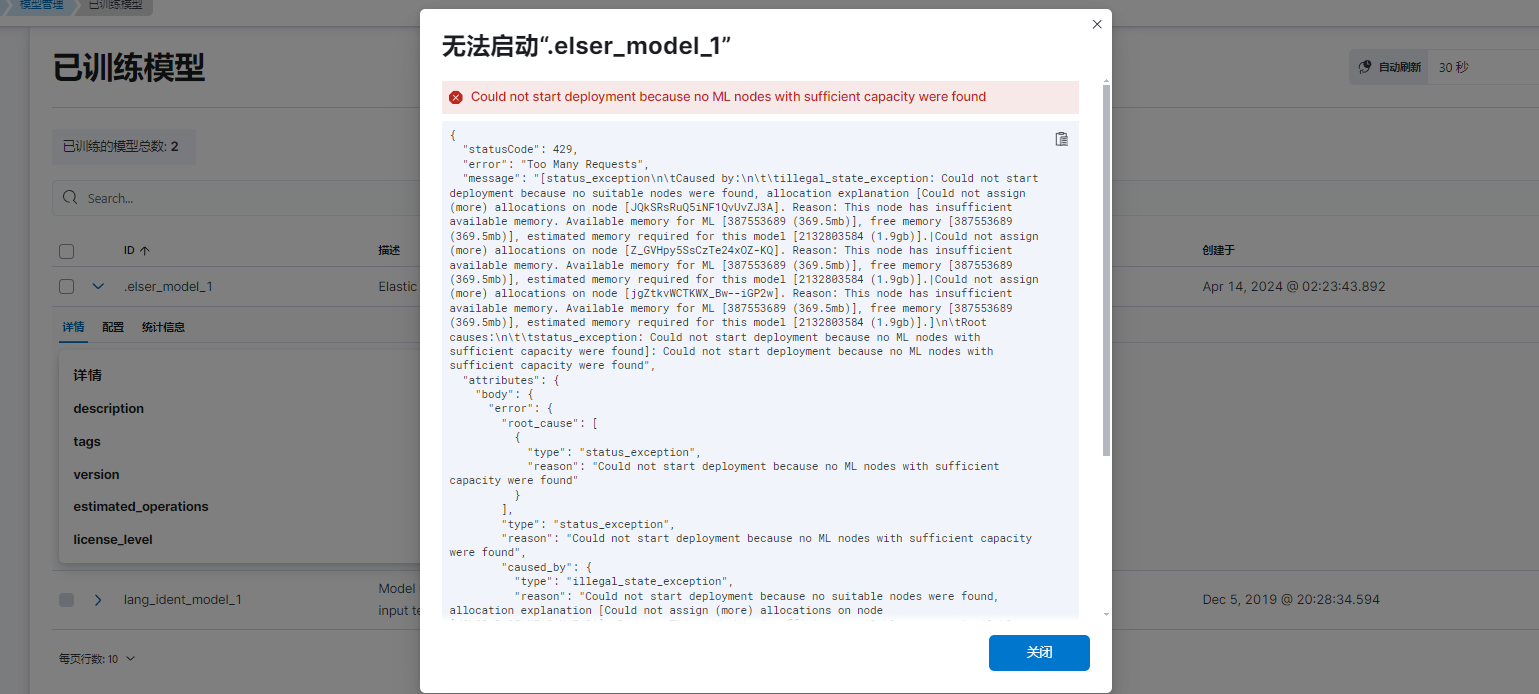
还得花钱,拉几把倒吧。就用自带的吧。
测试模型
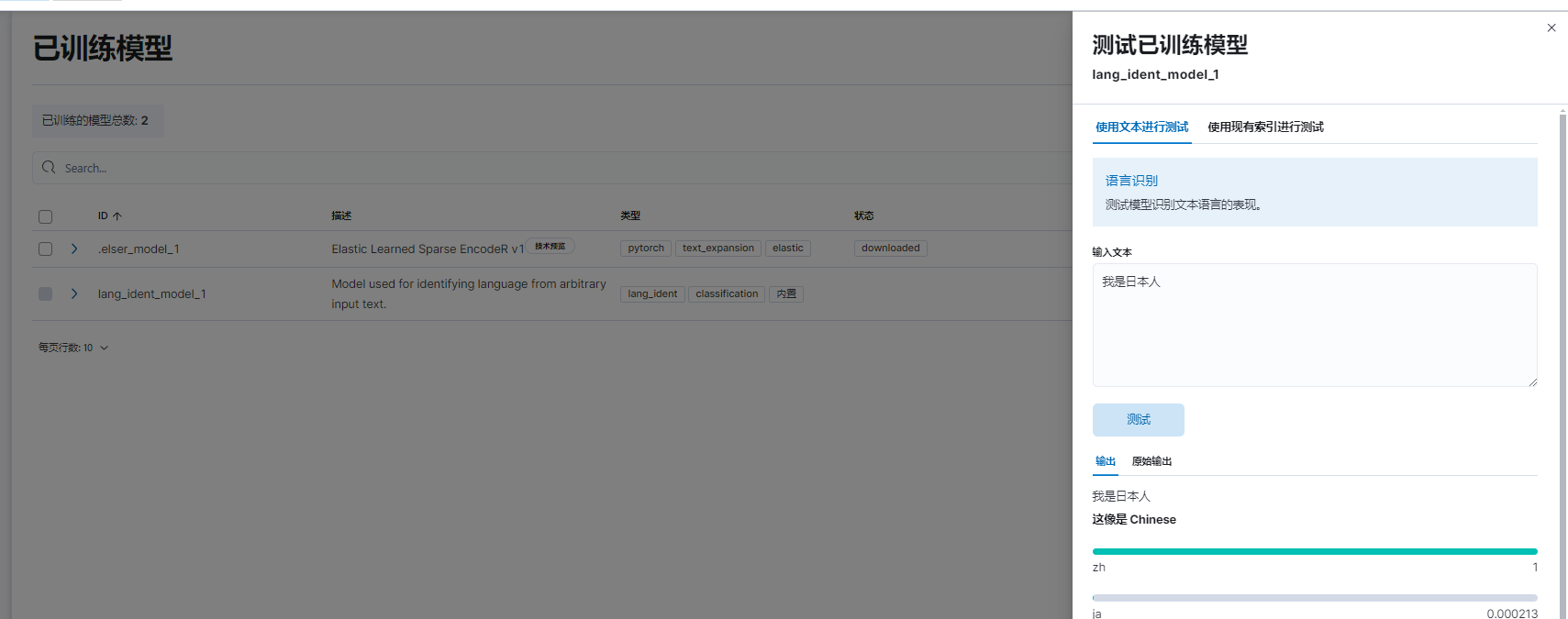
POST _ml/trained_models/lang_ident_model_1/_infer
{"docs":[{"text": "The fool doth think he is wise, but the wise man knows himself to be a fool."}]
}
以下是高概率预测英语的结果。
{"inference_results": [{"predicted_value": "en","prediction_probability": 0.9999658805366392,"prediction_score": 0.9999658805366392}]
}
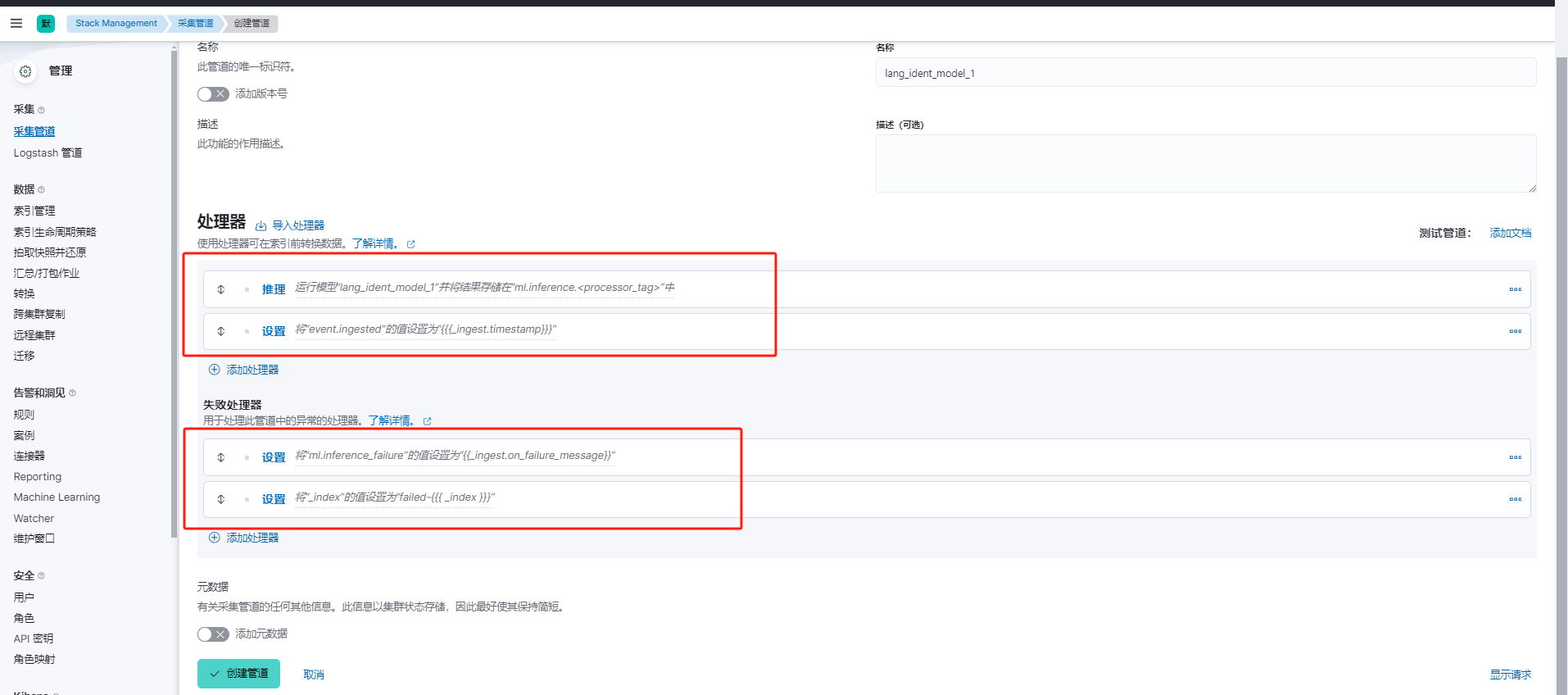
创建管道
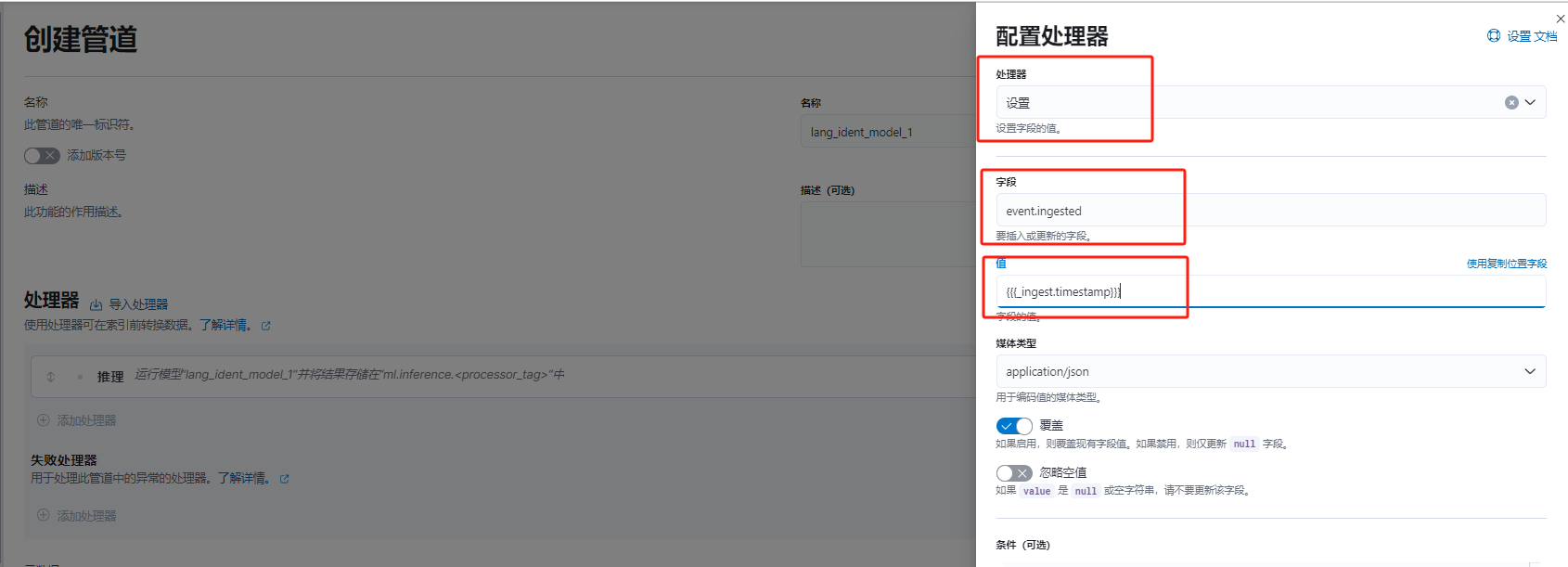
添加处理器
reference 推理
# Field map
{"message": "text"
}
# Inference configuration
{"classification":{"num_top_classes":5}
}

set 设置
# field
event.ingested
# value
{{{_ingest.timestamp}}}
失败处理器
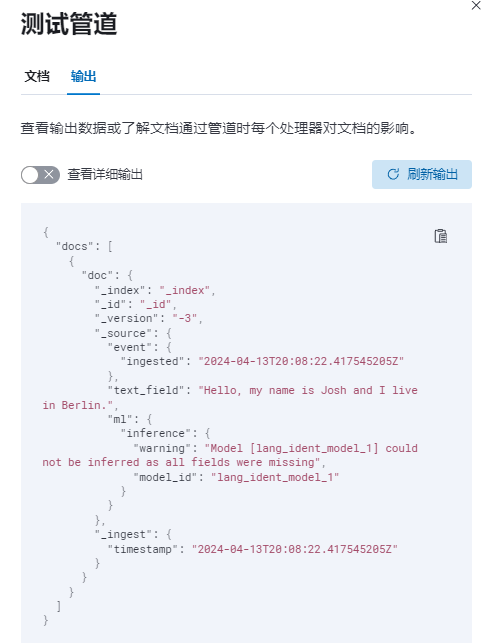
测试
[{"_source": {"text_field":"Hello, my name is Josh and I live in Berlin."}}
]
[{"_source":{"message":"Sziasztok! Ez egy rövid magyar szöveg. Nézzük, vajon sikerül-e azonosítania a language identification funkciónak? Annak ellenére is sikerülni fog, hogy a szöveg két angol szót is tartalmaz."}}
]

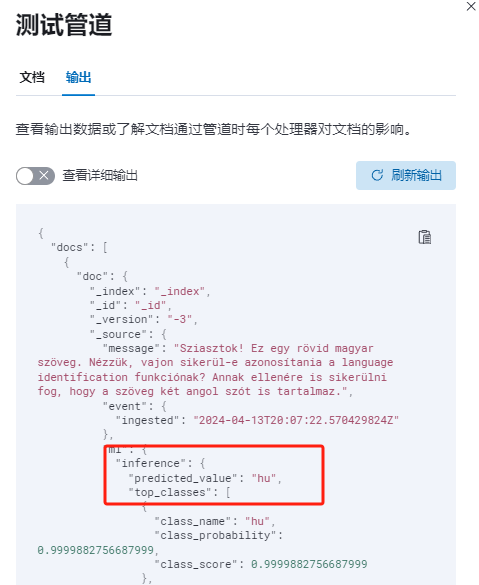
测试没问题,创建管道
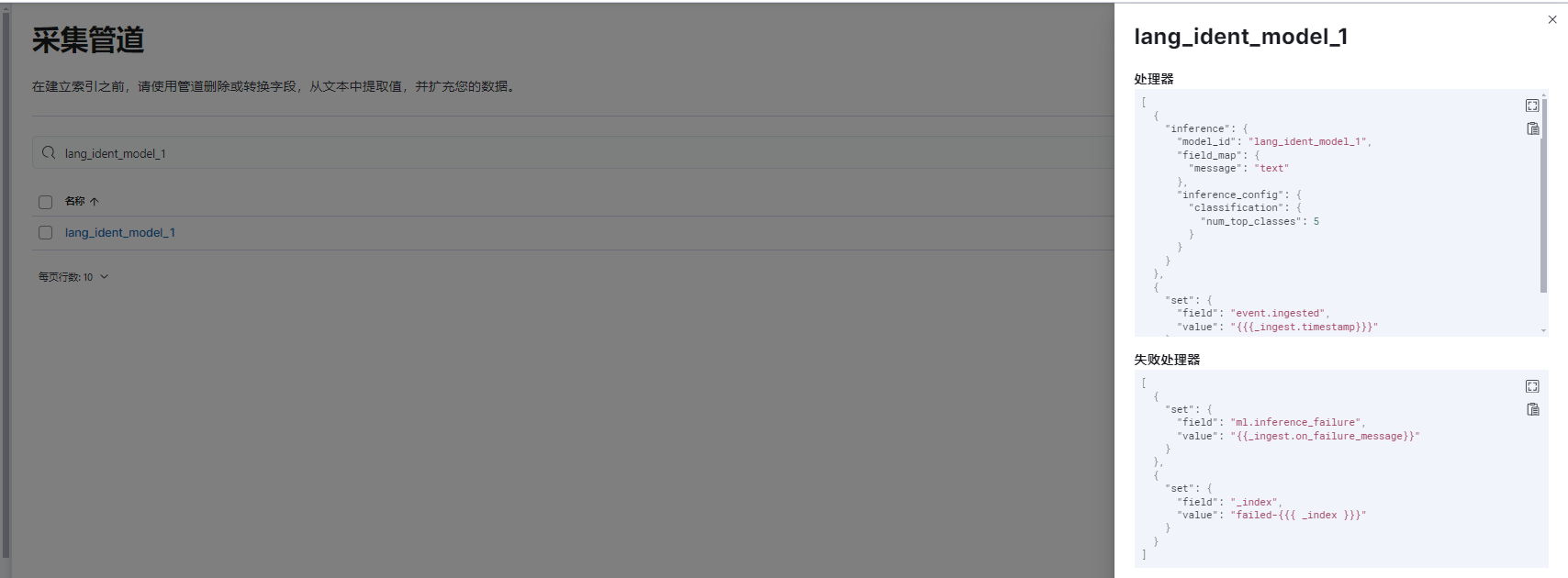
使用
安装插件
注意版本号与es版本一直,都是8.9.1。安装完会自行重启。
下载mapper-annotated-text安装包

映射索引
注意message字段别写错
PUT ner-test
{"mappings": {"properties": {"ml.inference.predicted_value": {"type": "annotated_text"},"ml.inference.model_id": {"type": "keyword"},"message": {"type": "text"},"event.ingested": {"type": "date"}}}
}
索引文档
通过管道 lang_ident_model_1 索引一批文档
POST /_bulk?pipeline=lang_ident_model_1
{"create":{"_index":"ner-test","_id":"1"}}
{"message":"Hello, my name is Josh and I live in Berlin."}
{"create":{"_index":"ner-test","_id":"2"}}
{"message":"I work for Elastic which was founded in Amsterdam."}
{"create":{"_index":"ner-test","_id":"3"}}
{"message":"Elastic has headquarters in Mountain View, California."}
{"create":{"_index":"ner-test","_id":"4"}}
{"message":"Elastic's founder, Shay Banon, created Elasticsearch to solve a simple need: finding recipes!"}
{"create":{"_index":"ner-test","_id":"5"}}
{"message":"Elasticsearch is built using Lucene, an open source search library."}
或者用query
POST lang-test/_doc?pipeline=ner-test
{"message": "Mon pays ce n'est pas un pays, c'est l'hiver"
}
查看数据
"hits": [{"_index": "ner-test","_id": "1","_score": 1,"_source": {"message": "Hello, my name is Josh and I live in Berlin.","event": {"ingested": "2024-04-13T20:31:48.855089336Z"},"ml": {"inference": {"predicted_value": "en","top_classes": [{"class_name": "en","class_probability": 0.9854748734614491,"class_score": 0.9854748734614491},{"class_name": "tg","class_probability": 0.003855695585908385,"class_score": 0.003855695585908385},{"class_name": "ig","class_probability": 0.0036940515396614113,"class_score": 0.0036940515396614113},{"class_name": "sw","class_probability": 0.0021393582129747924,"class_score": 0.0021393582129747924},{"class_name": "it","class_probability": 0.0011839650697029283,"class_score": 0.0011839650697029283}],"prediction_probability": 0.9854748734614491,"prediction_score": 0.9854748734614491,"model_id": "lang_ident_model_1"}}}},......
文档重新索引到新目标
POST _reindex
{"source": {"index": "ner-test-new","size": 50},"dest": {"index": "ner-test","pipeline": "lang_ident_model_1"}
}
这篇关于使用阿里云试用Elasticsearch学习:使用内置模型 lang_ident_model_1 创建管道并使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




