本文主要是介绍基于问题导向与成果产出的教学模式:《大数据与城市规划》特色课程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

[ 编者按 ]2015年12月,清华大学推出“大数据能力提升项目”,旨在促进大数据人才培养,服务国家大数据发展战略。项目由清华-青岛数据科学研究院(以下简称:数据院)和研究生院共同设计组织实施,为了构建大数据思维与技能、跨界学习、应用实操相结合的人才培养体系,培养具有数据思维和应用创新能力“π”型人才。项目推出以来,开设了一系列大数据特色课程,我们将为大家逐一介绍这些课程。
《大数据与城市规划》是国内高校城乡规划专业首次开设大数据与城市规划方面的课程,也得到了清华多个院系研究生的广泛关注。课程培养学生利用数据和先进技术手段来认识城市和改变城市的思维方式和实践能力。课程结合中国城市规划特点以及技术发展特点进行讲授,秉承技术方法与城市理论/规划设计并重的原则,倡导以技术作为认识城市、衡量城市的手段,强调以问题为导向、以成果产出为目标的教学方式。同时通过线上+线下、课内+课外以及理论课+设计课等丰富的授课形式,实现开放性、融入性教学体验。
而在今年度,课程亦成功申请到学校的MOOC在线课程,将结合线上授课的方式持续拓展课程内容。在经过两个学学度实践中的不断发展和完善,课程形成以下主要特色:
一、学生跨学科交叉,激发创新活力
学生专业背景充分体现了跨学科交叉,上学期课程超过一半以上的学生来自非建筑与规划专业,包含土木工程、地球科学、公共管理、社会学院、电子工程等12个院系,构成了一个多元学科组合的课堂。我们看到了城乡规划、计算机、统计学、社会学等多领域学科交织的可能性,也看到学生们结合自身关切的城市议题,所激发出的火花。
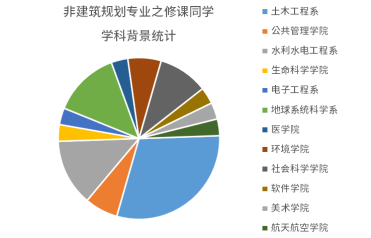
修课学生非建筑相关学科比例统计
二、线下与线上结合,引导自发学习
本课程的所有课程文件、拓展阅读都被放到指定网站上供选课学生下载,通过鼓励学生自发式地学习,从而达到开拓眼界、激发学习兴趣、优化教学效果的目的。另外,课程给学生提供了很多数据,例如北京旧城的一系列数据(边界与分区、开发、形态、功能与活动等),而如何使用数据取决于学生们的独立思考和能动性。

龙瀛老师授课现场

配合每堂课程内容的拓展阅读材料
三、增设课外沙龙,扩宽思维广度
为了辅助课程内容,在课外还设置了多次学术沙龙。课外沙龙的内容偏向实践,由业界知名专家学者针对数据抓取、空间句法以及城市感知计算方法引论等主题进行研讨,为学生们拓展多研究手段奠定基础,并为学生思考问题的方式提供新思路(沙龙不限于修课学生)。

中科院地理所的王江浩老师与听讲学生答疑交流
四、始于问题导向,终于成果产出
为了培养学生的研究意识、研究能力和创新能力,课程强调“基于问题导向与成果产出的研究性教学”,提倡实验教学与科研课题相结合,创造条件使学生较早地参与科学研究和创新活动。
课内时间主要用于讲授理论知识,而在课外时间则鼓励学生们走进街区,以调研的形式促进了学生们对于城市这座实验室的认知,引导学生将抽象的数据分析方法与真切鲜活的城市空间建立联系,从而激发学生自我发现问题并探究问题的热情。以“城市大数据应用研究——以北京老城为例”为主题,将13个不同院系的学生们进行交叉混合分组,结合学生们自身专业与感兴趣的课题,最终将研究成果以论文和汇报形式呈现。课程的终期汇报邀请了多位与产、官、学界相关领域的专家,齐聚一堂为学生们共同点评。

小组实地调研过程

相关领域的专家评委
在上一学期的课程结束之后,有5篇学生论文被澎湃新闻市政厅频道选中报道,14篇论文发表在专业期刊上。这不仅激发了学生的研究热情,更是展现了外界对他们研究水平和研究成果的认可。
四、学生课后反馈,总结经验教训
根据学生们提交的课程总结,通过玻森中文语义API进行语义分析,从数据层面上解析学生们的诉求。首先,语义情感分析表现出一致的正向情感,正向情感权重在0.9以上的占总提交数量的92.2%,其中情感权重在0.99以上的占40.4%,这从一定程度上反映了学生们对这门课程的正向评价以及课程带给学生们的正向作用。

学生反馈的关键词云图
许多学生表示,通过一个学期的课程,不仅提升了他们应用大数据方法来分析和处理动态复杂系统中问题的能力,亦培养出大数据分析思维,使之在面对方案设计时更容易考虑数据增强设计的应用、情景分析和量化评估,进而提高了方案的科学性和高效性。
目前课程的MOOC教材也正在积极筹备中,将于2018秋季学期正式上线,通过在线的方式让更多同学能一起参与至课堂的交流以及学习资源中,欢迎各位同学持续关注。
详细课程信息
▼
课程名称:大数据与城市规划
课程号 :70000662
学分数 :2学分
上课时间:周五上午第二大节
授课老师:龙瀛,清华大学建筑学院
【老师简介】
龙瀛,清华大学建筑学院副教授,博士生导师,研究方向是城乡规划技术科学、城市空间量化研究及其规划设计响应。他是北京城市实验室(Beijing City Lab)创建人、中国城市科学研究会城市大数据专业委员会副主任委员兼秘书长,SCOPUS收录eSCI国际期刊IRSPSD执行主编,Environment and Planning B(SSCI)、《城市发展研究》、《国际城市规划》和《上海城市规划》期刊编委,中国收缩城市研究网络与数据增强设计研究网络的共同发起人,剑桥大学国家公派访问学者,多个大学和科研机构的客座教授/研究员。出版Springer英文专著《Geospatial Analysis to Support Urban Planning in Beijing》,累计发表两百余篇学术论文,30多篇学术论文被SCI/SSCI收录,受邀在多个国际国内刊物上作为客座主编组织专刊(如Landscape and Urban Planning和Journal of Urban Management)。
选课要求:
本学期课程面向建筑学院研究生选修。其他专业同学欢迎于学堂在线参与MOOC课程,若有兴趣参与正式课程,请与助教联系相关面试事宜。
助教信息:
徐婉庭 wt-xu17@mails.tsinghua.edu.cn
詹旭强 joezhan@foxmail.com
供稿 | 清华-青岛数据科学研究院


这篇关于基于问题导向与成果产出的教学模式:《大数据与城市规划》特色课程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







