本文主要是介绍2024妈妈杯mathorcup数学建模C题 物流网络分拣中心货量预测及人员排班,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、数据预处理
数据清洗是指对数据进行清洗和整理,包括删除无效数据、缺失值填充、异常值检测和处理等。数据转换是指对数据进行转换和变换,包括数据缩放、数据归一化、数据标准化等。数据整理是指对数据进行整理和归纳,包括数据分组、数据聚合、数据汇总等。可视化是指将数据以图表的形式呈现出来,方便用户理解和分析数据。
数据预处理在处理数据时的作用非常重要。它可以帮助我们消除数据中的噪声和干扰,提高数据的准确性和可靠性。同时,数据预处理还可以帮助我们发现数据中的规律和趋势,提高数据的可分析性和可挖掘性。
然而,在进行数据预处理时,我们需要注意一些事项。首先,我们需要根据实际需求选择合适的数据预处理方法,避免过度处理或处理不足。其次,我们需要对数据进行备份,以免数据丢失或损坏。最后,我们需要对数据进行验证和确认,确保数据的准确性和可靠性。
针对本道题目,对数据进行排序,进行异常值处理,附件1和2的数据都很干净,就不需要做预处理了。但在论文中不要写肉眼看的干净,应该写使用python(或其他工具)进行批量数据检测,数据干净完整,不需要做额外预处理。
二、遗传算法优化BP神经网络参数进行时间序列预测
数据准备:将时间序列数据集分为训练集和测试集。训练集用于训练BP神经网络,测试集用于评估模型的预测性能。
BP神经网络构建:构建一个基本的BP神经网络模型,包括输入层、隐藏层和输出层。可以根据问题的复杂性和实际需求来确定网络的结构和参数。
遗传算法初始化:初始化遗传算法的种群,每个个体表示BP神经网络的权重和阈值等参数。
遗传算法评估:对每个个体进行评估,使用训练集进行BP神经网络的训练,并计算其在训练集上的适应度值。适应度值可以根据预测误差、均方根误差等指标来定义。
遗传算法选择:根据适应度值选择一部分个体作为父代,用于产生下一代个体。常用的选择策略有轮盘赌选择、排名选择等。
遗传算法交叉:对选出的父代个体进行交叉操作,生成子代个体。交叉操作可以通过交换权重、阈值等参数来实现。
遗传算法变异:对子代个体进行变异操作,引入随机性和多样性。变异操作可以通过微调权重、阈值等参数来实现。
BP神经网络更新:使用训练集对子代个体进行BP神经网络的训练,得到更新后的权重和阈值。
迭代优化:重复进行步骤4至步骤8,直到达到预设的迭代次数或满足终止条件为止。
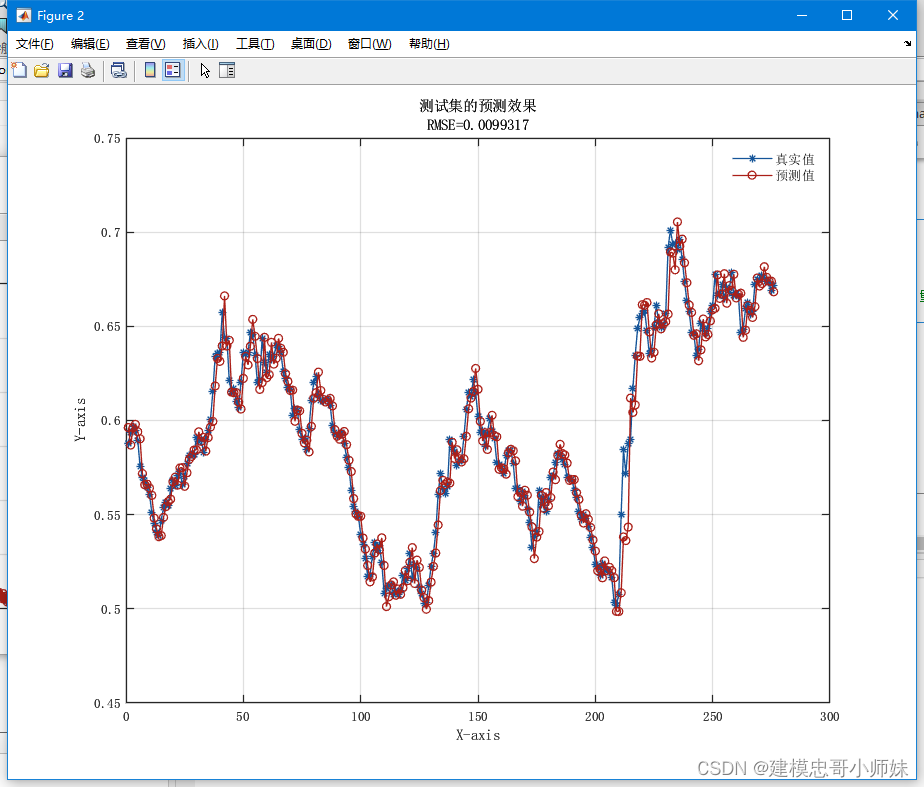
模型评估:使用测试集评估优化后的BP神经网络模型的预测性能,计算预测误差、均方根误差等指标
三、预测结果


四、参考文献
思路及参考成品将在下方名片群文件中更新。
这篇关于2024妈妈杯mathorcup数学建模C题 物流网络分拣中心货量预测及人员排班的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








