本文主要是介绍常用组合逻辑电路模块(3):数据选择器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据选择器概述
数据选择:指经过选择,将多路数据中的某一路数据传到公共数据线上。(相当于多个输入的单刀多掷开关)
数据选择器:能实现数据选择功能的逻辑电路。也称多路选择器或多路开关。如下图为4选1数据选择器:
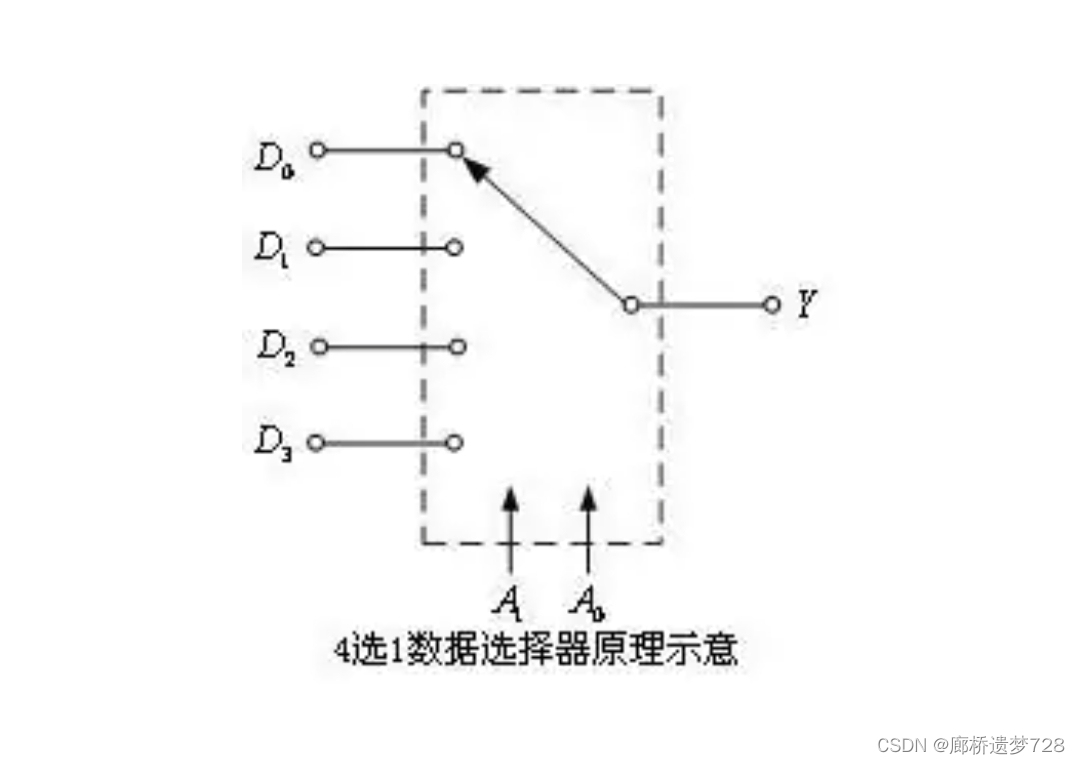
对于4选1数据选择器,最常见的芯片为74LS153,其内部有两个4选1数据选择器。
工作原理:给A1、A0一组信号,比如10,就相当于给了一个二进制数字2,也就相当于选通了D2这个输入端,此时Y输出的就是D2的信号;D2是什么,Y就输出什么。
真值表:
| 地址输入 | 输出 | |
| A1 | A0 | Y |
| 0 | 0 | D0 |
| 0 | 1 | D1 |
| 1 | 0 | D2 |
| 1 | 1 | D3 |
逻辑表达式:
其符号为:
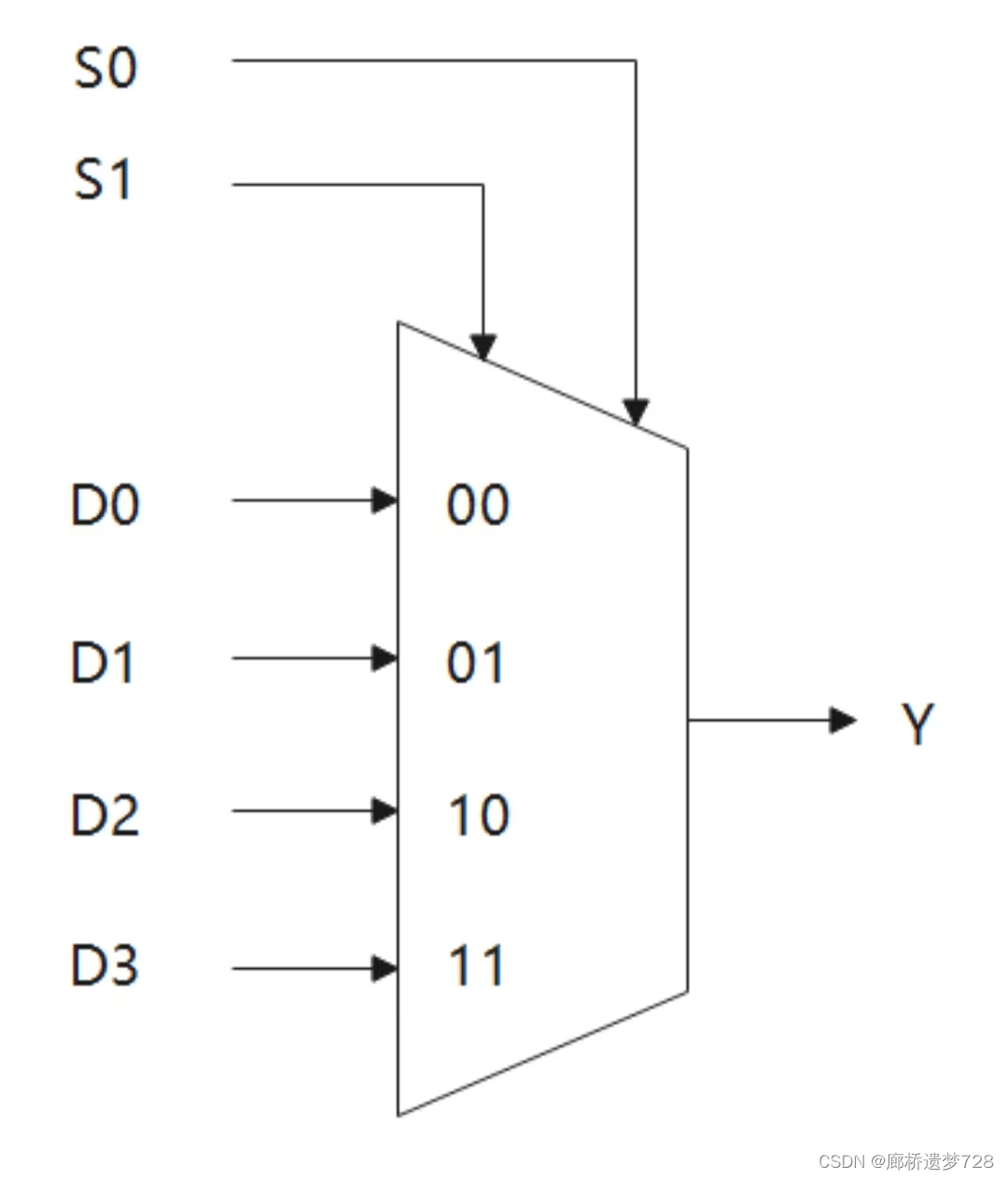
应用:可构成FPGA器件内部查找表(LUT)的基本单元;用于移位运算的移位器也由数据选择器构成;一些数据选择器还具有三态输出功能。
8选1数据选择器
以74HC151芯片为例,框图如下:
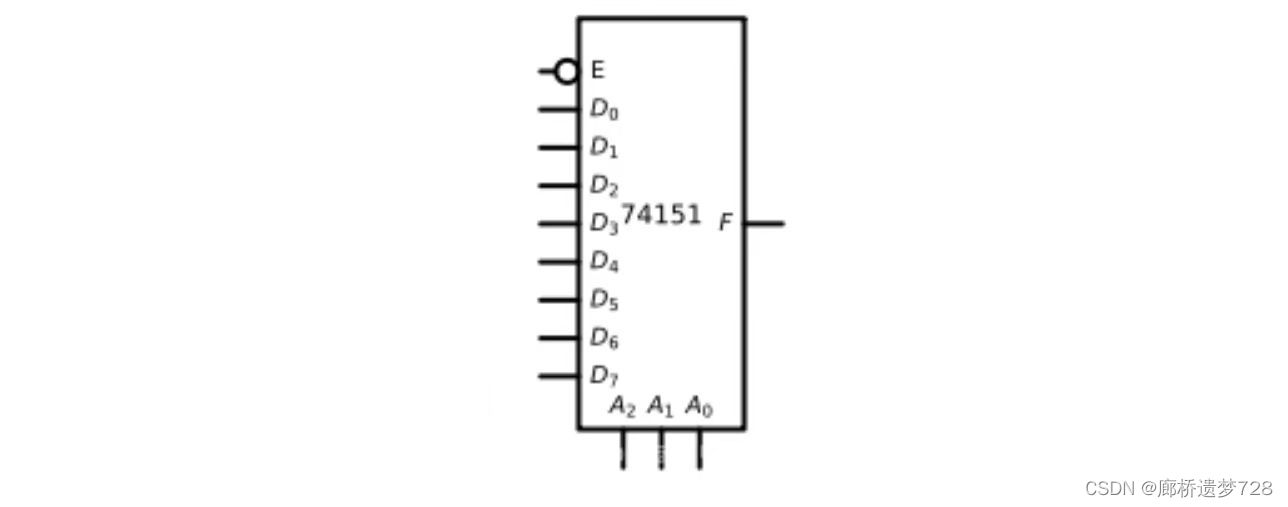
地址输入端S:上图所示A2、A0、A1为地址输入端,也称选择输入端。它决定了输出F等于哪一个D。
对于4选1数据选择器有两个地址输入端,2选1数据选择器有一个。
使能端E:当E为有效电平时,数据选择器开始工作。
数据选择器实现逻辑函数
对于数据选择器,其输入(n个)与输出关系可表达为:
当D为1时,地址输入端对应的最小项出现在表达式中;当D=0时,对应最小项就不出现。通常将需要实现的逻辑函数展开成最小项之和的形式,然后进行判断。
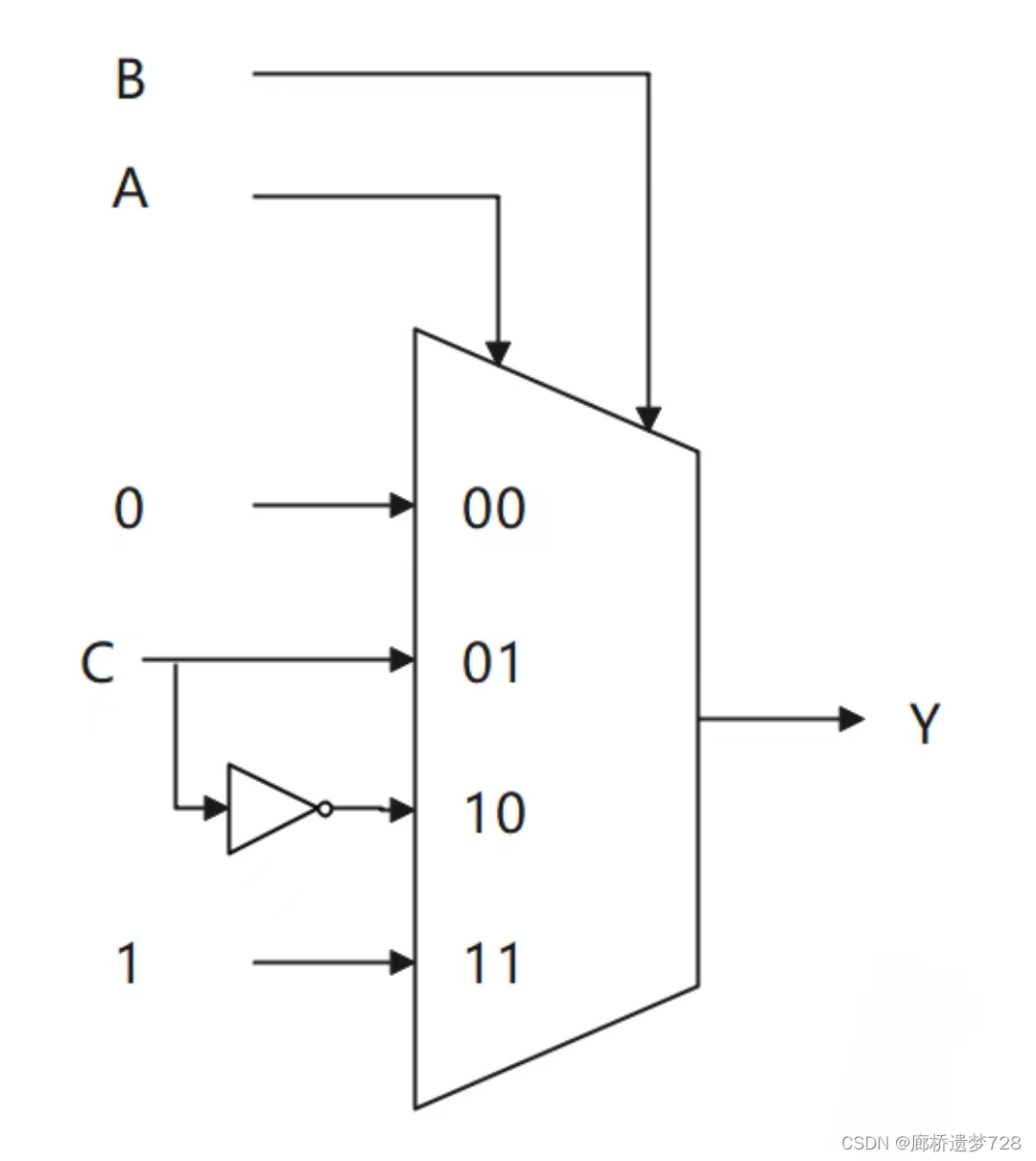
例如:利用4选1数据选择器实现L=AC'+BC。选定A、B为地址输入端,对逻辑函数进行展开(可利用香农展开定理):
对于A'B',上式未出现,便可看作其与0进行与运算;对于AB,其对应项为AB(C+C')=AB1。
由上式便容易得出逻辑电路图,如下所示:
这篇关于常用组合逻辑电路模块(3):数据选择器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




