本文主要是介绍OpenAI战胜DOTA2人类玩家是“里程碑式成就”?有专家评含金量不高,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


新智元报道
编辑:克雷格、闻菲
【导读】上周,OpenAI Five击败DOTA2业余人类玩家,轰动游戏圈和AI圈,连比尔·盖茨都忍不住发推特点赞,称之为“里程碑事件”。这个事件对业界带来的影响有多大?技术含量有多高?新智元采访了数位国内外专家,他们并不全都赞同“里程碑”的观点。
上周,OpenAI自学习多智能体5v5团队战击败DOTA2业余人类玩家,成为轰动人工智能圈的一件大事。
这个事件的意义,不仅仅局限于AI“攻克”星际争霸或者Dota这样的复杂电子竞技游戏,而是代表着AI在决策智能上的能力大幅向前推进。
对于这件事,比尔·盖茨也发推文称赞:这是一件大事,因为它们的胜利需要团队合作和协作——这是推进人工智能的一个巨大里程碑。
不过,也有观点认为OpenAI这个“里程碑”只是在算力上的巨大胜利,并没有在算法上创新,他们只是扩展了已有的方法。
OpenAI“里程碑”的含金量到底高不高?
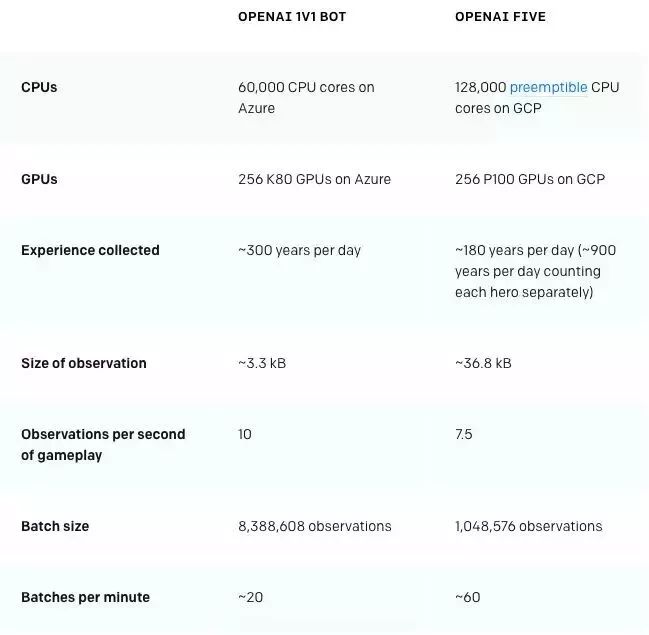
OpenAI Five之所以战胜DOTA2的业余选手,成为比尔·盖茨眼里的里程碑事件,主要原因在于它使用“近端策略优化”(PPO)的扩展版算法,在256个GPU和128000个CPU内核上进行训练。每个英雄都使用单独的LSTM,不使用人类数据,最终AI能够学会识别策略。
这种做法表明,强化学习能够进行大但却可实现规模(large but achievable scale)的长期规划,而不发生根本性的进展。
国内首家决策智能公司启元世界研究科学家、香港科技大学彭鹏博士认为,从Dota2中展现出来的群体智能来看,OpenAI Five无论从对整体局势的判断还是对局部战场的应对,都展现了很高的智能决策能力。
整体战略上,通过前期给辅助英雄一定的资源,让辅助英雄可以通过gank和push帮助队伍快速进入中期阶段,加快并试图掌握游戏节奏;能够快速集结起部分队员进行连续有效的gank;集中push敌方优势路和中路,逼迫对方在较难防守的位置交战。在团战中,对切入时机、距离控制、英雄的职责分配、集火目标选择和多种装备的灵活运用做的非常到位。
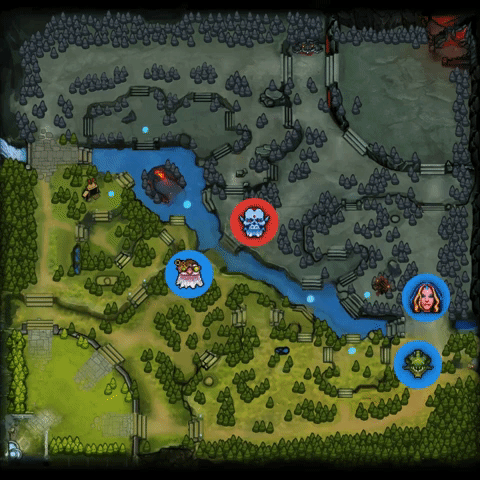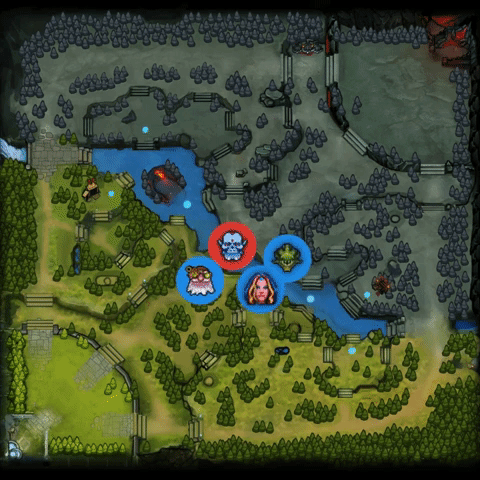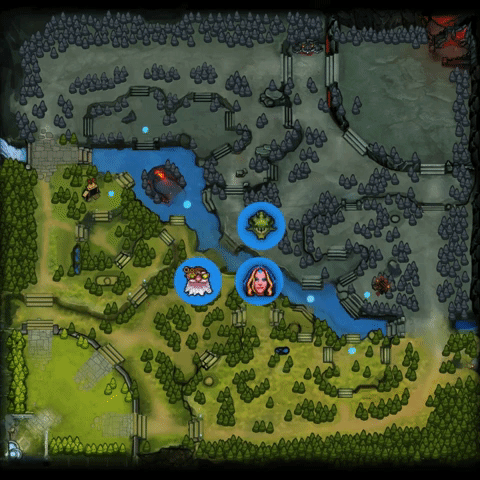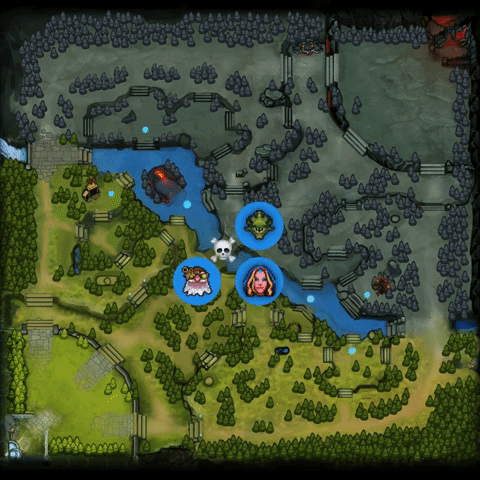
最令人惊讶的是,OpenAI Five直接在微操级别的动作空间中进行探索和学习,仅仅通过几天的训练就达到了上述的效果。虽然有12800 CPU cores和256 P100 GPU的加持,这一结果足以使大家对深度强化学习有更强的信心。
此外,尽管当前版本的OpenAI Five的补兵能力表现不佳,但它在选择优先攻击目标上已经达到专业水平。获得长期回报往往需要牺牲短期回报,例如发育后的金钱,因为团推时也需要耗费时间。这表明系统真正在进行长期的优化。
(关于更具体的实现过程,新智元此前有详细报道,读者可移步新智元知乎专栏阅读:
https://zhuanlan.zhihu.com/p/38499219)
彭鹏博士认为,从技术角度来讲,OpenAI Five延续了OpenAI在1v1中所采用的建模方式,相比Deepmind主打的端到端学习(end-to-end learning),OpenAI Five直接使用语义信息作为模型的输入,极大地降低模型训练所需的计算力,这算是一个新进展。
另外,OpenAI Five也在reward function的构造也很有特色,在个人reward和团队reward之间做了很好的平衡;模型会在训练前期重视优化个人reward,而在训练后期开始注重团队reward。最后,OpenAI大规模高性能的Rapid系统设计也体现了他们的功力,同时调度上万的CPU和GPU资源,在自我对弈的过程中不断变强。
如果仅仅是通过算力提升来训练模型,恐怕不能称之为“里程碑”。
Metamind高级研究科学家Stephen Merity(即Smerity)在OpenAI Five的研究发布当天,连发数条推特,高度评价了这项成果。
Smerity本身是一名DOTA的深度玩家,他从WC3时代开始并且已经打了830小时的DOTA2,他认为这一影响远远超出了DOTA本身。
这些机器人从来没有见过传统的人类策略,它们只是按照规则和目标来玩游戏。如果有一种正和(positive sum)的方式来玩“人”的零和游戏,它一定会找到的。
我们可以预见未来社会中很多错综复杂的东西都没有了,为什么呢?因为这些自主系统将让我们意识到,现在我们的一些优化措施实际上是不成熟的,反而让问题变得复杂;这些系统还能让我们少走很多弯路,现在我们都是走了弯路以后才意识到自己绕了道。
作为人类,我们还不够聪明,无法看穿复杂和复杂交互的迷雾,但我们编写的系统或许可以。它们可能帮助我们实现几百年来我们一直不情愿地、迷茫地走向的目标——协作。
伦敦大学学院(UCL)的计算机教授汪军告诉新智元,AlphaGo之后,AI领域的下一大挑战就是多智能体强化学习(Multi-Agent reinforcement learning,MARL),也即让多个智能体学会合作与竞争。
DOTA、星际争霸,还有更多人熟悉的王者荣耀,都属于多智能体强化学习(MARL),但DOTA 5v5的设置相对更加简单。从去年开始,汪军在UCL的团队与上海的一家游戏公司合作,研究如何让AI玩王者荣耀。目前,包括DeepMind、Facebook、阿里、腾讯在内的很多机构,都在这些游戏上从事MARL研究,但尚未有团队公开实质性的突破。
OpenAI的工作让更多学者和公众关注MARL,这是一件好事,但如果说这是一项“里程碑式的成就”,则远远谈不上。
汪军说,OpenAI仅发布了blog,没有发布学术论文,目前对其科学性还比较难以评估。但从发布的blog上看不到算法的创新。他们只是扩展了已有的方法,然后上了大量的计算力——整整128000 CPU和 256 GPU,这样的硬件基础设施是一般的高校所不具备的。”
“OpenAI证明了使用现有的算法和trick,加上强大的计算力、工程力量和足够的耐心,是可以把这件事情做出来的。”
很可惜的是,OpenAI并没有针对游戏中AI如何合作去明晰建模,没有尝试去理解AI彼此合作的机制,模型还是单独的强化学习,把其他的英雄当成环境的一部分,并使用普通的团队和个体结合的奖励机制,通过大量试错取得了最后的结果。“只要有足够多的时间(也就是足够多的计算资源),你总能试出一些结果。”汪军说,因此它不太具有创新性。
汪军呼吁大家重视并扶持基础性的长期研究,将眼光放长远,“多多资助我们这些搞基础研究的一些GPU”,对领域长期健康发展做出积极贡献。
不过,汪军也非常肯定AlphaGo、OpenAI等机构的研究对产业带来的潜移默化的影响。“目前,阿里巴巴、百度、滴滴、京东、华为这些公司都在尝试把强化学习用在不同的场景,比如直接用在互联网广告、仓储物流、自动驾驶等场景上面,这就是AlphaGo带来的影响,大家都对强化学习非常关注。”
“据我所知,DeepMind已经把研究的一些能量输入到谷歌内部中,好像我们看到DeepMind还没有实现经济价值,其实已经让谷歌内部产生了效率。”汪军说。
这篇关于OpenAI战胜DOTA2人类玩家是“里程碑式成就”?有专家评含金量不高的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









