本文主要是介绍2024MathorCup(妈妈杯) C题完整思路+数据集+完整代码+高质量成品论文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
C题物流网络分中心货量预测及人员排班
(完整的资料+数据集+代码在文末)
电商物流网络在订单履约中由多个环节组成,其中,分拣中心作为网络的中 间环节,需要将包裹按照不同流向进行分拣并发往下一个场地,最终使包裹到达 消费者手中。分拣中心管理效率的提升,对整体网络的履约效率和运作成本起着 十分重要的作用。分拣中心的货量预测是电商物流网络重要的研究问题,对分拣 中心货量的精准预测是后续管理及决策的基础 ,如果管理 者可以提前预知之后一段时间各个分拣中心需要操作的货量,便可以提前对资源 进行安排。在此场景下的货量预测目标一般有两个:一是根据历史货量、物流网 络配置等信息,预测每个分拣中心每天的货量;二是根据历史货量小时数据,预 测每个分拣中心每小时的货量。分拣中心的货量预测与网络 的运输线路有关,通过分析各线路的运输
货量,可以得出各分拣中心之间的网络连接关系。当线路关系调整时,可以参考 线路的调整信息,得到各分拣中心货量更为准确的预测。基于分拣中心货量预测 的人员排班是接下来要解决的重要问题,分拣中心的人员包 含正式工和临时工两种:正式工是场地长期雇佣的人员,工作效率较高;临时工 是根据货量情况临时招募的人员,每天可以任意增减,但工作效率相对较低、雇 佣成本较高。根据货量预测结果合理安排人员,旨在完成工作的情况下尽可能降 低人员成本。针对当前物流网络,其人员安排班次及小时人效指标情况如下:
1)对于所有分拣中心,每天分为 6 个班次,分别为:00:00-08:00,05:00-13:00, 08:00-16:00,12:00-20:00,14:00-22:00,16:00-24:00,每个人员(正式工或 临时工)每天只能出勤一个班次;
C题第一问所有代码数据集

2)小时人效指标为每人每小时完成分拣的包裹量(包裹量即货量),正式工的最高小时人效为 25 包裹/小时,临时工的最高小时人效为 20 包裹/小时。
该物流网络包括 57 个分拣中心,每个分拣中心过去 4 个月的每天货量如附 件 1 所示,过去 30 天的每小时货量如附件 2 所示。基于以上数据,请完成以下 问题:
本题出题方式类似于 2023 年 Mathorcup 与五一赛的相关内容, 但是在路径 规划的前提下, 还增加了预测的相关工作.或者, 我们以 2021 年国赛 C 题进行对比, 那题也是有关于转运商, 供货商的问题. 在拿到题 目的评分标准中, 对结果的判别并没有那么严苛, 国赛中说道, 只需要写出对 应的约束条件, 所有的结果都可以接受. 所以大家不需要非常纠结结果是否准 确无误, 预测结果是否会对后面的小问造成影响等小的细节问题.
问题 1:建立货量预测模型,对 57 个分拣中心未来 30 天每天及每小时的货 量进行预测,将预测结果写入结果表 1 和表 2 中。
问题 1 要求我们预测 57 个分拣中心未来 30 天每天和每个小时的货量,这里 比较关键的是对附件 1 和 2 的数据进行预处理.
我们首先看一下附件 1 和附件 2.
将 57 个分拣中心的数据分别取出构成一列,因为题目给的附件 1 和附件 2 的数据都是打乱格式的,需要注意对数据需要将其按照时间序列排好(题目给的 数据不是按照时间序列来的),
附件 1 是各个分拣中心的货量, 整理之后我们看到对于每一个分拣中心, 所 给的数据是从 2023-8-1 到 2023-11-30 每天的一个货量数据.
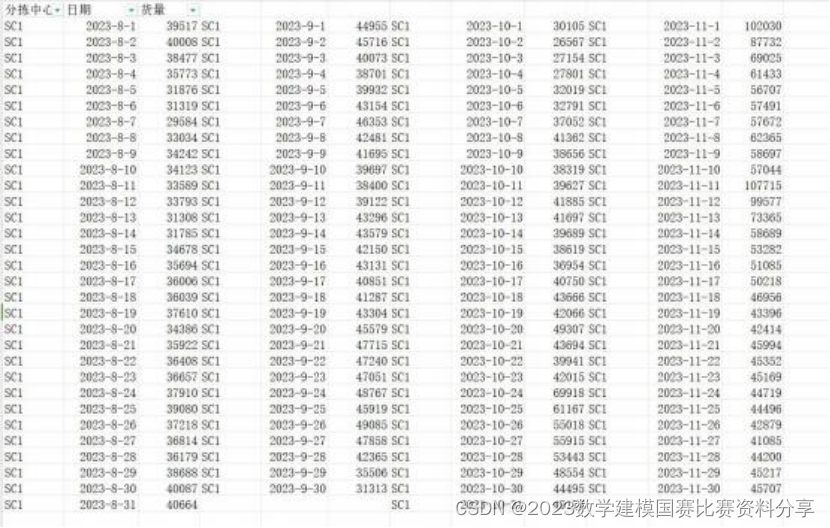
附件二是每个分拣站 2023-11-1 到 2023-11-30 每天 24 个小时的货量.
附件中有很多空值, 或者缺失值, 没有某个日期或者某个小时下, 某个中转站 的数据, 这个时候需要代码处理, 需要填 0.
题目最终预测未来 30 天每个小时的货量时,数据格式应该是 57 个货运站*30 天*24 小时的货量结果,也就是需要预测 57*30*24 这么多次,这里需要利用 for 循环书写代码, 并且利用代码直接保存结果到 excel 中, 不然重复多次复制很 容易出现问题,就是运行时间可能会很长.另外, 针对 57 个货运站明 显需要分别进行预测, 也就是说在每一次循环的过程中, 输入的数据集是不一 样的, 输出的结果也是不一样的, 每次循环只预测一个货运站.
预测模型选取的话可以采用 ARIMA 时间序列、LSTM 神经网络等经典模型,这 里就不建议采用灰色预测(短期预测),当然也可以采用 SVM、CNN 等模型进行 循环预测. 我们首先尝试了一下最简单的利用 ARIMA 预测, 可以看到后期都是 直接预测出来一条直线, 预测效果很不好.
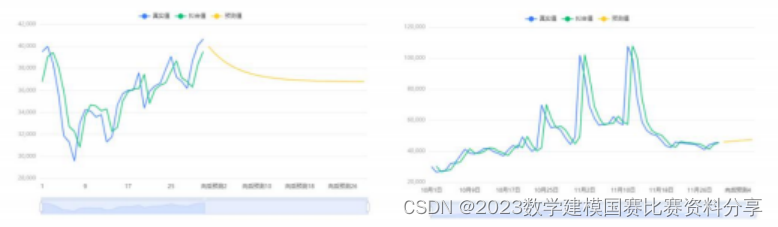
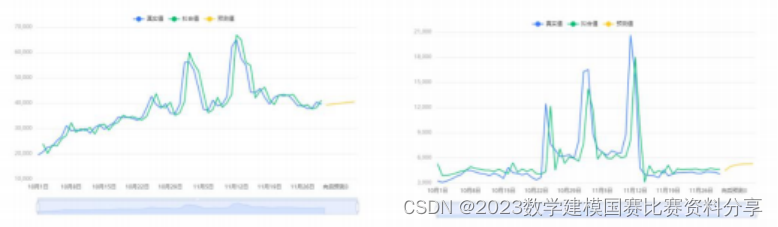
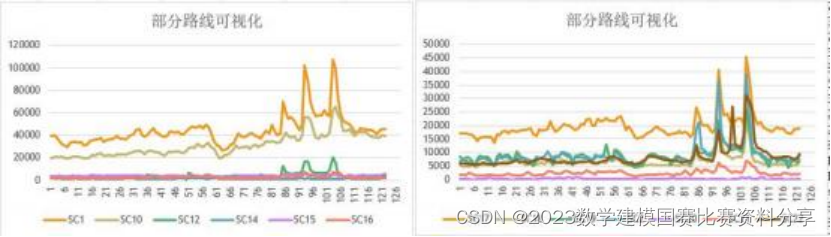
论文写作的时候, 我们也可以辅助以绘制可视化, 来丰富文章的内容, 尤其是 第一小问做预测之前, 可以适当进行可视化的相关内容.
问题 2:过去 90 天各分拣中心之间的各运输线路平均货量如附件 3 所示。若 未来 30 天分拣中心之间的运输线路发生了变化,具体如附件 4 所示。根据附件 1-4,请对 57 个分拣中心未来 30 天每天及每小时的货量进行预测,并将预测结 果写入结果表 3 和表 4 中。
这一问是在问题 1 的基础上,告诉我们运输线路发生变化了,重新回答问题 1,这里其实不需要我们重新进行预测模型的建立,而是考虑在问题 1 预测结果 的基础上加入运输线路变化的影响,直接对问题 1 预测结果进行调整,
例如我 SC22 这个分拣中心原先预测的货量是 1000,然后其他分拣中心往我 这运货总量为 100,但是现在路线改变了,其他分拣中心加起来的总量可能为 150, 那我就在 1000 的基础上加上 150 即可。
问题 3:假设每个分拣中心有 60 名正式工,在人员安排时将优先使用正式工, 若需额外人员将使用临时工。请基于问题 2 的预测结果建立模型,给 出未来 30 天每个分拣中心每个班次的出勤人数,并写入结果表 5 中。要求在每 天的货量处理完成的基础上,安排的人天数(例如 30 天每天出勤 200 名员工, 则总人天数为 6000)尽可能少,且每天的实际小时人效尽量均衡。
这一问就是建立一个规划模型来解决人员排班问题,首先要定义合适的变量 和参数,建立一个目标函数和约束条件的数学模型,通过求解模型得到最优的出 勤人数安排方案。目标函数可以是最小化总人天数,约束条件可以包括每天货量 处理完成、每天的实际小时人效均衡、每个分拣中心的 60 个正式工限制等,最 后调用 MATLAB 的优化工具箱进行求解即可。像决策变量的选取可以是第 i 天。
2024MathorCup C题完整思路+完整数据+可执行代码+后续高质量成品论文
这篇关于2024MathorCup(妈妈杯) C题完整思路+数据集+完整代码+高质量成品论文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





