本文主要是介绍Latent Diffusion Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Latent Diffusion Models(潜在扩散模型,LDMs)是一种生成模型,它结合了扩散模型和变分自动编码器(VAES)的优势,从文本或其他输入模式生成高质量图像。近年来,这些模型受到了相当大的关注,因为它们能够在保持对发电过程的控制的同时产生高度现实和多样化的产出。
Latent Diffusion Models(潜在扩散模型,LDMs)是一种基于潜在扩散过程的生成模型,它主要应用于AI作画领域。该模型通过在一个潜在表示空间中逐级去噪来得到中间表示结果,然后再将其解码为完整的生成图像。相比之前的基于像素空间的扩散模型,潜在表示空间显著降低了计算量,使得AI作画能够在消费级GPU上使用,且在几秒时间内生成图像,极大地降低了落地门槛。
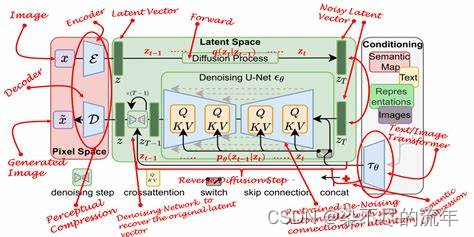
以下是潜在扩散模型背后的关键概念和原则概述:
1、扩散模型:
扩散模型是一个生成框架,它逐渐将随机噪声分解为有意义的数据,通常是图像。这是通过模拟逐渐向数据添加噪声的前向扩散过程,然后是逐步消除噪声的学习反向过程,最终重建原始数据分布。反向过程由一个神经网络指导,该神经网络经过培训,可以预测扩散过程中每个步骤的噪声,给出噪声输入和当前时间步骤。扩散模型在无条件和条件图像合成任务中表现出色。
2、可变自动编码器(VAES):
VAES是一种由编码器和解码器网络组成的生成模型。编码器将输入数据(例如图像)映射到低维潜在空间&
这篇关于Latent Diffusion Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)

