本文主要是介绍2024Mathorcup(妈妈杯)数学建模C题python代码+数据教学,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2024Mathorcup数学建模挑战赛(妈妈杯)C题保姆级分析完整思路+代码+数据教学
C题题目:物流网络分拣中心货量预测及人员排班
因为一些不可抗力,下面仅展示部分代码(很少部分部分)和部分分析过程,其余代码看文末
数据处理:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import pmdarima as pm
from itertools import product
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as nptry:# 尝试使用UTF-8编码读取文件day_df = pd.read_csv('./附件/附件1.csv', encoding='utf-8')
except UnicodeDecodeError:# 如果出现编码错误,则尝试使用GBK编码读取day_df = pd.read_csv('./附件/附件1.csv', encoding='gbk')
day_df# 将'日期'转换为datetime类型以便正确排序
day_df['日期'] = pd.to_datetime(day_df['日期'])# 按'日期'升序排列DataFrame
sorted_day_df = day_df.sort_values(by=['分拣中心', '日期'])sorted_day_df可视化:
# Set the font to support Chinese characters
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(10, 6))
for center in sorted_day_df['分拣中心'].unique():center_df = sorted_day_df[sorted_day_df['分拣中心'] == center]plt.plot(center_df['日期'], center_df['货量'], marker='o', label=center)plt.title('日期随货量变化的折线图')
plt.xlabel('日期')
plt.ylabel('货量')
# plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 绘制ACF和PACF图
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(center_df['货量'], ax=ax[0])
plot_pacf(center_df['货量'], ax=ax[1])
plt.tight_layout()
plt.show()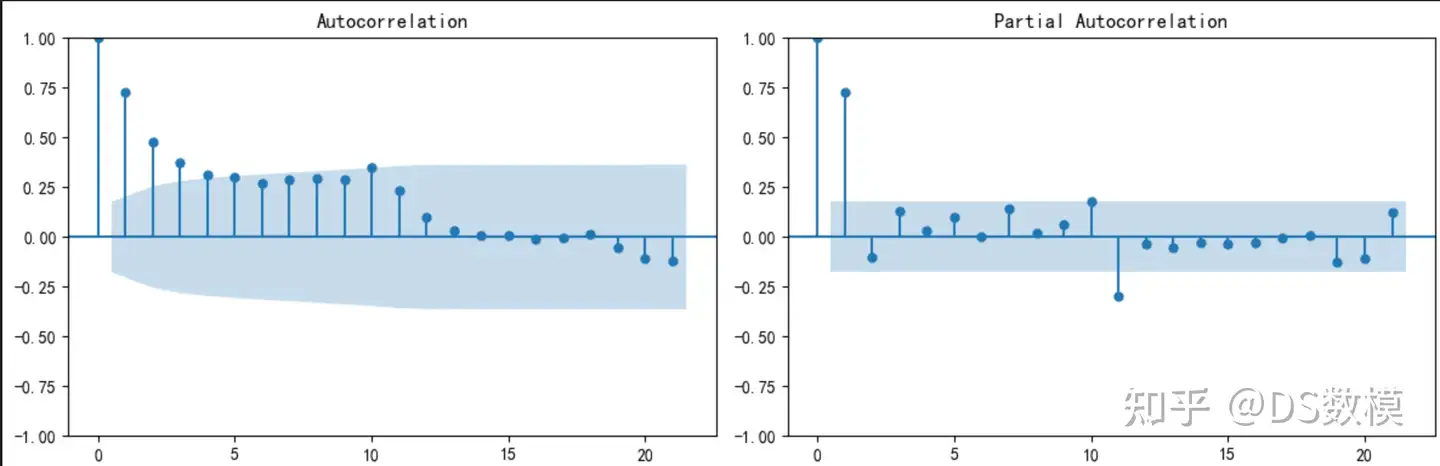
for center in centers:center_df = sorted_day_df[sorted_day_df['分拣中心'] == center]center_df.set_index('日期', inplace=True)# 使用SARIMAX而不是ARIMA来考虑外生变量model = SARIMAX(center_df['货量'], exog=center_df['活动'], order=(1, 1, 1))model_fit = model.fit()# 预测时也需要包括外生变量# 假设我们已经有了未来时间段的活动标记数据future_dates = pd.date_range(center_df.index[-1] + pd.Timedelta(days=1), periods=30, freq='D')future_exog = pd.DataFrame(0, index=future_dates, columns=['活动']) # 假设未来5天内没有活动forecast = model_fit.forecast(steps=30, exog=future_exog)print(f"{center} 的未来 30 天预测货量为:")print(forecast)# 将预测结果转换为DataFrameforecast_df = pd.DataFrame({'分拣中心': center,'日期': future_dates,'货量': forecast.values})all_forecasts.append(forecast_df)# 合并所有分拣中心的预测结果
final_forecast_df = pd.concat(all_forecasts)预测结果:

其中更详细的思路,各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方群名片哦!
这篇关于2024Mathorcup(妈妈杯)数学建模C题python代码+数据教学的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



