本文主要是介绍Python数据可视化:同时展示两个变量之间的双变量(联合)关系以及每个变量的单变量(边缘)分布seaborn.jointplot,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【小白从小学Python、C、Java】
【计算机等考+500强证书+考研】
【Python-数据分析】
Python数据可视化:
同时展示两个变量之间的
双变量(联合)关系以及
每个变量的单变量(边缘)分布
seaborn.jointplot
选择题
jointplot可以画出什么样的图标?
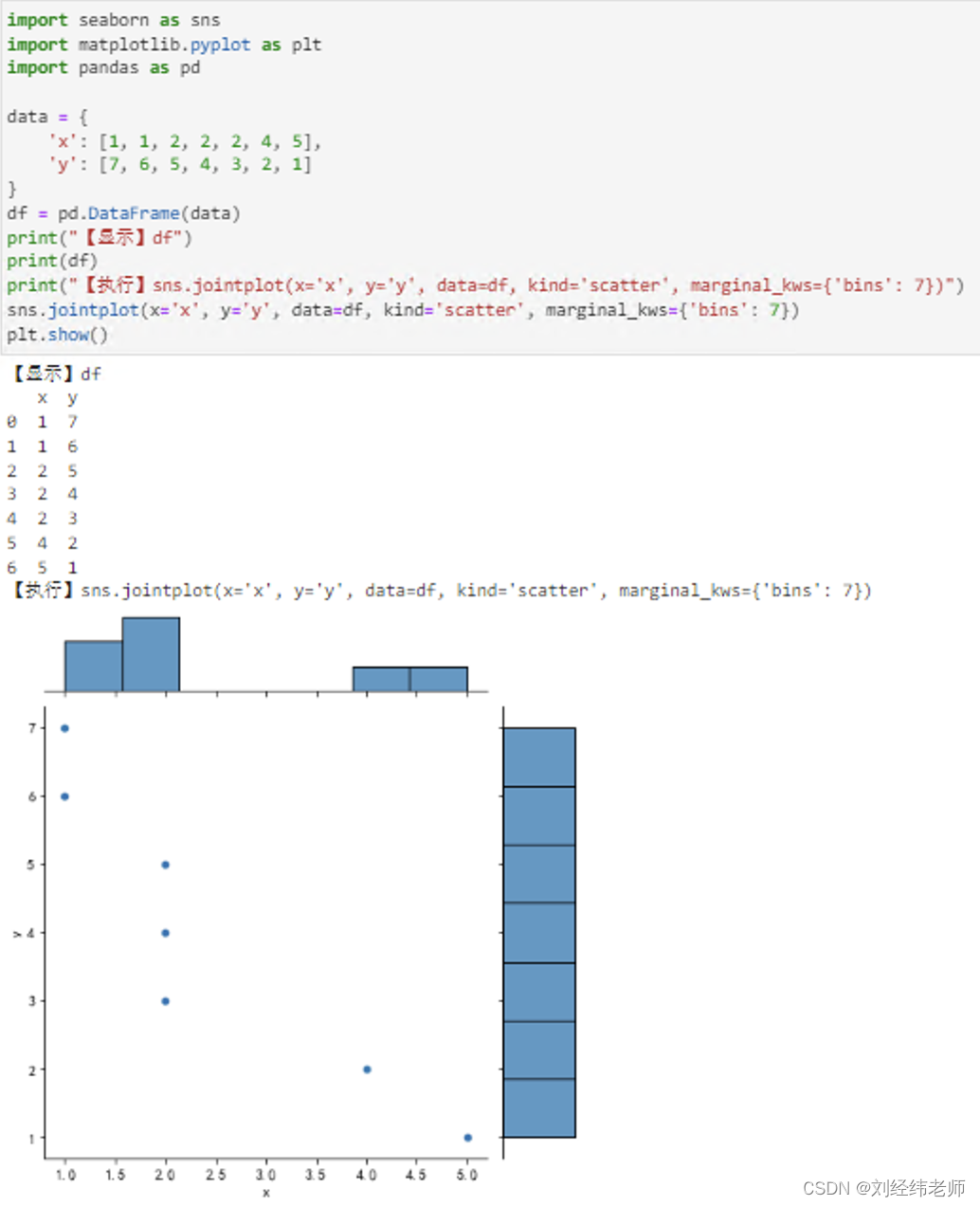
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = {
'x': [1, 1, 2, 2, 2, 4, 5],
'y': [7, 6, 5, 4, 3, 2, 1]
}
df = pd.DataFrame(data)
print("【显示】df")
print(df)
print("【执行】sns.jointplot(x='x', y='y', data=df, kind='scatter', marginal_kws={'bins': 7})")
sns.jointplot(x='x', y='y', data=df, kind='scatter', marginal_kws={'bins': 7})
plt.show()
A选项:直方图
B选项:点状图
C选项:折线图
D选项:中心点状图边缘直方图
正确答案是:D
图1 问题解析

图2 题目代码
欢迎大家转发,一起传播知识和正能量,帮助到更多人。期待大家提出宝贵改进建议,互相交流,收获更大。辛苦大家转发时注明出处(也是咱们公益编程交流群的入口网址),刘经纬老师共享知识相关文件下载地址为:https://liujingwei.cn
这篇关于Python数据可视化:同时展示两个变量之间的双变量(联合)关系以及每个变量的单变量(边缘)分布seaborn.jointplot的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








