本文主要是介绍mmdetection模型使用mmdeploy部署在windows上的c++部署流程【详细全面版】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

0. 前置说明:
该文档适用于:已经使用mmdetection训练好了模型,并且完成了模型转换。要进行模型部署了。
1. 概述
MMDeploy 定义的模型部署流程,如下图所示:

模型转换【待撰写,敬请期待…】
主要功能是:把输入的模型格式,转换为目标设备的推理引擎所要求的模型格式。
目前,MMDeploy 可以实现:① 把PyTorch模型,转换为 ONNX、TorchScript 等设备无关的模型; ② 将 ONNX模型转换为推理后端模型。
两者相结合,可实现端到端的模型转换,也就是从训练端到生产端的一键式部署。
MMDeploy 模型(也称 SDK Model)
它是模型转换结果的集合。包括:①后端模型,②模型的元信息。这些信息,将用于推理 SDK。
推理 SDK【本博客的内容】
封装了模型的前处理、网络推理和后处理过程。对外提供多语言的模型推理接口(python/c++等)。【注意:本教程为c++】
2. 准备工作
对于端到端的模型转换和推理,MMDeploy 依赖 Python 3.6+ 以及 PyTorch 1.8+。
第1步:下载并安装 Miniconda
(这步很简单,省略,不懂的话可以评论区留言)
第2步:创建并激活 conda 环境
conda create --name mmdeploy python=3.8 -y
conda activate mmdeploy
第3步: 并安装 PyTorch GPU或者CPU版本
链接:安装PyTorch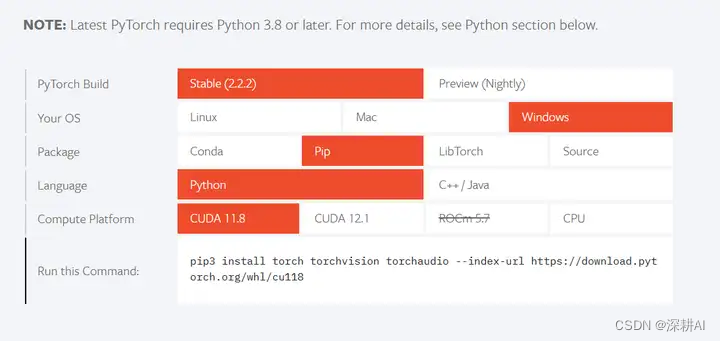
注意❗:在 GPU 环境下,请务必保证 cudatoolkit_version 和主机的 CUDA Toolkit 版本一致,避免在使用
TensorRT 时,可能引起的版本冲突问题。
3. 准备推理SDK
第1步: 安装 MMDeploy 推理SDK
推理SDK 的 c/cpp 库可从 这里 选择最新版本下载并安装。
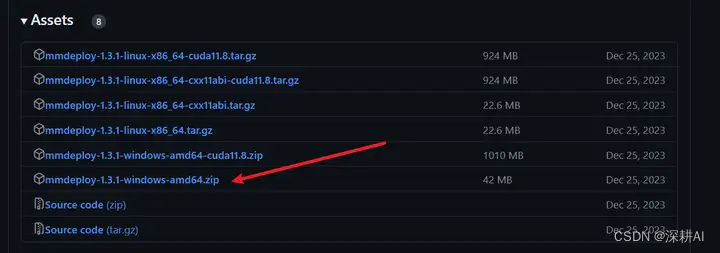
注意❗下载并且解压后,就会看到如下图所示的结构:

查看readme.md文档,就会发现,我们需要进一步根据提示:①安装opencv,②设置环境变量,③创建sdk。下面我们依次进行。
第2步: 安装opencv
找到Windows PowerShell,并使用管理员身份打开。
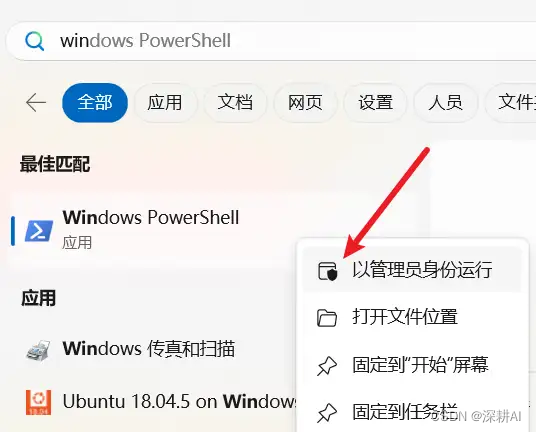
打开管理员权限的 Windows PowerShell
打开Windows PowerShell后,执行命令:set-ExecutionPolicy RemoteSigned,并选择Y。
Set-ExecutionPolicy RemoteSigned 是一个在 Microsoft PowerShell 中使用的命令。
它用来配置 PowerShell 的执行策略(Execution Policy),这是 PowerShell 引擎对脚本执行的一种安全机制。执行策略决定了 PowerShell 是否允许运行未签名的脚本,以及这些脚本是从何处获得的。
具体来说:
RemoteSigned 执行策略意味着:
①对于本地创建的 PowerShell 脚本,允许直接执行。
②对于从互联网或其他远程位置下载的脚本,要求它们必须具有经过验证的数字签名(即已签名)才能执行。
换句话说,在设置了 RemoteSigned 执行策略之后,用户可以自由地执行自己在本地计算机上编写的脚本,
但对于外部来源的脚本,为了确保其来源可信,系统会要求这些脚本经过合法证书颁发机构签名或由受信任的发布者签名。此设置,旨在保护系统免受恶意脚本的攻击,同时保持一定的灵活性,允许执行经过验证的远程脚本和所有本地脚本。
在企业环境中,执行策略通常由系统管理员或通过
这篇关于mmdetection模型使用mmdeploy部署在windows上的c++部署流程【详细全面版】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







