本文主要是介绍爬虫 新闻网站 以湖南法治报为例(含详细注释) V4.0 升级 自定义可任意个关键词查询、时间段、粗略判断新闻是否和优化营商环境相关,避免自己再一个个判断,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标网站:湖南法治报
爬取目的:为了获取某一地区更全面的在湖南法治报的已发布的和优化营商环境相关的宣传新闻稿,同时也让自己的工作更便捷
环境:Pycharm2021,Python3.10,
安装的包:requests,csv,bs4,datetime
v4.0 版本特点:获取指定时间段的新闻数据,筛选出含有想要查找的的任意个关键词的新闻内容,同时标注新闻是否和优化营商环境相关(粗略判断新闻是否和优化营商环境相关),并存储起来。
1 首先分析网页
(查看数据返回方式,发现网站不用像红网那样设置各种headers了,可以直接爬)
发现在这个页面只有文章标题和发布时间,以及文章链接的信息(当然文章有图片的就还有图片信息)
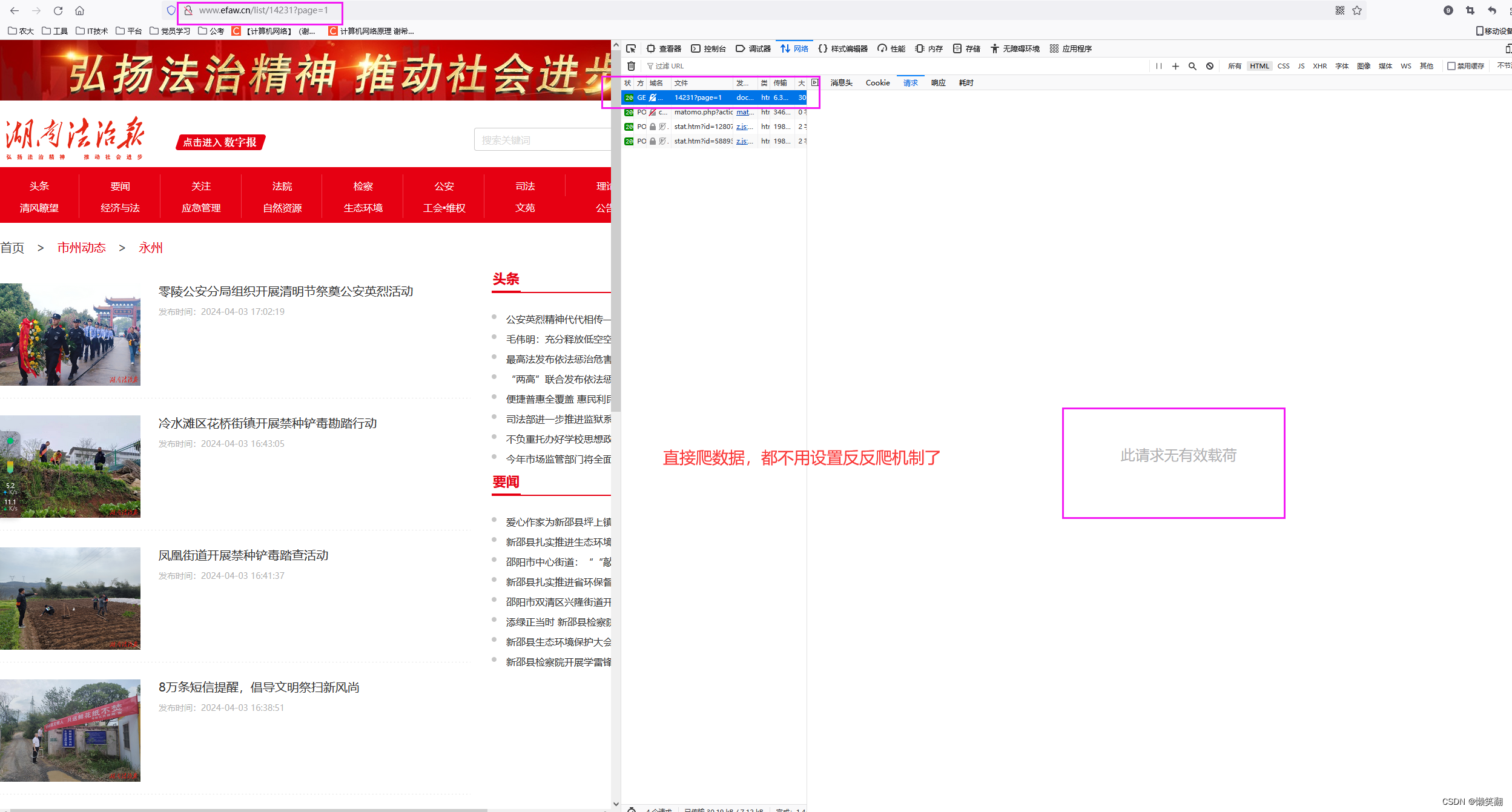

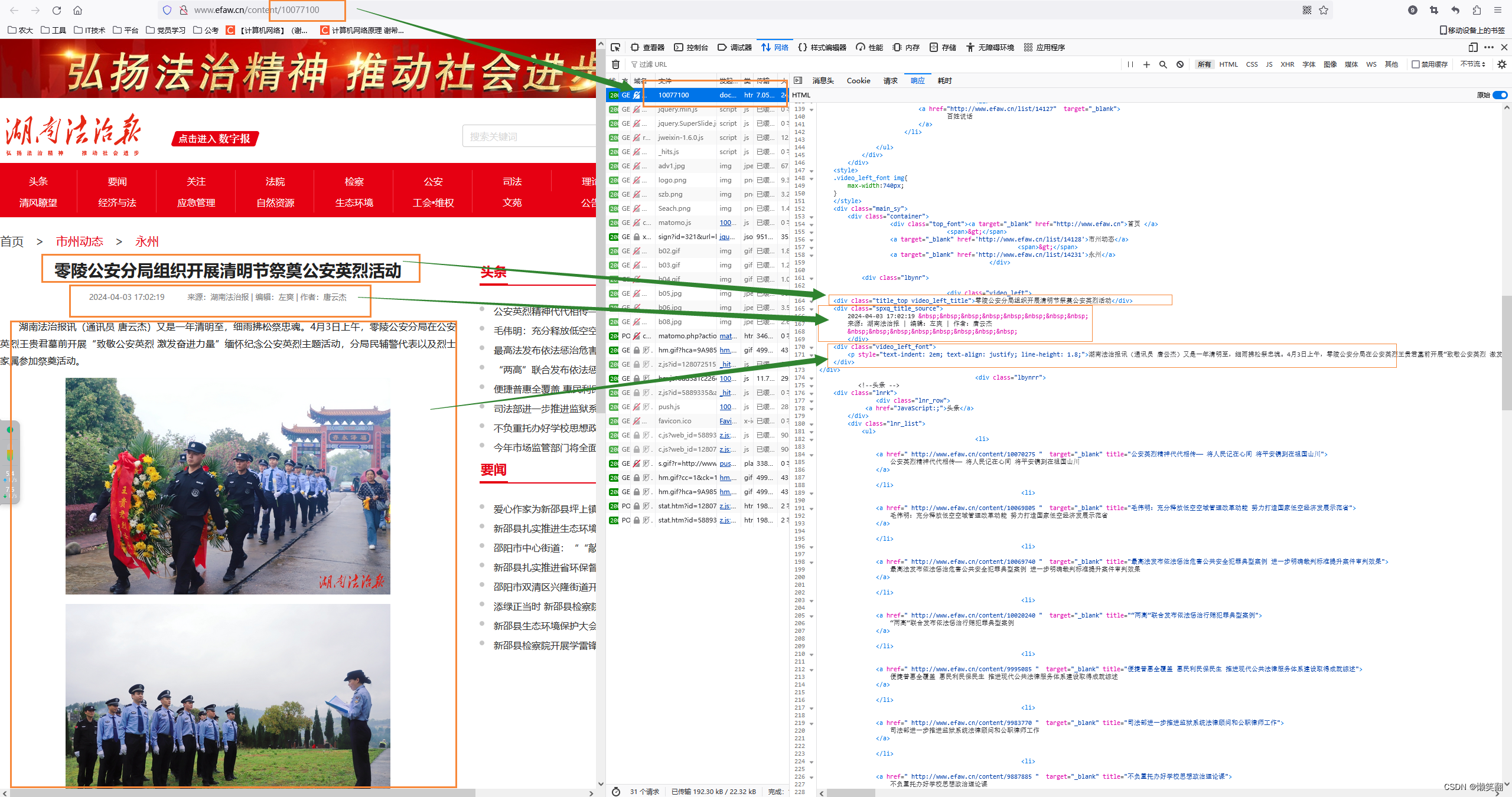
2 再看文章内容页面
(像我就只要文字部分就行了,不需要图片)
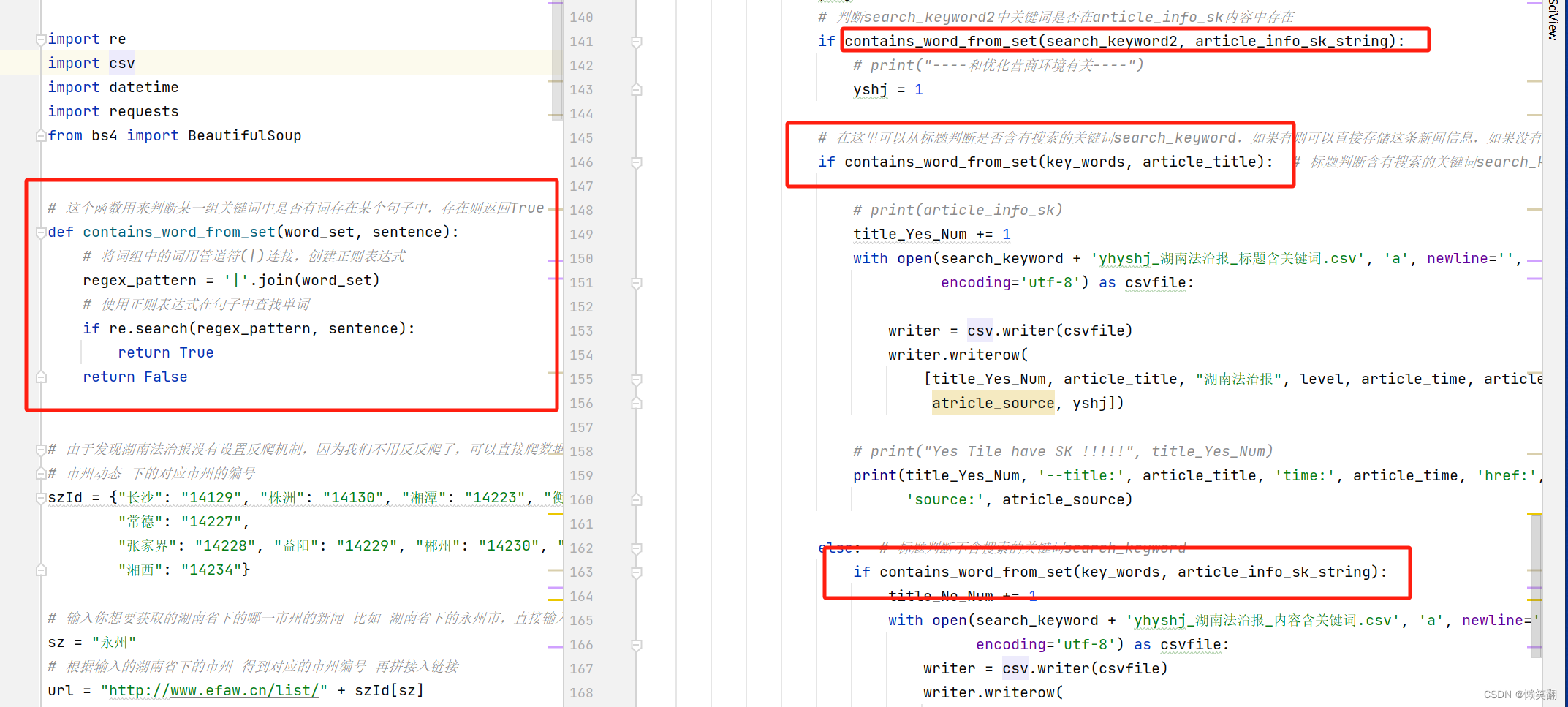
3 和v3对比修改的主要代码:(增加可以多个关键词搜索的方法)
4 运行结果:
5 完整代码,(详细注释)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/4/7 21:05
# @Author : 懒笑翻
# @Site :
# @File : efaw_v4.py
# @Software: PyCharm# v4版本主要是优化搜索,可以任意个关键词,自定义关键词;同时删掉输入,可以直接修改参数,因为每次输入也是头疼,不如直接改参数呢!
# 今天爬取玩数据发现一个问题,就是有一些双牌县下的乡镇的新闻其实是和营商环境相关的,但是因为内容时以他们乡镇直接写的,没提到双牌县**乡镇,因此导致数据被丢弃
# 为了避免上述情况再次出现,于是想了把乡镇的关键词也包含进去
# 双牌县有哪些乡镇:
# 镇:泷泊镇、江村镇、五里牌镇、茶林镇、何家洞镇、麻江镇。
# 乡:塘底乡、上梧江瑶族乡、理家坪乡、五星岭乡、打鼓坪乡。import re
import csv
import datetime
import requests
from bs4 import BeautifulSoup# 这个函数用来判断某一组关键词中是否有词存在某个句子中,存在则返回True
def contains_word_from_set(word_set, sentence):# 将词组中的词用管道符(|)连接,创建正则表达式regex_pattern = '|'.join(word_set)# 使用正则表达式在句子中查找单词if re.search(regex_pattern, sentence):return Truereturn False# 由于发现湖南法治报没有设置反爬机制,因为我们不用反反爬了,可以直接爬数据了
# 市州动态 下的对应市州的编号
szId = {"长沙": "14129", "株洲": "14130", "湘潭": "14223", "衡阳": "14224", "邵阳": "14225", "岳阳": "14226","常德": "14227","张家界": "14228", "益阳": "14229", "郴州": "14230", "永州": "14231", "怀化": "14232", "娄底": "14233","湘西": "14234"}# 输入你想要获取的湖南省下的哪一市州的新闻 比如 湖南省下的永州市,直接输入 永州 即可
sz = "永州"
# 根据输入的湖南省下的市州 得到对应的市州编号 再拼接入链接
url = "http://www.efaw.cn/list/" + szId[sz]
# 输入你想要的关键词 比如 双牌、蓝山、宁远、新田、零陵
search_keyword = '双牌'
# 双牌县下的乡镇
key_words = {'双牌', '泷泊', '江村', '五里牌', '茶林', '何家洞', '麻江', '塘底', '上梧江瑶族', '五星岭', '打鼓坪', '理家坪'}# 二级搜索 优化营商环境 乡村振兴 农业振兴之类的,可以一直加
search_keyword2 = {'优化', '营商', '环境', '春耕', '乡村', '农村', '乡镇', '农业'}
# 自定义需要获取的新闻的时间段
# 开始时间
start_time = '2024 4 1'
start_time = datetime.datetime.strptime(start_time, '%Y %m %d')
# 截止时间
end_time = '2024 4 8'
end_time = datetime.datetime.strptime(end_time, '%Y %m %d')
# 标题就含有关键词的计数器
title_Yes_Num = 0
# 标题不含有关键词但是内容含有关键词的计数器
title_No_Num = 0
# 新闻来源级别
level = "省级"
# 用于计数爬到第几个新闻
count_cc = 0
"""
爬虫思路:
首先最开始是打开要爬取的网站,然后分析怎样获取需要的数据最完整和便捷
一开始看到搜索其实是想直接搜关键词获取新闻的,但是发现通过搜索框获得到新闻数据不如市州动态下的全面,
所以还是打算一条一条新闻比对是否符合自定义关键词
1 首先进入市州动态获取到某市州动态下的所有新闻数据
2 根据具体新闻链接进入新闻页面,获取到新闻信息
"""# # 创建CSV文件并写入头部信息
with open(search_keyword + 'yhyshj_湖南法治报_标题含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源', '优化营商环境相关']) # 根据实际情况定义列名
with open(search_keyword + 'yhyshj_湖南法治报_内容含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源', '优化营商环境相关']) # 根据实际情况定义列名# http://www.efaw.cn/list/14231?page=1
page = 1
# while page <= 20: # 从这里修改数字以控制要多少页的新闻内容,,page<=20page从1开始一直到20
while page > 0:# 拼接出每一页的urlurl_page = url + "?page=" + str(page) # http://www.efaw.cn/list/14231?page=5html_all = requests.get(url_page)html_all.encoding = 'utf-8'print(page, '页', url_page)if html_all.status_code == 200:soups = BeautifulSoup(html_all.text, 'html.parser')article_info = soups.find_all('ul', class_='list_content')for i in article_info:result_info = i.find_all('div')for art in result_info:article_href = art.a.get('href') # 文章链接article_href = re.sub(r'\s+', '', article_href) # 去除链接中存在的空隔# print(article_href)article_title = art.a.get('title') # 文章标题article_time = art.i.text # 文章发布时间 显示为:发布时间:2024-04-02 10:08:03# 因为只要年月日部分的时间,因此把一些不需要的字符去掉article_time = article_time[2 + article_time.index('间:'):]article_time = article_time[:article_time.index(':') - 3]article_time = article_time.replace('-', '.')article_time_se = datetime.datetime.strptime(article_time, '%Y.%m.%d')count_cc += 1# print('--page', page, 'count_cc', count_cc, '--title:', article_title, 'time:', article_time, 'href:',# article_href)# 现在有个问题怎么退出循环,时间不满足就退出:现在获取到的新闻的时间<开始时间就退出if article_time_se < start_time:page = -1break# 只把时间满足要求的数据才继续下面的操作 并把数据存入表格if start_time <= article_time_se <= end_time:# 从文章内容中获取到来源html_article_info_sk = requests.get(article_href)html_article_info_sk.encoding = 'utf-8'if html_article_info_sk.status_code == 200:soups_sk = BeautifulSoup(html_article_info_sk.text, 'html.parser')# article_info_sk:文章的相关内容,包括标题、发表时间、来源、编辑、作者、文章内容article_info_sk = soups_sk.find_all('div', class_='video_left')# 其实在这里我想获取到具体的来源,这一段因为在新闻详情页面,如果 来源 为 双牌县优化办 ,那么这条新闻就是优化办推过去的spxq_title_source = soups_sk.find('div', class_='spxq_title_source').text# 文章信息来源 显示为: 来源:湖南法治报atricle_source = spxq_title_source[spxq_title_source.index('来源:') + 3:spxq_title_source.index('|')]article_info_sk_string = str(article_info_sk) # 这里要把article_info_sk字符串化,不然无法判断关键词是否在内容中存在# 设立一个标识,默认为0和营商环境无关,1有关yshj = 0# 判断search_keyword2中关键词是否在article_info_sk内容中存在if contains_word_from_set(search_keyword2, article_info_sk_string):# print("----和优化营商环境有关----")yshj = 1# 在这里可以从标题判断是否含有搜索的关键词search_keyword,如果有则可以直接存储这条新闻信息,如果没有则继续查看新闻内容,看是否含有关键词信息if contains_word_from_set(key_words, article_title): # 标题判断含有搜索的关键词search_keyword# print(article_info_sk)title_Yes_Num += 1with open(search_keyword + 'yhyshj_湖南法治报_标题含关键词.csv', 'a', newline='',encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_Yes_Num, article_title, "湖南法治报", level, article_time, article_href,atricle_source, yshj])# print("Yes Tile have SK !!!!!", title_Yes_Num)print(title_Yes_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href,'source:', atricle_source)else: # 标题判断不含搜索的关键词search_keywordif contains_word_from_set(key_words, article_info_sk_string):title_No_Num += 1with open(search_keyword + 'yhyshj_湖南法治报_内容含关键词.csv', 'a', newline='',encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_No_Num, article_title, "湖南法治报", level, article_time, article_href,atricle_source, yshj])# print("Yes Content have SK !!!!!", article_info_sk)print(title_No_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href,'source:', atricle_source)page += 1print("#### 你获取的关键词", search_keyword, '时间从', start_time, '~', end_time, '的数据已经获取完!')
这篇关于爬虫 新闻网站 以湖南法治报为例(含详细注释) V4.0 升级 自定义可任意个关键词查询、时间段、粗略判断新闻是否和优化营商环境相关,避免自己再一个个判断的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






