本文主要是介绍大语言模型及提示工程在日志分析任务中的应用 | 顶会IWQoS23 ICPC24论文分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文是根据华为技术专家陶仕敏先生在2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会闪电论文分享环节上的演讲整理成文。
BigLog:面向统一日志表示的无监督大规模预训练方法
BigLog: Unsupervised Large-scale Pre-training for a Unified Log Representation(IWQoS 2023)
作者:陶仕敏*、刘逸伦*、孟伟彬、任祚民、杨浩等
论文链接:https://ieeexplore.ieee.org/abstract/document/10188759
代码:https://github.com/LogAIBox/BigLog
LogPrompt:面向零样本和可解释性日志分析的提示工程
LogPrompt: Prompt Engineering Towards Zero-Shot and Interpretable Log Analysis(ICSE 2024 Poster & ICPC 2024)
作者:刘逸伦、陶仕敏、孟伟彬、姚飞宇、赵晓峰、杨浩等
论文链接:https://arxiv.org/abs/2308.07610
代码:https://github.com/lunyiliu/LogPrompt
大家好,非常感谢组委会的邀请。我跟AIOps挑战赛结缘已久,在2018年的时候我当时所在的团队赞助了第一届挑战赛。很荣幸今年再次站在挑战赛的舞台上跟大家交流探讨。我们团队主要研究的方向是机器翻译,机器翻译是典型的语言模型,在这个领域我们开展了日志相关的研究工作,今天跟大家分享的两篇论文也是和日志相关的。
我分享的内容大致分为四个章节。
第一部分:软件日志运维观点
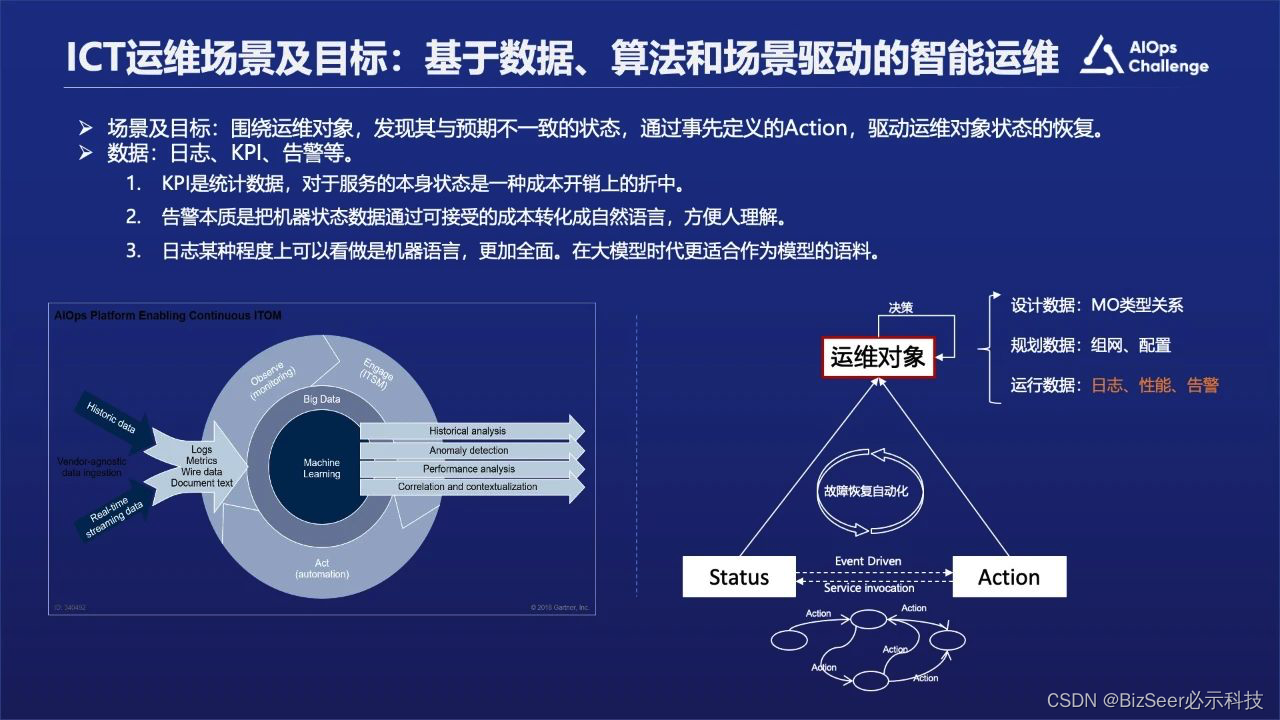
从日志的角度看,智能运维可以简单的概述为基于数据算法以及场景驱动的一个软件的运维工作。
运维工作中最核心的就是数据,数据里面最核心的部分包含有日志、指标数据、告警数据等,我们认为从某种程度上而言日志可以被看作是一个更全面的数据,它代表一种机器语言,其它的指标数据可能是从日志里面获取的并经过后期加工处理,所以可能会有一些信息丢失。
大语言模型为什么可以应用到ICT运维领域?
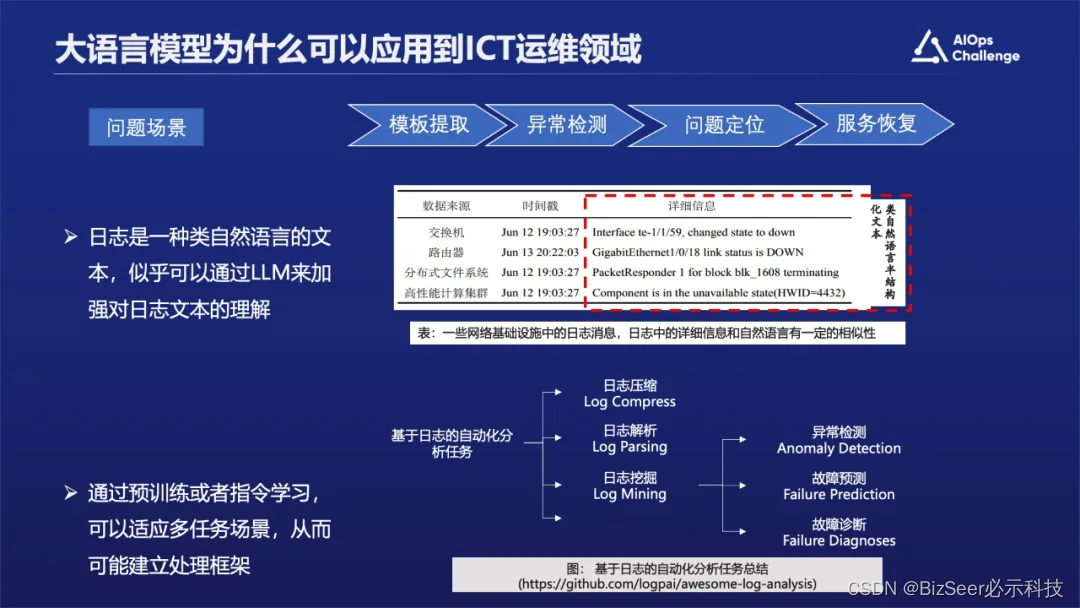
首先日志是一种类自然语言的文本,可以通过大语言模型加强对日志文本的理解。其次通过预训练或者指令学习,可以适应多任务场景,从而可能建立处理框架。
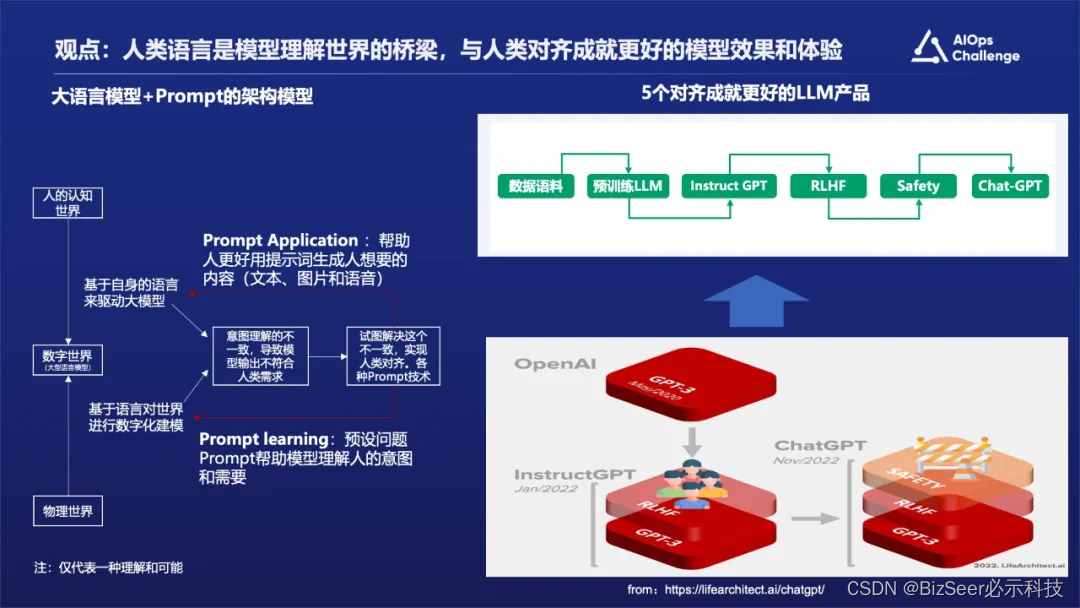
现在大语言模型非常火热,之所以会出现这样一个能够理解自然语言世界的模型,其本质上是通过自然语言对整个物理世界的一种映射,建立的是一种数字世界,所以它是能够理解真实的物理世界,包括我们的真实运营环境。
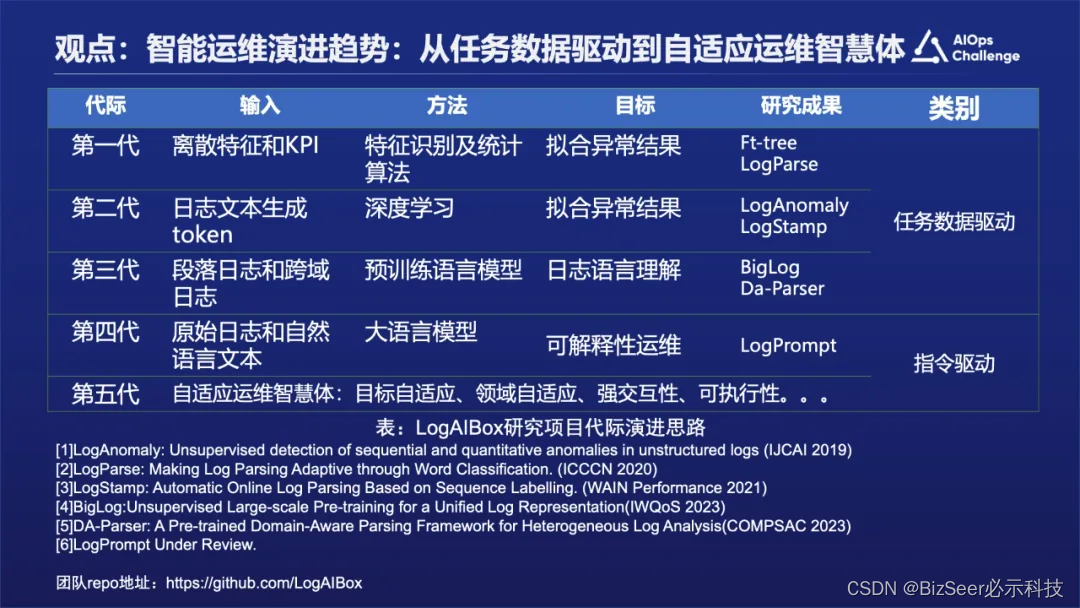
上图是我们的研究团队,以及和清华裴丹老师合作的一些日志相关的内容做了一个总结。
从第一代到第三代是任务数据驱动型,到第五代大模型出现之后转变为指令驱动的方式,就是构建自动自适应的智能运维体的方式。
第二部分:AIOps痛点与挑战
痛点一:传统运维系统中定制化严重、各自为战,缺乏统一框架。
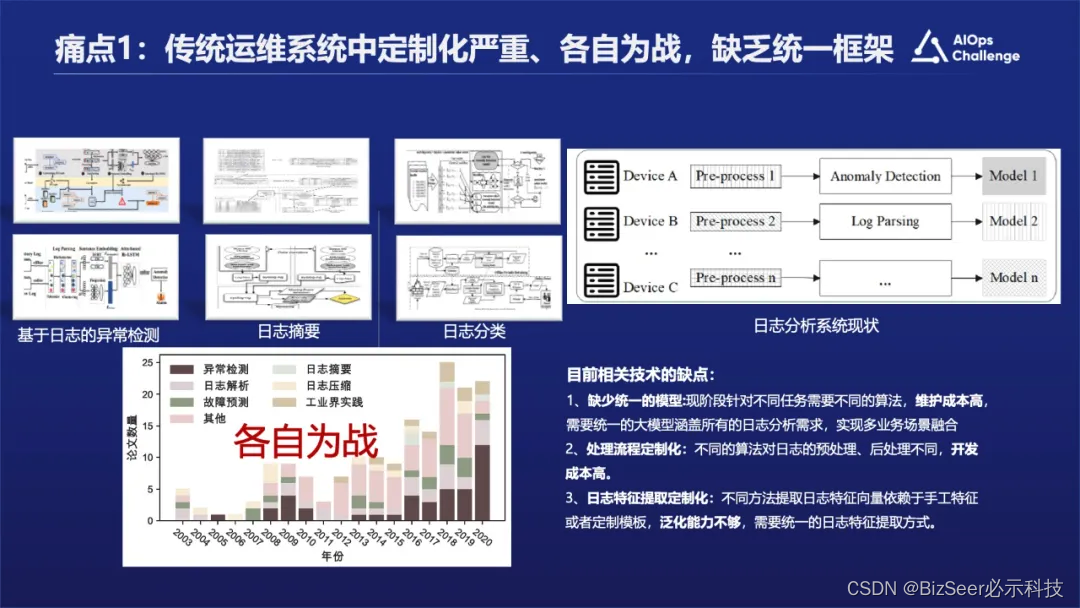
痛点二:传统日志分析方法中缺少对日志语义特征的深度挖掘以及对语义的理解。

痛点三:传统智能运维算法依赖于任务数据,专家标注耗时耗力。前面也有专家介绍过标注数据其实是比较少的,那么我们该如何解决依赖人力标注的问题?
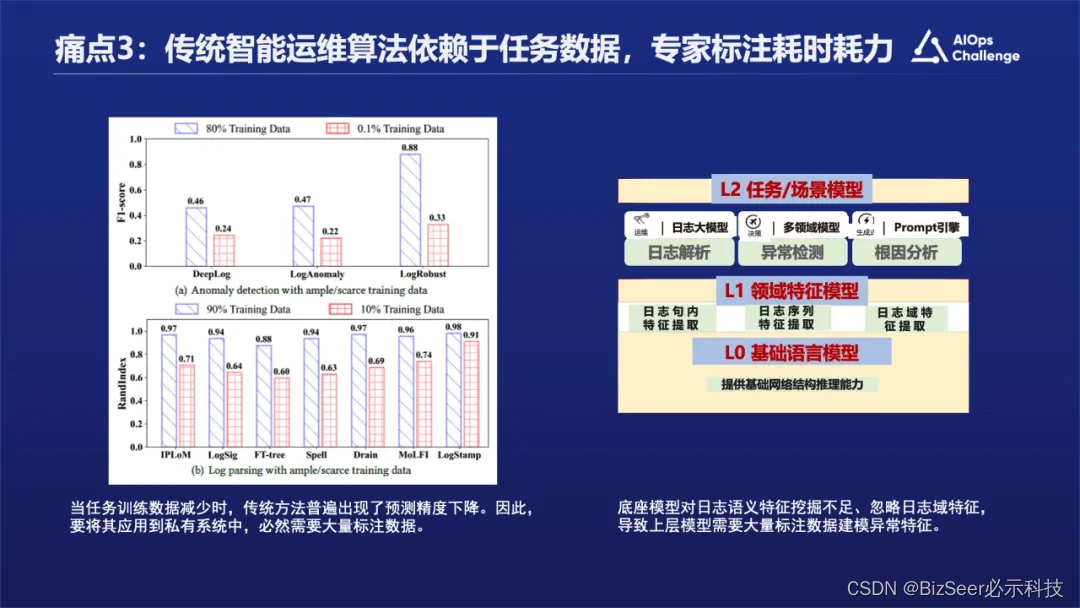
痛点四: 传统运维系统可解释性差、可交互性弱。

第三部分:大模型时代的AIOps应用探索
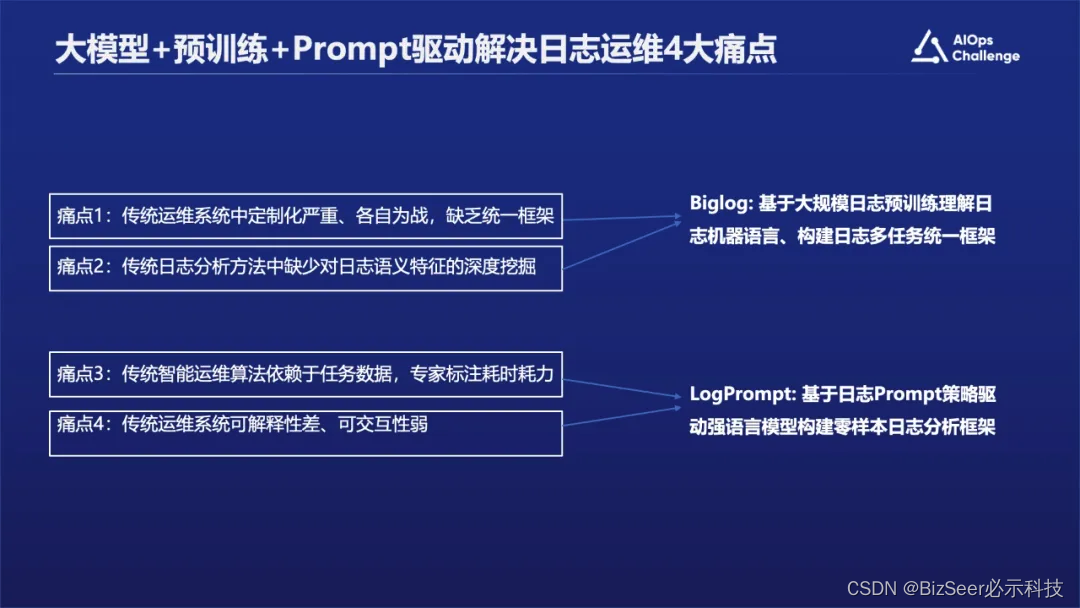
为了解决上述痛点问题,我们团队做了深入的研究工作,有两个解决方案,第一个就是Biglog, 基于大规模日志预训练理解日志机器语言、构建日志多任务统一框架,解决传统运维系统没有统一框架的问题和传统日志分析对于日志语义理解特征的一些痛点问题。我们是基于LogHub开源数据再加上自己的数据做的训练工作。
另外一个就是LogPrompt,基于日志适用的Prompt策略驱动强语言模型构建零样本日志分析框架,通过领域prompt策略驱动语言模型,构建零样本的日志分析框架,解决图片上痛点3和痛点4的问题。
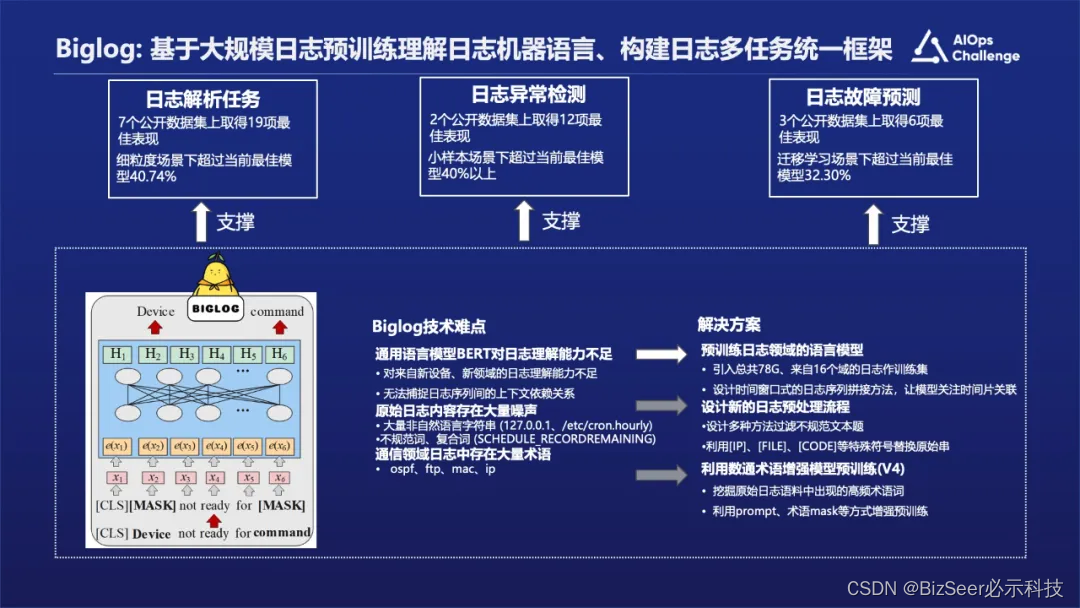
在Biglog这块我们引入了来自16个域、约80G的日志数据作训练集,基于BERT的架构做初始化,训练一个能理解日志的语言模型,这样不仅引入了一个统一的日志分析框架,并且可以对输入日志做通用表征。
这里面有一个核心点,就是对里面的日志做了预处理,把一些非关键性因素替换成可以用语义能表达的数据。比如,把具体的IP地址替换成特殊符号[IP],把一些具体的文件路径替换成[FILE],把一些代码相关的符号替换成[CODE]等。我们还利用到术语,把我们自己已有的术语资料放在预训练模型中一起去训练。

上图中展示就是LogHub开源的数据和和华为自己内部的数据,然后我们基于BERT架构做了一个纯日志的预训练方式。

图片中展示的是我们的效果,日志解析的效果是非常理想的,因为我们的模型本身在16个域的所有数据上都做了一些训练,从根源上来说可能学习到了各个系统的一些日志模板的规范,包括日志的打印方式。

图片中展示的是在异常检测的任务上的效果。Offline的结果显示模型和算法的效果都是挺不错的,基本上都接近1。Online训练时训练数据是在不间断减少的,并且测试数据越来越多且包含一些未知的日志。当训练数据从80%减少到0.1%的时候,Biglog效果保持的非常好,几乎没有变化。
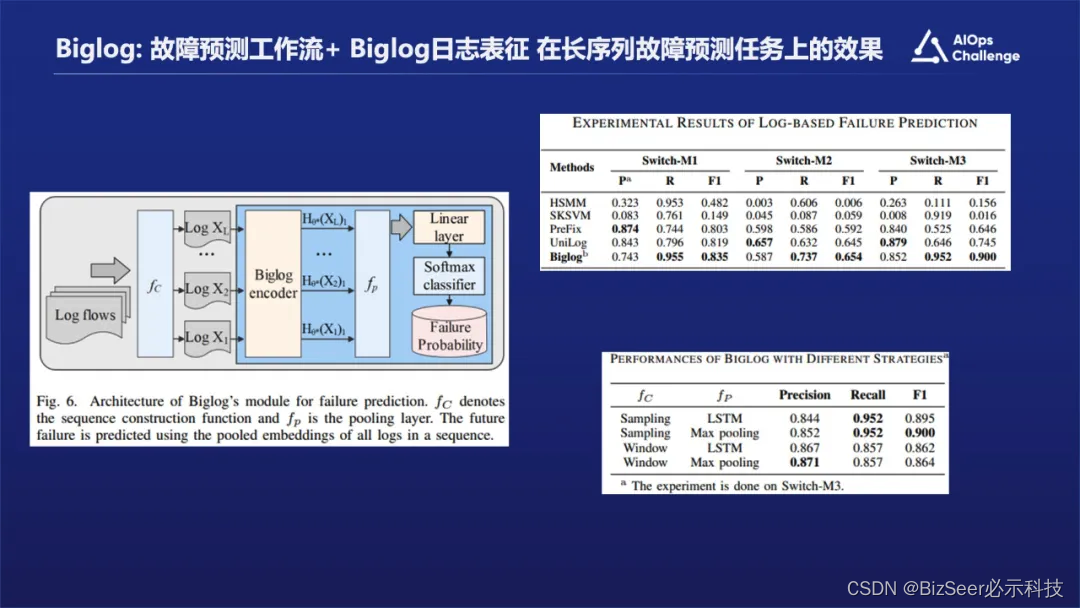
在故障预测方面,Biglog和Unilog的对比结果显示效果还是挺不错的。这可能代表它在长距日志依赖上能有效识别故障发生。

通过实验我们发现在领域迁移性方面,Biglog比LogTransfer表现的要好。另外我们做异常检测的时候,发现在Few-shot或者Zero-shot这块,模型也有很好的泛化能力。总体来说,当给它大概20个左右的samples时候,就已经可以达到非常不错的效果了。
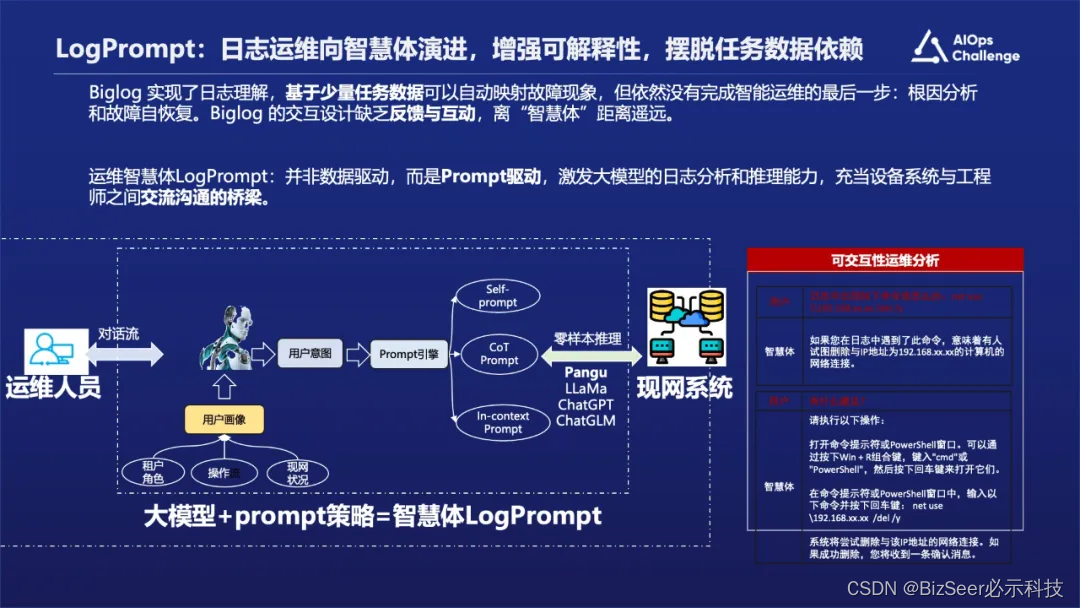
下面我们介绍LogPrompt。
我们完成BigLog之后开始推进LogPrompt的研究工作,也是因为我们团队是做与机器翻译领域的工作,对大语言模型比较敏感。当大语言模型出现之后,我们马上就想到是不是能够用来做日志相关的一些工作,是否能够有一个比较好的方式去尝试去解决可解释性问题以及它的标注问题。
我们尝试了Prompt+LLM的机制,只要采用简单的一些 cot的 prompt以及上下文的信息,就能够把日志的解释性以及它的交互性得到比较好的应用。

当然这依赖于一个基础模型,比如像华为的盘古大模型,即学习了人类语言的知识,也学习了机器相关的日志的信息,包括运维相关的信息。我们在这个能力之上,用一个高智能prompt去激发模型本身的能力。所以我们看到即使是零样本的时候,在异常检测还有相关的任务上面,效果也是表现的很好。

我们把LogPrompt放在华为乾坤云系统上,做一些实际的效果和应用。把我们的Prompt引擎放在乾坤云的 UI助手上面,相当叠加了外挂的知识库,也就是会有一个上下文增强的一个知识,然后基于这样知识,可以做到一些类似于LLM加Agent的效果,把一些API调用,能够做到比较好的精准反馈。
第四部分:未来畅想
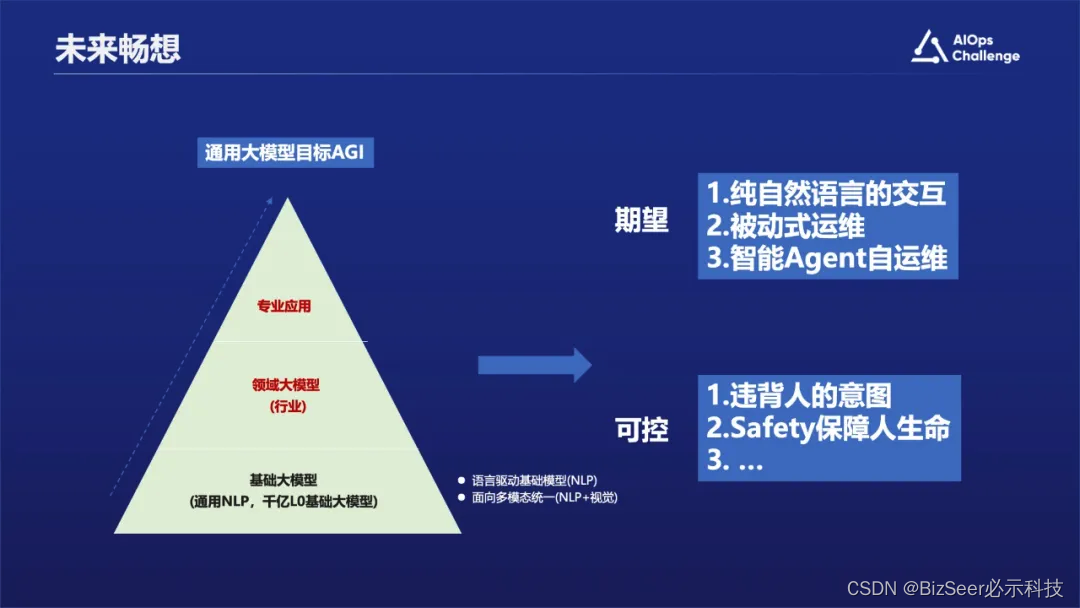
前面的各位专家已经分析了大语言模型可能带来的效果,从期望角度来说未来运维工作有可能是一个纯自然语言的交互,本身自然语言就是一个比较好的交互方式;也可能是被动式运维,当出现问题之后需要通过语言查询获取反馈结果;或者是智能化的Agent级的自运维,比如网络自动驾驶等。当然可能会面临一个问题:运维系统或者 Agent本身可能会违背人的意图,造成安全隐患。假设它能控制Agent的话,我们怎么做到安全可控。
我的分享到此结束,谢谢大家。
观看完整演讲视频,请关注OpenAIOps社区视频号
这篇关于大语言模型及提示工程在日志分析任务中的应用 | 顶会IWQoS23 ICPC24论文分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







