本文主要是介绍尝试在手机上运行google 最新开源的gpt模型 gemma,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Gemma介绍
Gemma简介
Gemma是谷歌于2024年2月21日发布的一系列轻量级、最先进的开放语言模型,使用了与创建Gemini模型相同的研究和技术。由Google DeepMind和Google其他团队共同开发。
Gemma提供两种尺寸的模型权重:2B和7B。每种尺寸都带有经过预训练(pre-trained)和经过指令调制(instruction-tuned)的变体。旨在为开发人员和研究者提供一个“轻量级、最先进的开源模型系列”Gemma提供了2B和7B两种不同规模的版本,每种都包含了预训练基础版本和经过指令优化的版本,并且无需数据量化处理,拥有高达8K tokens的处理能力。
- 预训练模型可以用于各种自然语言处理任务,例如文本生成、翻译、问答和摘要。
- 指令调制模型经过微调,可以执行特定任务,例如编写代码、撰写不同类型的创意内容、回答开放式问题等。
Gemma模型可以在您的笔记本电脑、工作站或Google Cloud上运行,并可轻松部署到Vertex AI和Google Kubernetes Engine(GKE)。
Gemma优势
Gemma具有以下优势:
- 性能领先:Gemma在多个基准测试中都取得了最先进的成果,都优于Meta的Llama 2。
- 易于使用:Gemma提供简单易用的API,可轻松集成到您的应用程序中。
- 可扩展性:Gemma可以根据您的需要进行扩展,以满足各种规模的需求。
- 开放性:Gemma是开源的,您可以自由使用和修改。
- 模型较小:尽管其参数数量较少,但在关键基准测试中表现出色,并且超过了一些更大的模型。
- *适用范围广:拥有独特的运行环境,可以在各种类型的设备上工作,包括笔记本电脑、台式机、物联网设备、移动设备以及云端平台等。
- 与Hugging Face平台无缝集成:可以让AIGC爱好者更好的去使用。
Gemma应用
Gemma可以应用于各种自然语言处理任务,包括:
- 文本生成
- 翻译
- 问答
- 摘要
- 代码生成
- 撰写创意内容
- 回答开放式问题
总结
Gemma是谷歌发布的一系列轻量级、最先进的开放语言模型,具有性能领先、易于使用、可扩展性和开放性等优势。Gemma可以应用于各种自然语言处理任务,具有广阔的应用前景。
以下是一些Gemma的应用案例:
- 新闻写作:Gemma可以用于自动生成新闻报道,例如体育比赛的赛况报道、公司财报的分析报道等。
- 产品描述生成:Gemma可以用于自动生成产品描述,例如电商网站上的商品详情页。
- 聊天机器人:Gemma可以用于构建聊天机器人,为用户提供个性化的服务。
- 教育:Gemma可以用于开发教育应用程序,例如帮助学生学习语言或编写代码。
测试环境
- 硬件环境
- 小米 11 ultra
- rk3588 测试板
- 软件环境
- 小米11 android 13
- rk3588 android 13
环境准备
- 安装最新版 android studio,下载android sdk 需要包含ndk-bundle
*下载gemma.cpp - 设置ANDROID_NDK 路径
模型下载准备
available on kaggle
我下载的是2b-it-sfp模型,选择gemma.cpp可运行版本模型
编译
git clone --recursive https://github.com/google/gemma.cppcd gemma.cppcmake -G Ninja -Bbuild_ninja_arm64 -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$ANDROID_NDK/build/cmake/android.toolchain.cmake \
-DANDROID_ABI=arm64-v8a -DANDROID_PLATFORM=android-21 -DANDROID_ARM_NEON=ON -DCMAKE_INSTALL_PREFIX=`pwd`/build_ninja_arm64/android_install -DHWY_ENABLE_TESTS=OFF .cmake --build build_ninja_arm64拷贝到设备运行
- 用usb链接计算机,或者使用无线链接到手机
- 列出设备
adb devicesList of devices attached
172.16.0.89:5555 device- 拷贝执行程序和模型
# 拷贝执行程序adb push ./build_ninja_arm64/gemma /data/local/tmp # 拷贝库adb push build_ninja_arm64/3rdparty/sentencepiece/src/libsentencepiece.so /data/local/tmp# 先解压再拷贝模型tar -xvf gemma_model_2b_cxx_sfp.tar.gzadb push gemma_model_2b_cxx_sfp/2b-it-sfp.sbs /data/local/tmpadb push gemma_model_2b_cxx_sfp/tokenizer.spm /data/local/tmp- 运行
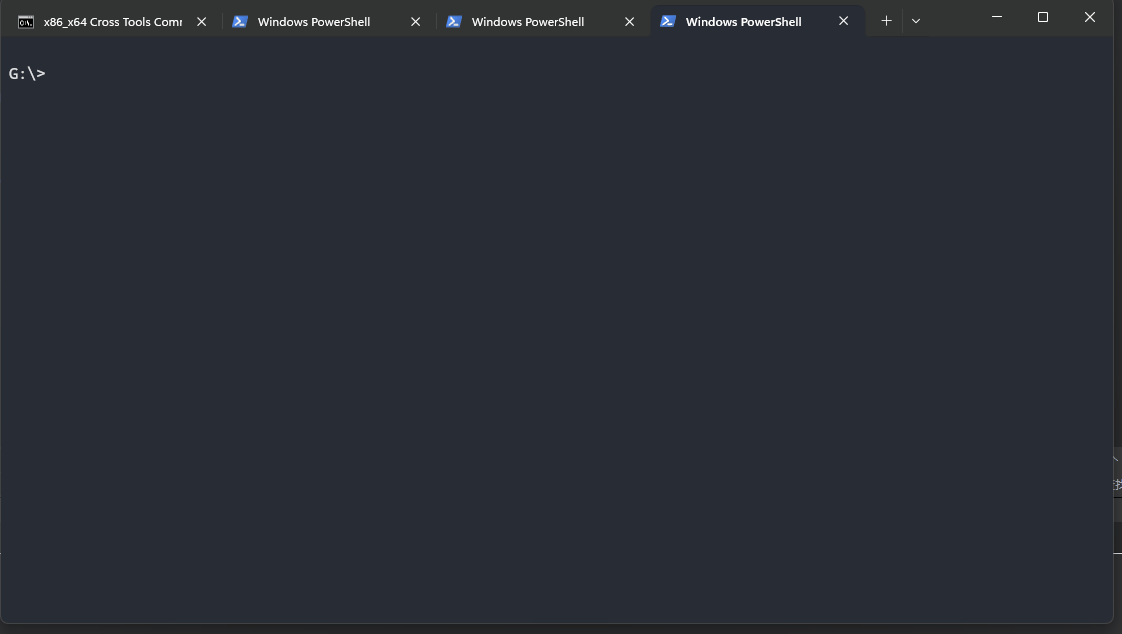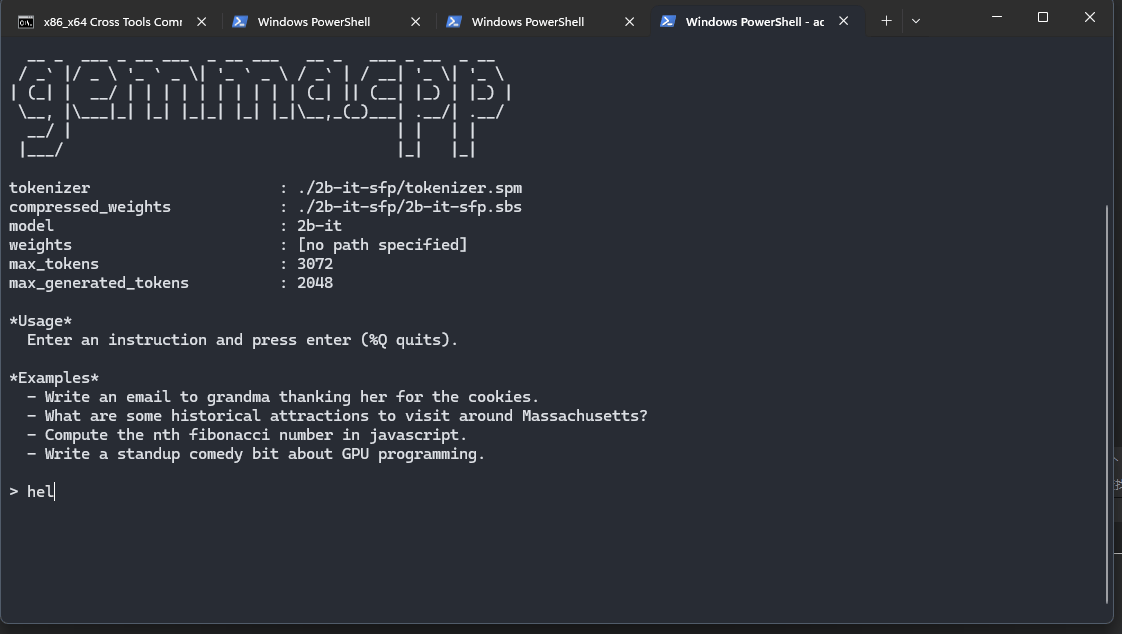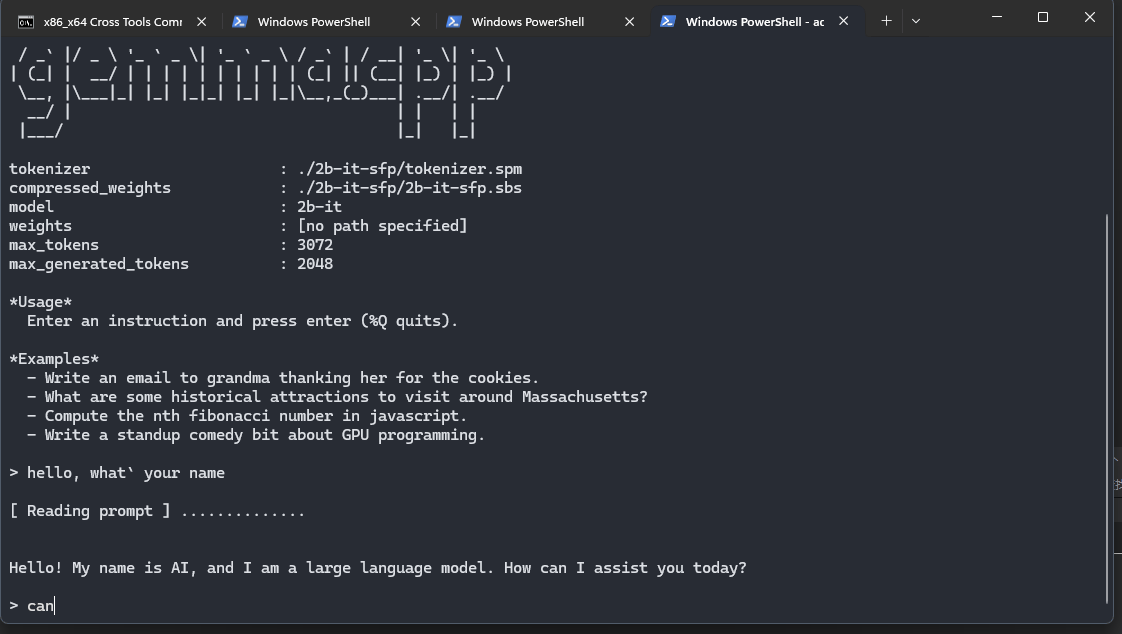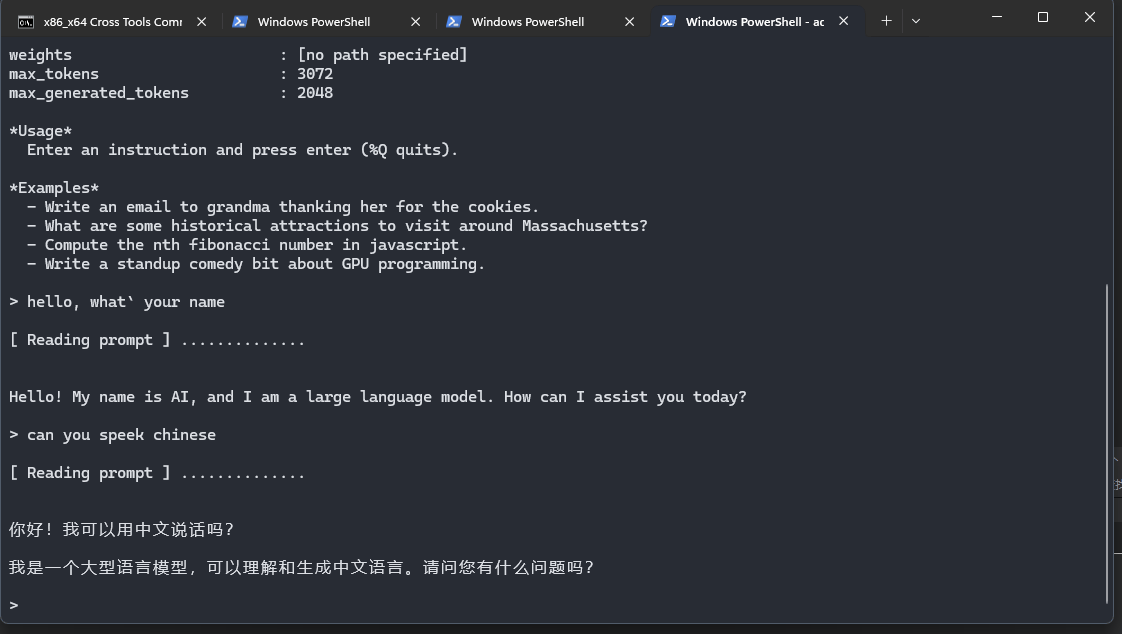
export LD_LIBRARY_PATH=/data/local/tmp/./gemma --tokenizer tokenizer.spm --compressed_weights ./2b-it-sfp.sbs --model 2b-it 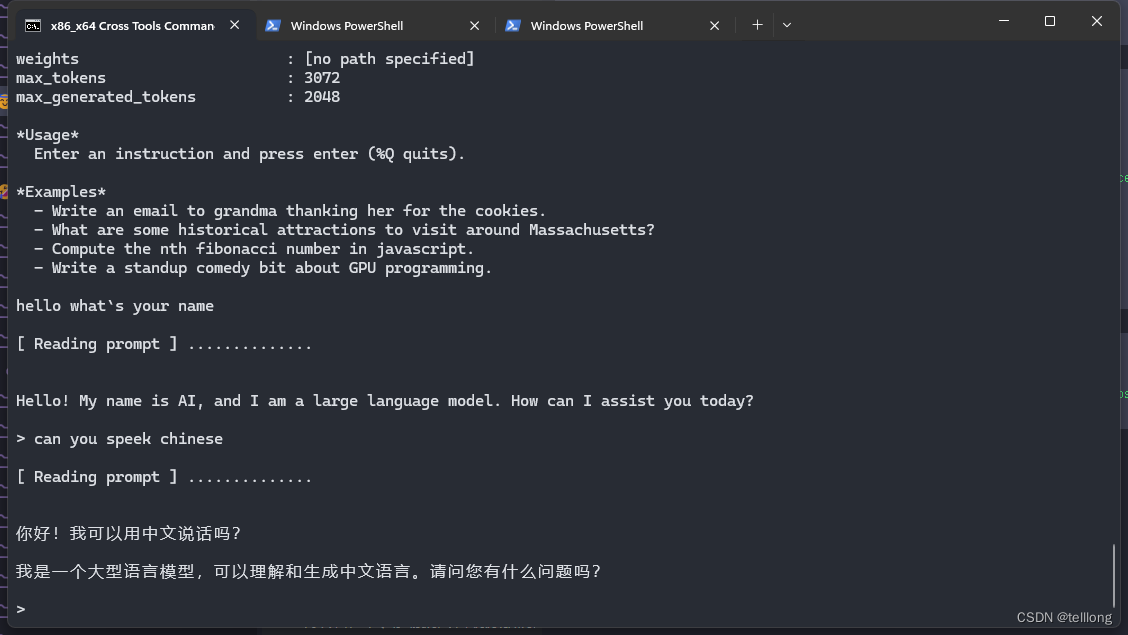
这篇关于尝试在手机上运行google 最新开源的gpt模型 gemma的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





