本文主要是介绍LLM - Ruozhiba <Quality> is All You Need,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
引言
1.COIG-CQIA Data
2.Ruozhiba Performance
3.Ruozhiba Data
4.More Ruozhiba Data
5.Some thoughts
引言
近期弱智吧 [后续以 Ruozhiba 代替] 的数据集在中文 LLM 场景的 Fine-Tuning 效果大火。众所周知,在当前 LLM 的大环境下,足够优秀的数据对模型的 Fine-Tuning 效果影响很大,以至于很多优秀的微调样本 Label 都来自 GPT-4 标注,这次我们也是借此机会,对 Ruozhiba 的数据集一探究竟,看看究竟是什么样的数据集才更利于模型的微调。
1.COIG-CQIA Data
Attention is All You Need,相信这篇文章大家一定不会陌生,而近期:
Quality is All You Need for Chinese Fine-tuning
一文介绍了中文数据集及其对应微调效果,也是在这篇论文中,作者引入了高质量的中文数据集 COIG-CQIA,该数据集是一个高质量的中文指令微调数据集,其从中国互联网的各种来源收集了高质量的人工编写的语料库,包括 Q&A 社区、Wikis、考试和现有的 NLP 数据集。该语料库经过严格过滤和仔细处理以形成 COIG-CQIA 数据集。此外,作者按照深入的评估和分析,在 CCIA 的不同子集上训练不同尺度的模型。通过实验发现,来自于百度贴吧-弱智吧的数据在微调 Fine-Tuning 后,在多个指标上领先于其他社区与平台。
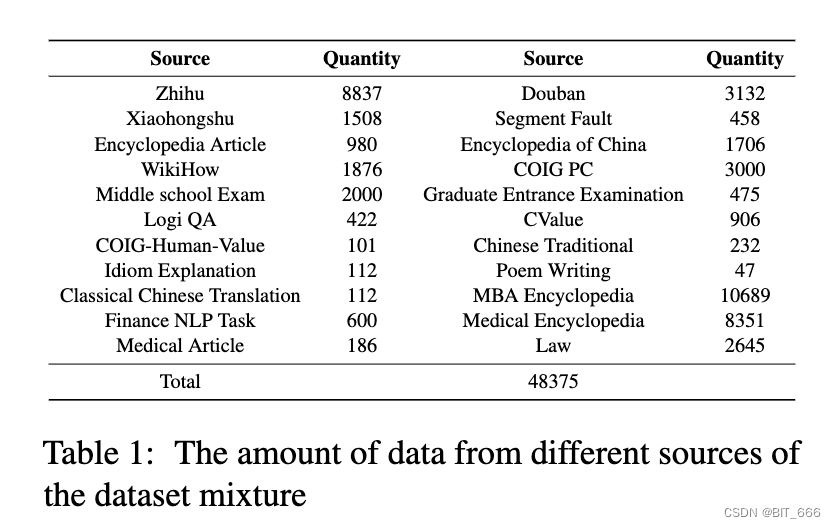
上表展示了混合数据集的构成,其中数量较多的是 MBA Encyclopedia [MBA 百科全书] 和 Zhihu [知乎],也有热门的社区例如 Xiaohognshu [小红书] 和 Douban [豆瓣],共计 48375 条数据。
2.Ruozhiba Performance
Ruozhiba 是百度 Tieba 的一个子论坛,这是一个基于兴趣的社区论坛。它的帖子通常包含双关语、多义词、因果反转和同音词,其中许多都是用逻辑陷阱设计的,即使对于人类也带来了挑战。我们收集了 500 个投票最多的线程。使用标题作为说明,我们消除了那些非建设性(即陈述性陈述或不可回答)或有毒的。响应 Response 由人类或 GPT-4 生成。我们对 GPT4 响应进行了人工审查,以确保准确性,最终获得 240 个(Instruction, Response)对。
- Performance On Yi-6B
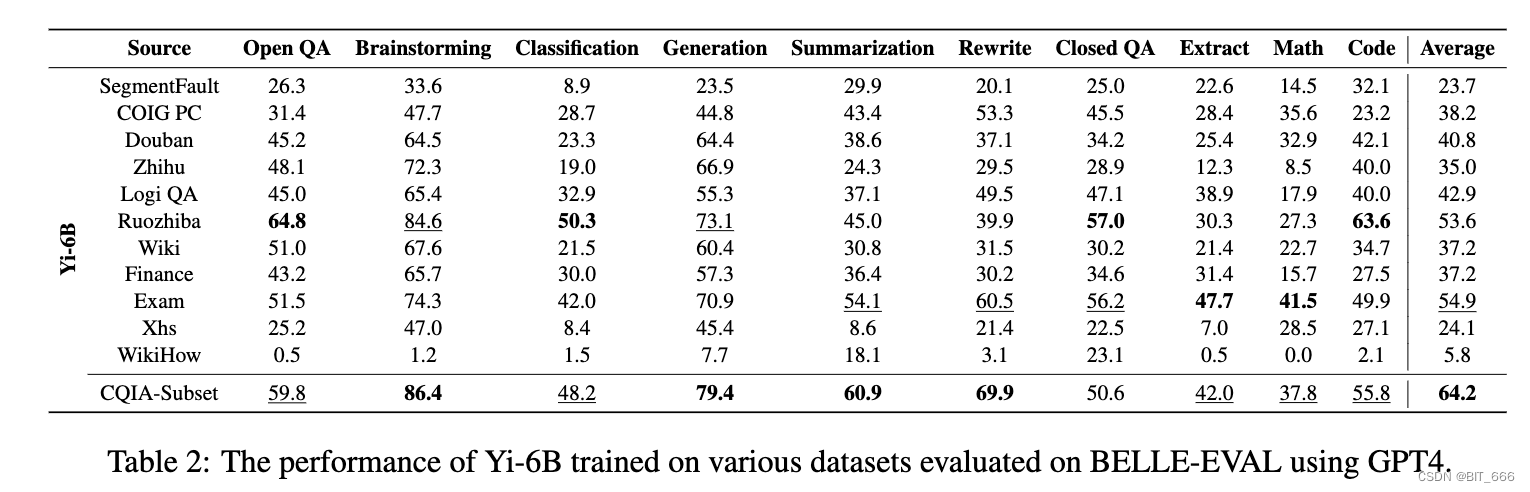
使用 GPT4 在 BELLE-EVAL 上评估的各种数据集上训练的 Yi-6B 的性能,其中 Ruozhiba 在多项指标上遥遥领先, 例如 Open QA、Brainstorming、Code 等。
- Performance On Yi-34B
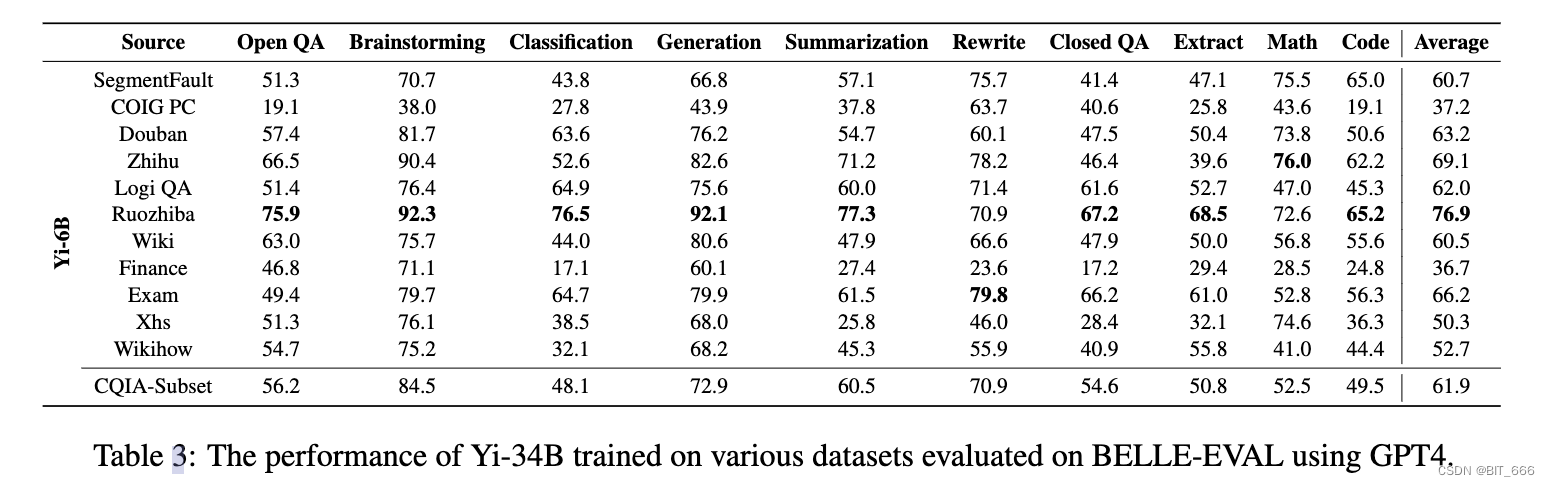
使用 GPT4 在 BELLE-EVAL 上评估的各种数据集上训练的 Yi-34B 的性能,Ruozhiba 基本保持了 Yi-6B 上的表现。
- SafetyBench Score on Yi-6B
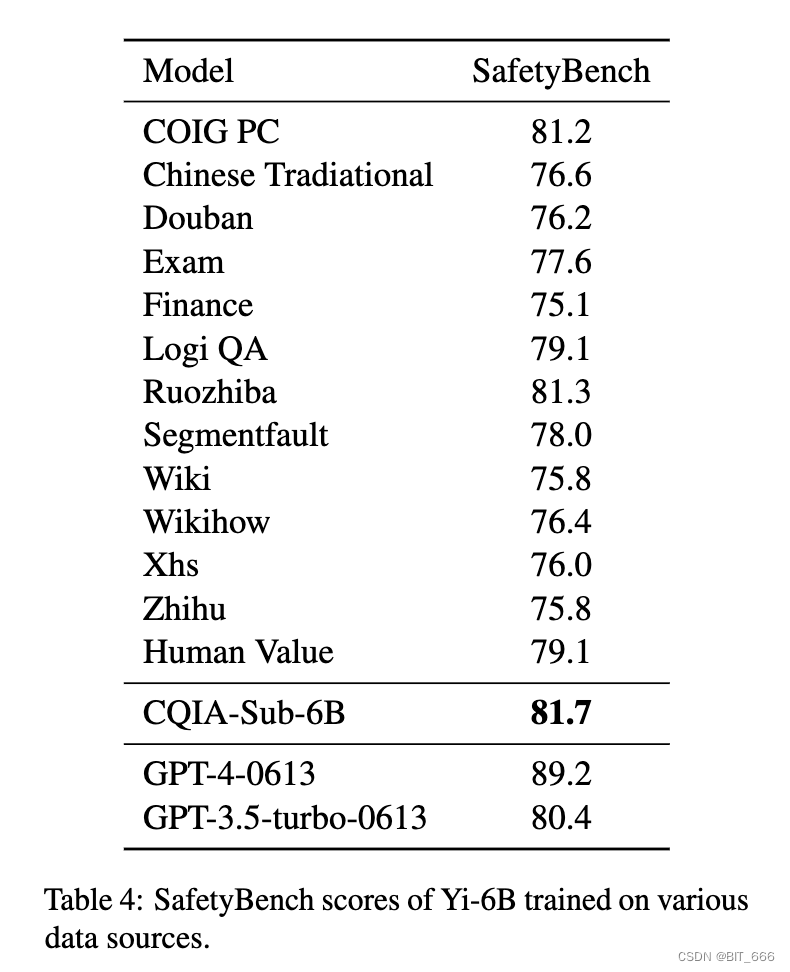
在各种数据源上训练的Yi-6B的安全基准分数,可以看到 Ruozhiba 数据集对应的安全基准分也很高。
3.Ruozhiba Data
论文中给出了 COIG-CQIA 数据集的地址: COIG-CQIA,可以在 Hugging-Face 上搜素:
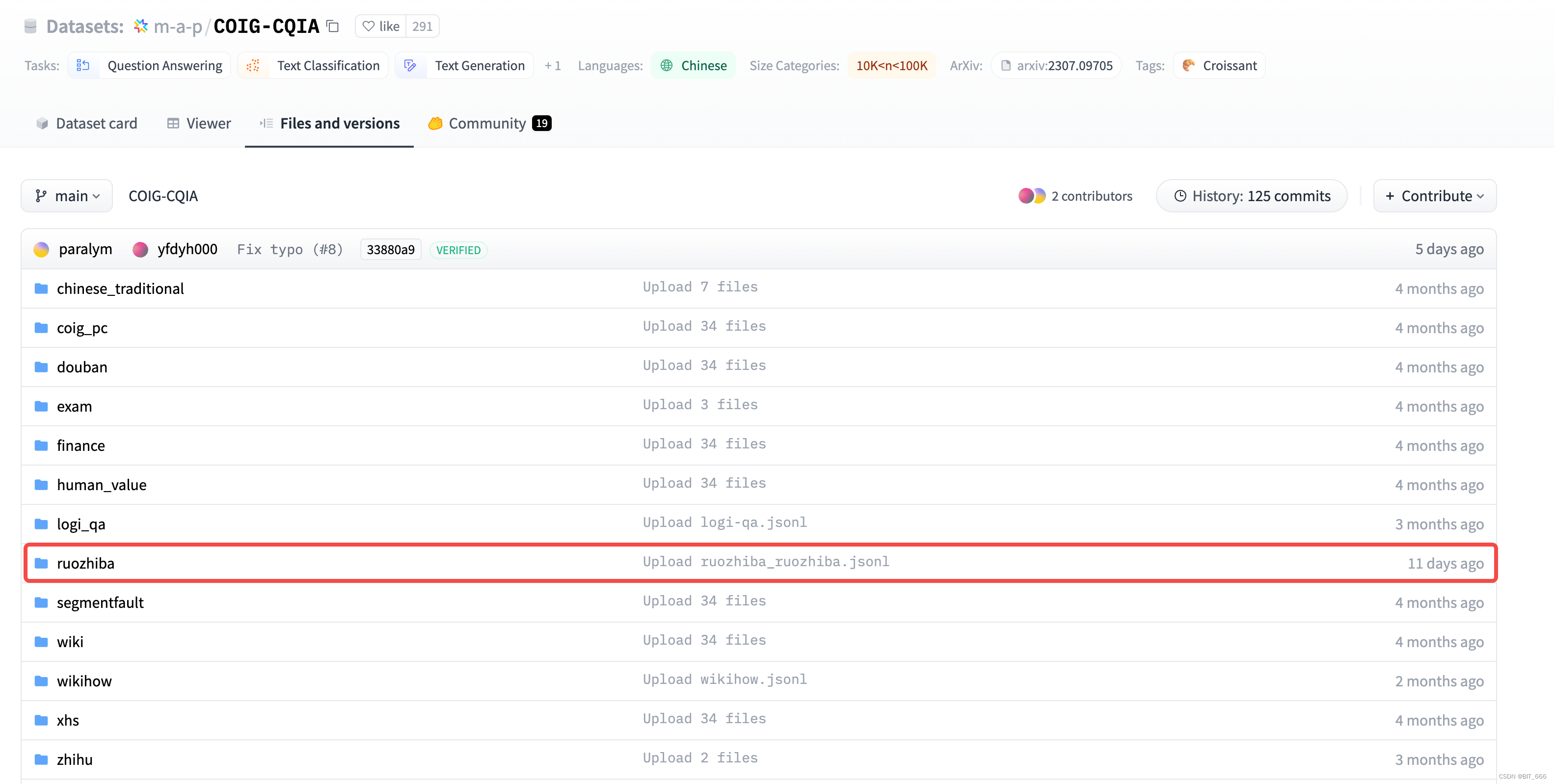
我们找到 Ruozhiba 数据集的文件夹,文件一共 267 kb,保存为 raw 格式:

下面我们找一条 QA pair 看看怎么个事情:

其主要的 (Instruction, Response) 由 instruction 和 output 指定,其中 task_type 定义了其问答的主次类型,domian 定义了其对应的领域,后面的 metadata 用于存放元数据,answer_from 标识 llm,hunman_verified 代表是否人类确认。 再回归到内容上,Ruozhiba 的提问确实比较有特点,而其生成来自 LLM 即 GPT-4,我们也是下载了 raw 文件对数据集做一个基本信息统计。其中共包含 240 条数据,Instruction 指令为 Ruozhiba 内容,Response 回复为 GPT-4 提供,下面博主整理一些有趣的指令,大家工作之余可以放松感受下:
| 石油也是油,为啥没人用它来炒菜? |
| 执行死刑时本人不去,委托律师去可以吗? |
| 鸡柳是鸡身上哪个部位啊? |
| 你只准备了5杯水,来了一亿个领导你应该怎么分配这些水 |
| 老师说提一分干掉千人,那我干掉千人是不是就相当于提了一分? |
| 既然生锈的刀砍人会让人得破伤风,古代为什么不直接用生锈的武器? |
| 司马懿为什么不找三个臭皮匠把诸葛亮顶住 |
| 我偷功德箱,那我的功德是增加了还是减少了 |
| 吃了降压药,为什么碰到高压电还是会死?🤔 |
| 喝饮料的时候一直有个疑问冰红茶是柠檬味的红茶还是红茶味的柠檬水 |
| 很多人说的看不到未来其实是看到了未来 |
| 银行是不是已经破产了,为什么我每次取钱都显示余额不足? |
| 完美的人会不会因为缺少缺点而变得不完美?... |
| 既然大学生都喜欢坐后排为什么老师不在教室后面讲 |
| 兄弟们,为什么每条隧道上面都压着一座山 |
| 游泳比赛时把水喝光后跑步犯规吗 |
| 失踪是不是丢人的事情? |
| 我做了一个1:1的地球仪,你往窗外看就能看见了 |
| 喝奶茶 用吸管喝的是下面的水 为什么少的是上面的水 |
| 妈妈说:“我的天才考59分”是不是在夸我是天才? |
4.More Ruozhiba Data
上面 COIG-CQIA 数据集中 Ruozhiba 的数据只有 240 条,一些同学可能觉得不太够用,好在已经有同学在 github 上做了分享,大家可以参考: GitHub - Leymore/ruozhiba
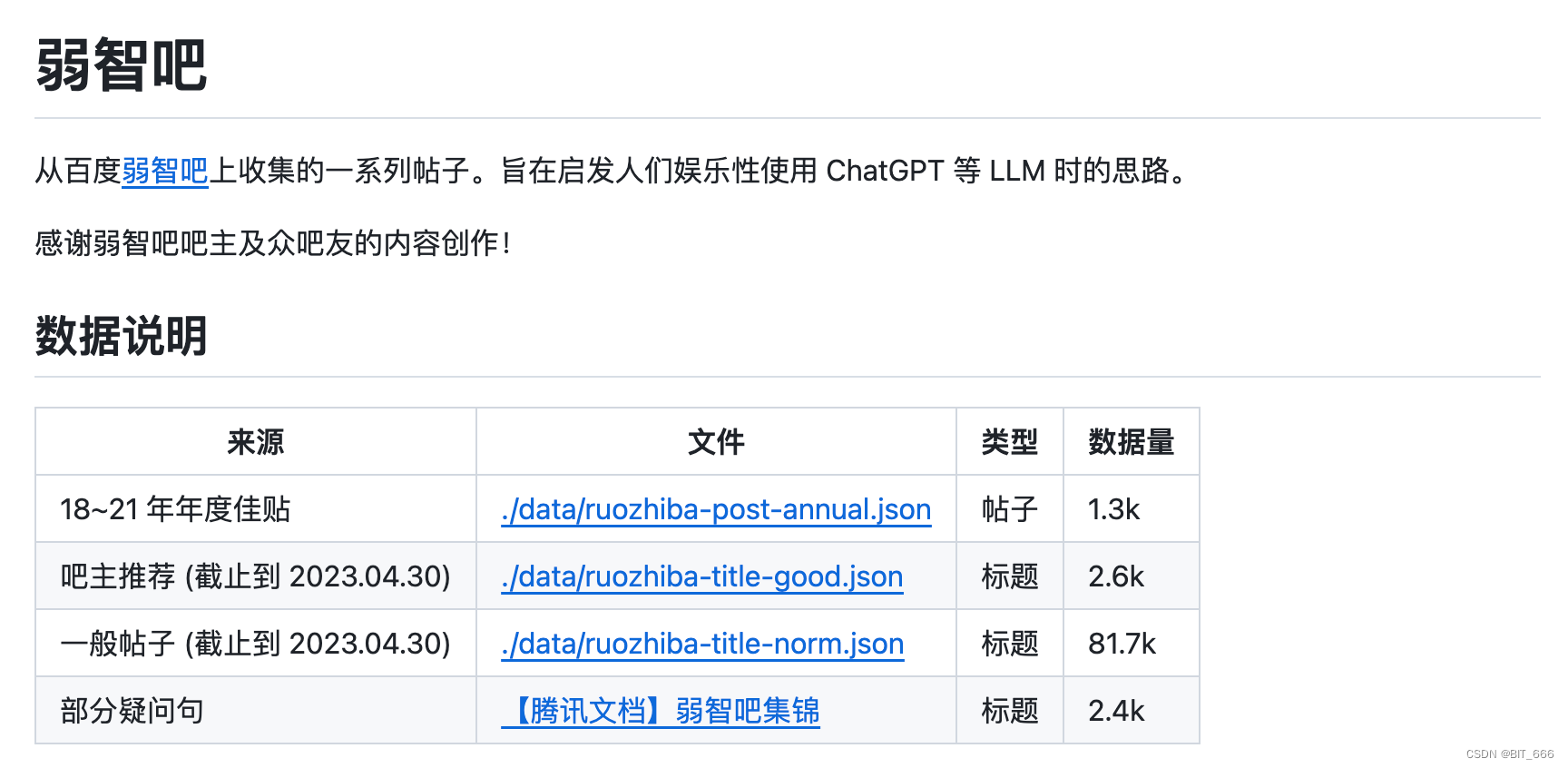
这里按照不同类型收集了接近 10w 条原始 Ruozhiba 数据,大家可以根据自身情况构建 Instruction 并使用 LLM 构建 Response 从而 DIY 自己的个性大语言模型。
5.Some thoughts
先看下 Ruozhiba 数据在论文中的介绍:
Ruozhiba 是百度 Tieba 的一个子论坛,这是一个基于兴趣的社区论坛。它的帖子通常包含双关语、多义词、因果反转和同音词,其中许多都是用逻辑陷阱设计的,即使对于人类也带来了挑战。我们收集了 500 个投票最多的线程。使用标题作为说明,我们消除了那些非建设性(即陈述性陈述或不可回答)或有毒的。响应 Response 由人类或 GPT-4 生成。我们对 GPT4 响应进行了人工审查,以确保准确性,最终获得 240 个(Instruction, Response)对。
有一些角度可以供我们借鉴并应用在后续的 LLM 工作中:
- 逻辑陷阱
Ruozhiba 的数据包含很多双关、多义、因果反转和同音词等,其基于逻辑陷阱涉及,本质上是更多样性或者更特别的数据,其可以给模型带来新的知识;另一方面,一些难以理解的知识本质上其实是在增加模型学习的难度,就像 Casual Mask 的设置一样,增加难度后提高模型的学习能力。
- 非建设性
选取标题后,我们消除了陈述性或不可答或者有毒的数据,这其实对应一个基础的数据清洗过程,在原数据处理以及 Prompt 构建时,这些信息都应该注意。
- GPT Response
我们通过 GPT-4 的响应获取了 240 条数据,其中通过人工审查确保其准确性。一方面说明了 GPT-4 数据生成方法的可行性,可以看到即使只有 240 条数据,但由于其质量较高,依然可以通过 Fine-Tuning 获得不错的效果。另外就是准确性的问题,不管是人工审查还是其他方式,Response 的准确性对模型的 Fine-Tuning 效果也至关重要。
- Quality is All You Need for Chinese Instruction Fine-tuning
最后回到论文的标题,Quality is All You Need - 数据质量在我们 Fine-Tuning 的工作中非常关键,在当前 LLM 模型整体框架不会大变 [Transformer] 的情况下,应该秉承宁缺毋滥的态度,可以看到 240 条的高质量数据可以在表现较好的模型上获得更好的效果。
这篇关于LLM - Ruozhiba <Quality> is All You Need的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)



![[论文笔记] LLM大模型剪枝篇——2、剪枝总体方案](/front/images/it_default.gif)



