本文主要是介绍聊聊最近“大火”的RAG,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
LLM支持的最强大的应用程序之一是复杂的问答(Q&A)聊天机器人。这些应用程序(聊天机器人)可以回答有关特定来源信息的问题。其中使用的技术就是一种称为检索增强生成(RAG)的技术。
本文不涉及代码输出,纯概念解释说明。文末会贴出另一篇文章的地址,里面有代码。
什么是RAG
RAG是一种利用检索技术来增强大语言模型(LLM)的技术。它通过从某些数据源检索信息,并将这些信息作为上下文提供给LLM,从而改进生成的答案。
RAG的基本流程包括:
-
分块与向量化:将文本数据分割成块,并使用transformer编码器模型将这些块编码为向量,以便于搜索。
-
搜索索引:为这些向量建立索引,以便于快速检索。
-
重排和过滤:对检索到的信息进行排序和过滤,以提供最相关的上下文给LLM。
-
查询转换:将用户查询转换为模型可以理解的格式。
-
聊天引擎:用于与用户进行交互,接收用户输入并返回回答。
-
查询路由:决定哪些查询应该被发送到LLM进行回答。
-
智能体:负责协调各个组件,确保系统的顺畅运行。
-
响应合成:将LLM的输出与检索到的上下文合并,生成最终的回答。
RAG的优点在于它能够结合检索技术的准确性和LLM的生成能力,提供更加准确和丰富的回答。然而,它也面临一些挑战,如知识的局限性和数据安全性问题。知识的局限性意味着模型的知识仅限于其训练数据,可能无法覆盖所有领域的知识。数据安全性问题则涉及到将私域数据上传到第三方平台的风险,这对于注重数据安全的企业来说是一个重要的考虑因素。
简单来说就是:大模型对于没有学习过的知识是回答不了的,或者说回答不准确,不相关,利用RAG技术就可以很好的解决这种问题。
RAG架构
典型的RAG应用程序有两个主要组件:
-
索引:从外部数据源引入数据并制作索引。通常我们会预先处理好数据。
-
检索和生成:它需要用户在运行时查询并从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案最常见的完整序列如下所示:
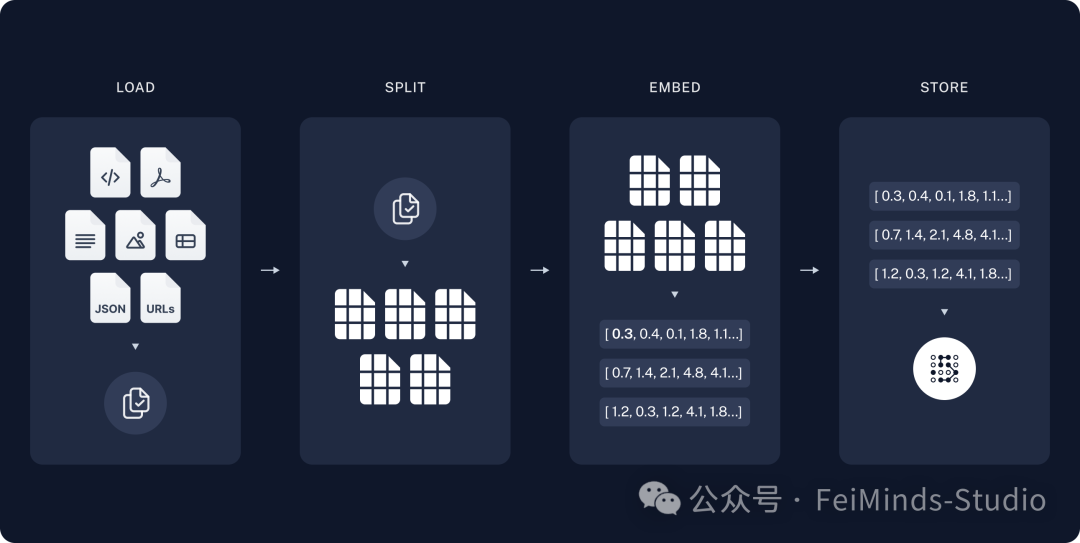
索引(Indexing)
-
加载(Load):首先我们需要加载数据。这是使用DocumentLoaders完成的。
-
切片(Split):文本 分离器将大块分成更小的块。这对于以下方面都很有用 索引数据并将其传递到模型,因为大块更难搜索,并且不适合模型有限的上下文窗口。
-
存储(Store):我们需要某个地方来存储和索引我们的拆分,以便以后可以搜索它们。这通常是使用VectorStore(向量数据库)和Embeddings(词嵌入)模型完成的。
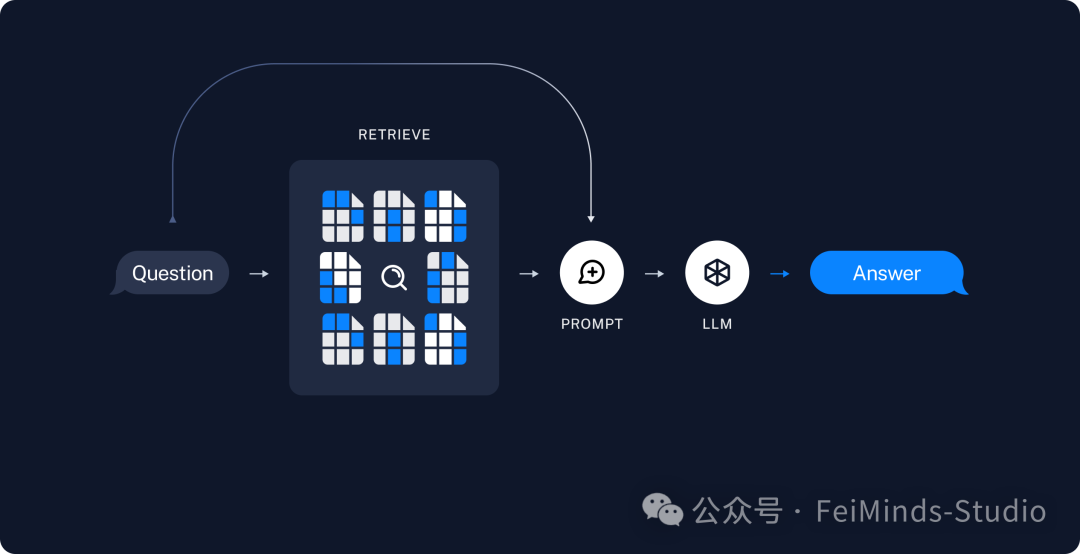
检索和生成(Retrieval and generation)
-
检索(Retrieve):给定用户输入,使用Retriever从存储中检索相关切片。
-
生成(Generate):ChatModel / LLM使用包含问题和检索数据的提示。
实现自己的RAG应用
“智能客服”是RAG的典型应用之一,这块实际上已经介绍过了,看下面这篇文章就行。
【可能是全网最丝滑的LangChain教程】四、快速入门Retrieval Chain
这篇关于聊聊最近“大火”的RAG的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






