本文主要是介绍iPhone上最强模型出现!性能超越GPT-4,Siri有救啦?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
你有多久没用你的Siri了呢?对于一个曾市值超过三万亿美元的科技巨头,苹果在人工智能方向上的实力还值得大家期待吗?

最近的一项论文里,苹果的研究团队提出了一种 ReALM 模型,参数量分别为 80M、250M、1B 和 3B,适合在手机、平板电脑等设备端运行。
ReALM 通过将引用解析问题转化为语言建模问题,在解决各种类型引用解析问题上取得了显著的进展,它的能力还要超过GPT-4!
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com

ReALM 不仅可以处理对话中的实体引用,还能准确解析屏幕上显示的实体以及背景进程中的信息,为用户提供更智能、更人性化的交互体验。
Siri 这类人工智能语音助手可以借助这项技术,通过分析用户的对话历史、屏幕上显示的内容以及背景进程中的信息,来更好地理解用户的查询和指令。
简单来说,这是一项可能将你的 Siri 盘活的技术!
论文标题:ReALM: Reference Resolution As Language Modeling
论文地址:https://arxiv.org/abs/2403.20329
试试考考你的Siri
人类的语音通常包含模糊的引用,比如 “他们” 或 “那个”,在给定上下文的情况下(对其他人来说)意义明显。
对于一个旨在理解用户需求并与之对话的智能助手来说,能够理解上下文和这些引用信息,是至关重要的。
至于你的 Siri 真的能理解上下文和引用信息嘛?iPhone用户自然深有体会,不如用参照下面这个例子来“为难”一下 Siri 吧。
表1. 用户和代理之间的交互示例。

在这里,很明显,Siri 需要理解上下文才能明白位于“彩虹路”的药店电话是多少。
同时,这里还有多种类型的上下文,比如 eg 1 提及的药店可能在对话上下文中提到,eg 3 要引用当前屏幕中的上下文,而 eg 2 可能同时要考虑对话上下文和屏幕上下文。
如果这样考你的 Siri,它怕是要汗流浃背了吧。

Siri 如何理解用户“所指”?
从具体的任务看,给定相关实体和用户想要执行的任务,Siri,或者说 Siri 调用的模型应该提取出与当前用户查询相关的实体。
而相关实体有 3 种不同类型:
-
屏幕上的实体:这些是当前显示在用户屏幕上的实体。
-
对话中的实体:这些是与对话相关的实体,例如,当Agent提供给用户整个商品列表的时候,某件商品就是对应的实体。
-
背景中的实体:这些是来自可能不一定直接与用户在屏幕上看到的内容,或与Agent的交互有关的后台进程的相关实体;例如,开始响铃的闹钟或正在播放的音乐。
作者将引用解析任务形式化为大语言模型的多选任务,其中预期输出是用户屏幕上显示的实体中的单个选项(或多个选项)。在某些情况下,答案也可能是 “这些都不是”。
为了评估这个任务,则要允许模型以任何顺序输出相关实体,即如果 “Ground Truth” 是实体 1 和 2,那么接受这 2 个正确实体的任何排列,同时评估模型的性能。
表2.

作者使用以下 Pineline 对 LLM (FLAN-T5 模型) 进行微调,将解析后的输入提供给模型,并对其进行微调:
-
首先,通过解析屏幕截图来获取屏幕上显示的实体和它们周围对象的信息。
-
对于会话引用,根据实体类型和属性将它们编码为自然文本表示。
-
对于屏幕引用,提出一种使用旋转对象注入的屏幕解析构造算法,该算法通过对实体及其周围对象进行空间聚类,并按照从上到下、从左到右排序来保留相对位置关系。
-
将经过处理后的输入提供给 LLM 模型,并进行微调训练。
通过这个 Pipeline,模型能够有效地解决不同类型引用问题,并取得了比之前方法更好的性能。
性能堪比GPT4!80M参数也OK!
作者将提出的模型(基于 FLAN-T5)与两个基线进行了比较:一种是基于规则的文本解析方法(不使用LLM),另一种则是GPT系列,包括GPT-3.5和GPT-4。
表2. 不同数据集的模型准确性。 预测正确是指模型正确地预测了所有相关实体,否则是错误的。 Conv 是指对话数据集,Synth 是指综合数据集,Screen 是指屏幕上数据集,Unseen 是指与保留域相关的对话数据集。
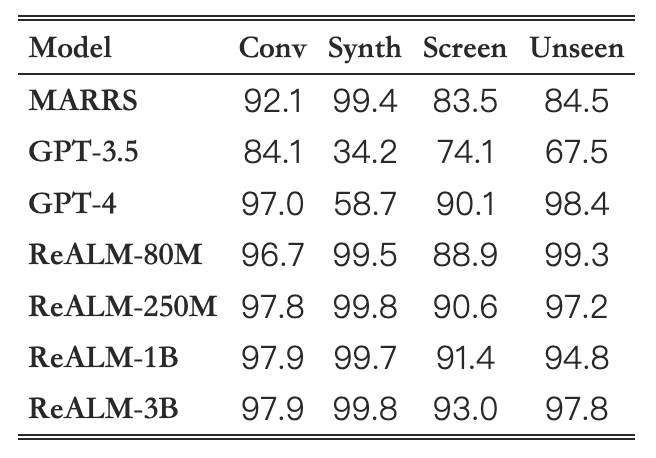
总的来说,作者发现 ReALM 在所有类型的数据集中都优于 MARRS 模型。
同时,ReALM 系列的模型更轻(更快),并且所有数据集上的性能随着模型大小的增加而提高。
其中 80M 模型在三个数据集上与 GPT-4 性能相当,在 Synth 数据集上则大幅领先;更大的模型则是显著地超越了 GPT-4!
这项结束将有望改善语音助手,从而使它可以更准确地回答用户的问题、执行任务和提供帮助。
据报道,苹果将于6月10日在位于美国加利福尼亚州的 Apple Park 举行的 WWDC 2024 上公布其 AI 战略。让我们期待一下届时苹果会给出一个怎样的惊喜吧!希望 Siri 不要只会定闹钟了(bushi)

这篇关于iPhone上最强模型出现!性能超越GPT-4,Siri有救啦?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








