本文主要是介绍R语言lavaan结构方程模型在生态学研究中的应用介绍及要点回顾,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
除了一般的线性回归外,SEM可以用于探究:测量不变性(Measurement invariance)、多组模型(Multiple group modelling)、潜在增长模型(Latent growth modeling)、非线性混合模型(Nonlinear mixed-effects model)、多层模型(Hierarchical/multilevel models、混合模型(Mixture model)、多方多质(Multi-method multi-trait models)等等。其中最常见有两种情形,一种是验证问卷的结构,也即验证性因素分析(confirmatory factor analysis,CFA)。这种情景下,一个概念或者特质包括多个题目,我们的目标是这些题目是否拟合我们所假设的结构,也即测量模型。第二种情况是,同步进行分数合成和回归分析。我们需要知道任何测量都是有误差的,心理学和教育学测量更是如此。这种情况下,我们通常收集了很多个维度的数据,我们对于维度间的关系存在合理假设,例如中介作用或者路径分析等,这时候就需要在CFA和回归相结合(测量模型+结构模型),也就是SEM大显神通的时候。
结构方程模型(Sructural Equation Modeling,SEM)是分析系统内变量间的相互关系的利器,可通过图形化方式清晰展示系统中多变量因果关系网,具有强大的数据分析功能和广泛的适用性,是近年来生态、进化、环境、地学、医学、社会、经济等众多领域应用十分广泛的统计方法。在R语言结构方程程序包中,lavaan具有简洁的语法结构、成熟模型构建和调整过程和稳定可靠的结果等特点,使其不亚于收费商业软件,是最受欢迎的结构方程模型程序包之一。
基于R语言lavaan程序包,通过理论讲解和实际操作相结合的方式,由浅入深地系统介绍结构方程模型的建立、拟合、评估、筛选和结果展示的全过程。我们筛选大量经典案例,这些案例来自Nature、Ecology、Ecological Applications、Journal of Ecology、Oikos及Ecography等主流期刊,具有很大的参考和借鉴价值。训练内容包括R语言入门、结构方程模型原理简介、lavaan包简介及应用案例、潜变量分析、复合变量分析、非线性/非正态/缺失数据、分类变量、分组数据、嵌套/分层/多水平数据、重复测量和时间数据、空间数据及非递归模型。
R/Rstudio简介及入门
1) R及Rstudio介绍:背景、软件及程序包安装、基本设置等
2) R语言基本操作,包括向量、矩阵、数据框及数据列表等生成和数据提取等
3) R语言数据文件读取、整理(清洗)、结果存储等(含tidverse)
4) R语言基础绘图(含ggplot):基本绘图、排版、发表质量绘图输出存储



结构方程模型(SEM)介绍
1) SEM的定义、生态学领域应用及历史回顾
2) SEM的基本结构
3) SEM的估计方法
4) SEM的路径规则
5) SEM路径参数的含义
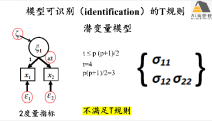
6) SEM分析样本量及模型可识别规则
7) SEM构建基本流程
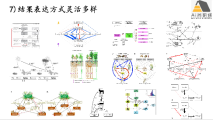
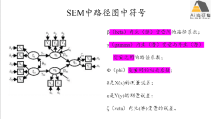
lavaan包讲解及应用案例
1) 结构方程模型在生态学研究中的应用介绍及要点回顾
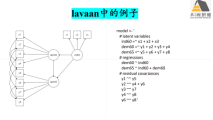
2) lavaan简介、语法及结构方程模型分析入门
3) lavaan结构方程模型构建应用案例
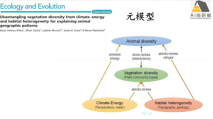
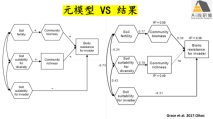
(1)问题提出、元模型构建
(2)模型构建及模型估计
(3)模型调整:路径删减和增加原则
(4)模型评估:最优模型筛选
(5)结果表达


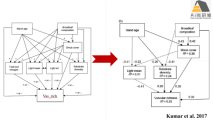
lavaan潜变量分析
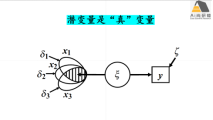
1) 潜变量的定义、优势及应用背景分析
2) 潜变量分析lavaan实现基本原理
3) 案例1:单潜变量模型构建
4) 案例2:多个潜变量模型构建
lavaan复合变量(composite)分析
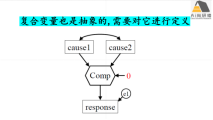
1) 复合变量的定义及在生态学领域应用情景分析
2) 复合变量分析lavaan实现途径
3) 案例1:单复合变量构建
4) 案例2:多复合变量构建

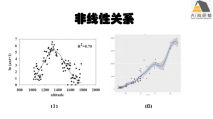
lavaan处理非线性/非正态/缺失数据
1) 非线性数据:外生变量及内生变量非线性关系
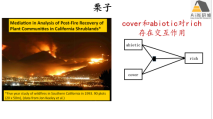
2) 变量间交互作用关系分析
3) 非正态数据vs非正态变量分析
4) 缺失数据处理方法

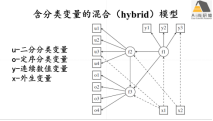
lavaan分类变量分析
1) 分类变量介绍
2) 外生变量为分类变量分析
3) 内生变量为分类变量分析


lavaan分组数据(multigroup)分析
1) 分组数据vs分类变量vs交互作用
2) 数据分组分析实现途径
3) 二分组及多分组模型分析及结果表达
包含潜变量模型分组分析

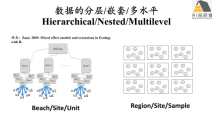
lavaan嵌套/分层/多水平数据分析
1) 嵌套/多水平/分层数据概述
2) 嵌套/多水平/分层数据结构结方程模型实现途径:lavaan vs lavaan.survey
3) 均衡和不均衡结构嵌套/多水平/分层数据结构方程实例
嵌套/多水平/分层数据潜变量模型

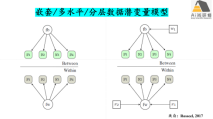
lavaan重复测量和时间数据分析
1) 时间重复测量数据特点简介
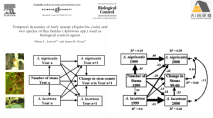
2) 时间/重复测量数据的交叉滞后模型(Autoregressive Cross-Lagged Model)
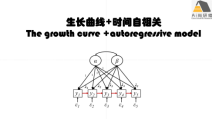
3) 时间/重复测量数据的生长曲线模型(Growth Curve Model)

lavaan空间自相关数据分析
1) 数据空间自相关概述
2) lavaan处理空间自相关数据基本原理
3) lavaan处理空间自相关问题实例



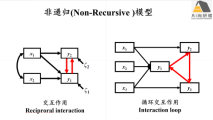
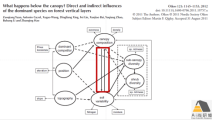
lavaan非递归模型分析
1) 递归模型与非递归模型区别
2) lavaan非递归模型分析注意事项及实现途径
3) lavaan非递归模型案例讲解

这篇关于R语言lavaan结构方程模型在生态学研究中的应用介绍及要点回顾的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







