本文主要是介绍【人工智能】海洋生物识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
海洋生物识别
台湾电力公司、台湾海洋研究所和垦丁国家公园在2010年10月1日至2013年9月30日期间,在台湾南湾海峡、兰屿岛和胡比湖的水下观景台收集的鱼类图像数据集。
该数据集包括23类鱼种,共27370张鱼的图像,都是RGB彩色图像,该数据集的目标是通过训练一个模型,使其能够正确地识别海洋生物的种类。每张图像都有对应的标签,表示图像中生物种类。因此,该数据集是一个经典的监督学习问题,其中输入是图像,输出是对应的生物种类标签。

图 1Fish4Knowledge23 数据集图像示例
本次实验,在跑完老师提供的 PaddlePaddle 代码的基础上,采用PaddlePaddle环境进一步训练模型,利用PaddlePaddle的可视化插件VisualDL进行训练模型过程的可视化。
另附代码见附录和.ipynb 文件。
本次实验,我主要比较了几种不同的经典神经网络在 Fish4Knowledge23 数据集上的表现,包括老师给的MYCNN,经典模型如MLP,LeNet , AlexNet,VGGNet和GoogLeNet。
-
-
- MYCNN
-
 |
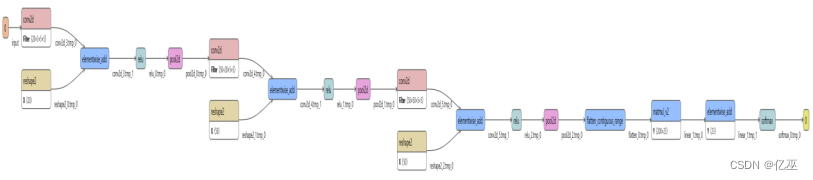
图 1 MYCNN网络结构
卷积层:执行卷积操作提取底层到高层的特征,发掘出图片“局部特性”;
池化层:通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数;
全连接层:池化完成后,将数据“拍平”,丢到Flatten层,然后把Flatten层的输出放到全连接层里,可采用softmax对其进行分类。
-
-
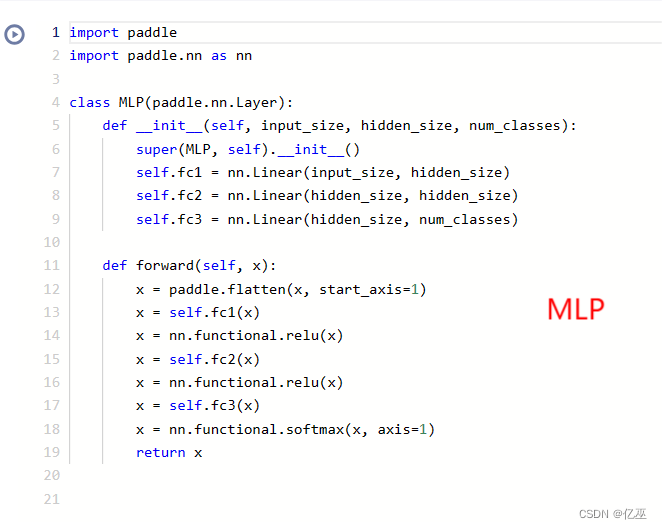
- MLP
-
其中,MLP的网络设置如下:
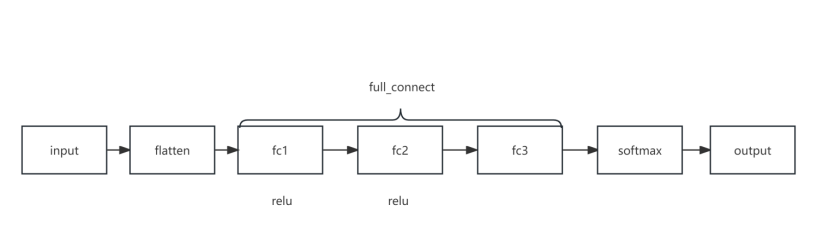
图 2 多层感知机网络结构
定义了三个全连接(线性)层 (fc1、fc2 和 fc3)。
输入张量 x 沿第二个轴展平。将展平后的输入通过第一个线性层 (fc1)。应用 ReLU 激活函数。将结果通过第二个线性层 (fc2)。再次应用 ReLU 激活函数。将结果通过第三个线性层 (fc3)。最后,在轴 1 上应用 softmax 激活函数,获得输出概率。
这个 MLP 架构包括两个带有 ReLU 激活的线性层,最后使用 softmax 激活进行多类别分类。
-
-
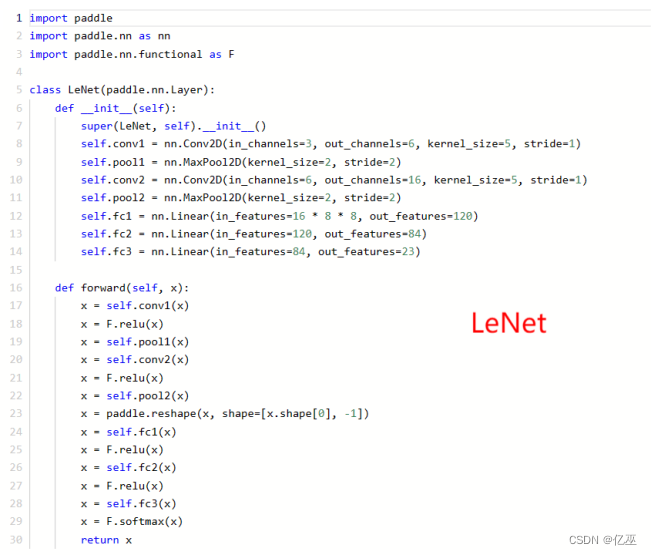
- LeNet
-
LeNet 是由 Yann Lecun 和他的同事于 1998 年提出的卷积神经网络(Convolutional Neural Network,CNN)架构。它是深度学习领域中的开创性网络之一,被广泛应用于手写字符识别等任务。以下是 LeNet 的一般介绍:
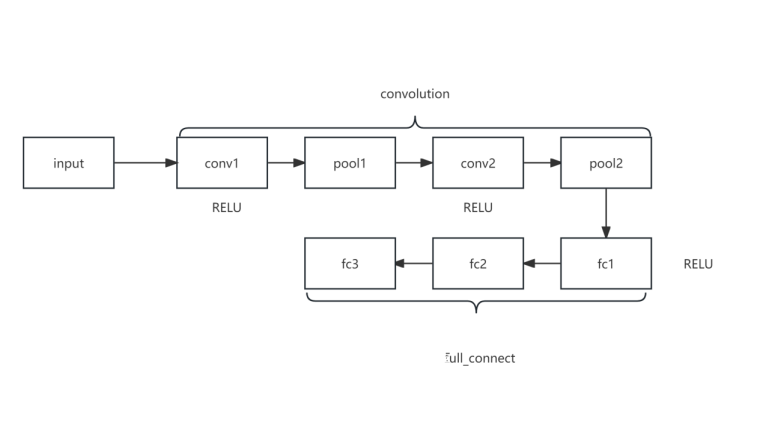
图 3 LeNet 结构
LeNet 结构:
LeNet 主要包含两个部分:卷积层和全连接层。
1.卷积层部分:
- 第一个卷积层 (self.conv1):输入通道数为3,输出通道数为6,卷积核大小为5x5,步长为1。接着应用ReLU激活函数。
- 第一个池化层 (self.pool1):使用最大池化操作,池化核大小为2x2,步长为2。
- 第二个卷积层 (self.conv2):输入通道数为6,输出通道数为16,卷积核大小为5x5,步长为1。接着应用ReLU激活函数。
- 第二个池化层 (self.pool2):使用最大池化操作,池化核大小为2x2,步长为2。
2.全连接层部分:
- 全连接层1 (self.fc1):输入特征数为16乘以8乘以8(经过两次池化后的图像大小),输出特征数为120。接着应用ReLU激活函数。
- 全连接层2 (self.fc2):输入特征数为120,输出特征数为84。接着应用ReLU激活函数。
- 全连接层3 (self.fc3):输入特征数为84,输出特征数为23(对应23个分类类别)。
关键点和创新:
1. 卷积和下采样: LeNet 首次引入了卷积操作和下采样(池化)操作,通过这些操作有效地减小了网络的参数数量。
2. 非线性激活函数:使用ReLU激活函数引入了非线性映射,增强了网络的表示能力。
3. 层次结构:LeNet 显示了通过层次结构构建深度网络的可行性,为后续深度学习模型奠定了基础。
尽管 LeNet 本身在今天的大规模图像分类任务中可能显得较为简单,但它为卷积神经网络的发展奠定了基础,为后来更深层次的网络(如 AlexNet、VGG、ResNet 等)的设计提供了灵感。
-
-
- AlexNet
-
AlexNet是一种深度卷积神经网络(CNN),由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出。它在ImageNet Large Scale Visual Recognition Challenge(ImageNet ILSVRC)比赛中取得了显著的突破,成为深度学习在计算机视觉领域的重要里程碑。
其网络结构如下:
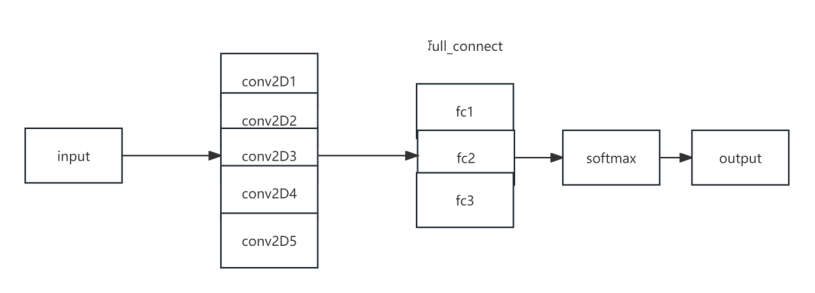
图 4 AlexNet 网络结构
同时,在本实验中输入图像尺寸为 3*47*47 。
以下是AlexNet的主要特点和架构:
- 深度:AlexNet是一个相对较深的神经网络,它有8个可训练的卷积层和3个全连接层。在当时,它是迄今为止最深的神经网络之一。
- 卷积层:AlexNet的前5个层是卷积层,其中,前两个卷积层具有较大的卷积核尺寸(11x11和5x5),并且采用了步长为4和2的较大步幅。这些卷积层能够提取出更高级的特征。
- 激活函数:AlexNet使用了修正线性单元(ReLU)作为激活函数,这在当时是一种比较新颖的选择。ReLU函数能够有效地缓解梯度消失问题,并加速训练过程。
- 池化层:在卷积层之后,AlexNet使用了最大池化层来降低特征图的空间维度,减少模型的参数量,并提高模型的鲁棒性。
- 局部响应归一化(LRN):在卷积层和池化层之间,AlexNet引入了LRN层,用于增强模型的泛化能力。LRN层对局部神经元的活动做归一化,通过抑制相邻神经元的响应来增强更稀疏的特征。
- 全连接层:在卷积层之后,AlexNet有3个全连接层,其中最后一个全连接层是用于分类的输出层。全连接层具有大量的参数,能够捕捉高层次的语义特征。
- Dropout:为了减少过拟合,AlexNet在全连接层中引入了Dropout技术。Dropout通过随机丢弃部分神经元的输出来防止过拟合,从而提高模型的泛化能力。
- 分类任务:AlexNet最初是设计用于ImageNet ILSVRC比赛的分类任务,其中包含1000个不同类别的图像。它的最后一个全连接层输出1000维的向量,表示不同类别的概率分布。
总体而言,AlexNet通过引入深度、大型卷积核、ReLU激活函数、池化层、LRN层和Dropout技术等关键组件,极大地推动了深度学习在计算机视觉领域的发展,并在ImageNet ILSVRC比赛中取得了显著的突破。它的成功为后续的深度神经网络模型奠定了基础,对现代深度学习的发展产生了重要影响。
-
-
- VGGNet
-
VGGNet是一种深度卷积神经网络,由牛津大学的研究团队于2014年提出。它在ImageNet图像分类挑战赛中取得了出色的成绩,并成为卷积神经网络设计中的重要里程碑之一。VGGNet的主要贡献在于通过增加网络的深度来提高模型性能,并将深度和宽度作为关键设计元素。
其网络结构如下:

图 5 VGGNet 网络结构
以下是VGGNet的主要特点和设计原理:
1. 网络结构:VGGNet的整体结构非常简单和规整,它由多个卷积层和池化层交替堆叠而成,最后是几个全连接层。VGGNet的核心是使用了非常小的3x3卷积核,以较小的步幅进行卷积操作。通过堆叠多个卷积层,VGGNet可以达到比较大的感受野,从而能够捕捉到更全局的图像特征。
2. 深度和宽度:VGGNet以其深度和宽度的设计而闻名。它引入了不同层数和参数量的变体,其中最著名的是VGG16和VGG19。VGG16具有16个卷积层(包括13个卷积层和3个全连接层),VGG19更进一步,具有19个卷积层(包括16个卷积层和3个全连接层)。这种深度和宽度的设计使得VGGNet能够更好地捕捉图像中的细节和抽象特征。
3. 小卷积核:VGGNet采用了较小的3x3卷积核,这是一项重要的设计选择。通过使用小卷积核,VGGNet可以增加网络的深度,减少参数数量,并且具有更强的非线性表达能力。多个3x3卷积层的堆叠等效于一个更大感受野的卷积层,但参数量更少。
4. 池化层:VGGNet使用了最大池化层来减小特征图的空间大小。池化层有助于减少特征图的空间维度,提取更为鲁棒的特征,并且在一定程度上具有平移不变性。
尽管VGGNet相对于其他模型而言较为简单,但它在计算机视觉任务中表现出色,并为后续更深层次和复杂的卷积神经网络的发展奠定了基础。本次采用VGG16。
-
-
- ResNet
-
ResNet(Residual Network)是一种深度卷积神经网络架构,由微软研究院的研究团队于2015年提出。它在深度学习领域取得了巨大的成功,并成为许多计算机视觉任务的标准模型之一。ResNet的关键创新是引入了残差连接(residual connections),允许网络在训练过程中更轻松地学习到非常深的层次。
其网络结构如下:
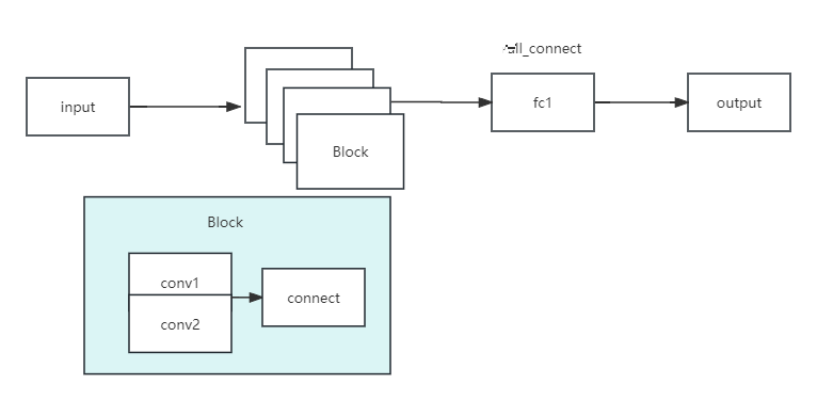
图 6 Resnet-18网络结构
以下是ResNet的主要特点和设计原理:
1. 残差连接:残差连接是ResNet的核心概念。传统的卷积神经网络是通过堆叠多个卷积层构建深层网络,但随着网络层数的增加,出现了梯度消失和梯度爆炸等问题。为了解决这些问题,ResNet引入了跳跃连接(skip connections)或快捷连接(shortcut connections)。残差连接允许网络直接将输入信号绕过一个或多个卷积层,并将其与后续层的输出相加。这样,网络可以更轻松地学习到残差(Residual)信息,从而使得深层网络的训练更加容易。
2. 深度和宽度:ResNet的设计思想是通过增加网络的深度来提高性能。它以层的数量作为网络的关键指标。ResNet的变体包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,其中数字表示网络的层数。较深的ResNet模型通常具有更好的性能,但也需要更多的计算资源和训练时间。
3. 卷积层堆叠:ResNet在每个卷积层堆叠中使用了相同的基本模块,称为残差块(Residual Block)。每个残差块由两个或三个卷积层组成,其中包括一个1x1卷积层用于降维和恢复维度,以及一个3x3卷积层用于特征提取。在ResNet-50及更深的模型中,还引入了一个额外的1x1卷积层用于进一步减少特征图的维度。
4. 全局平均池化和全连接层:在ResNet的最后,通常使用全局平均池化层将特征图转换为向量表示,然后使用全连接层进行分类或回归。全局平均池化层有助于减少特征图的空间维度,并保留最重要的特征。
ResNet以其深度、残差连接和优秀的性能在计算机视觉任务中获得了广泛的应用。它在图像分类、目标检测、语义分割等任务上取得了许多优秀的结果,并为后续深度神经网络的设计和发展提供了重要的启示。因restnet变体数字越大,网络层数越多,本次实验采用ResNet-18进行一个简单尝试,后续使用更深网络层进行探究。
2.1 准备数据
首先,导入必要的包,并读取训练集和测试集数据
 |
简要解释如下:
- `zipfile`: 用于处理ZIP文件,可以进行解压或压缩操作。
- `os`: 提供了与操作系统交互的功能,例如文件和目录的操作。
- `random`: 用于生成随机数或随机选择数据。
- `paddle`: PaddlePaddle深度学习框架的核心包,提供了神经网络模型、优化器、损失函数等构建深度学习模型所需的基本组件。
- `matplotlib.pyplot`: 用于绘制图表,如折线图、柱状图等。
- `MaxPool2D`: PaddlePaddle中的最大池化层,用于图像特征的下采样。
- `Conv2D`: PaddlePaddle中的卷积层,用于图像特征的提取。
- `BatchNorm`: PaddlePaddle中的批归一化层,用于加速神经网络的训练过程和提高模型的稳定性。
- `Linear`: PaddlePaddle中的全连接层,用于将卷积层或池化层的输出与分类器相连。
- `sys`: 提供了与Python解释器和运行时环境交互的功能,例如访问命令行参数。
- `numpy`: 用于高性能科学计算和数据分析的库,提供了强大的多维数组对象和相关工具。
- `PIL.Image`: Python Imaging Library(PIL)的一部分,用于图像的读取、处理和保存。
- `PIL.ImageEnhance`: PIL中用于图像增强的模块,例如对比度、亮度和颜色的调整。
- `json`: 用于处理JSON(JavaScript Object Notation)格式的数据,可以进行解析和生成JSON数据。
这些包在后续代码中的作用可能包括数据预处理、模型构建、模型训练、图像处理和结果可视化等。具体的作用会根据代码实现的需求而有所不同。
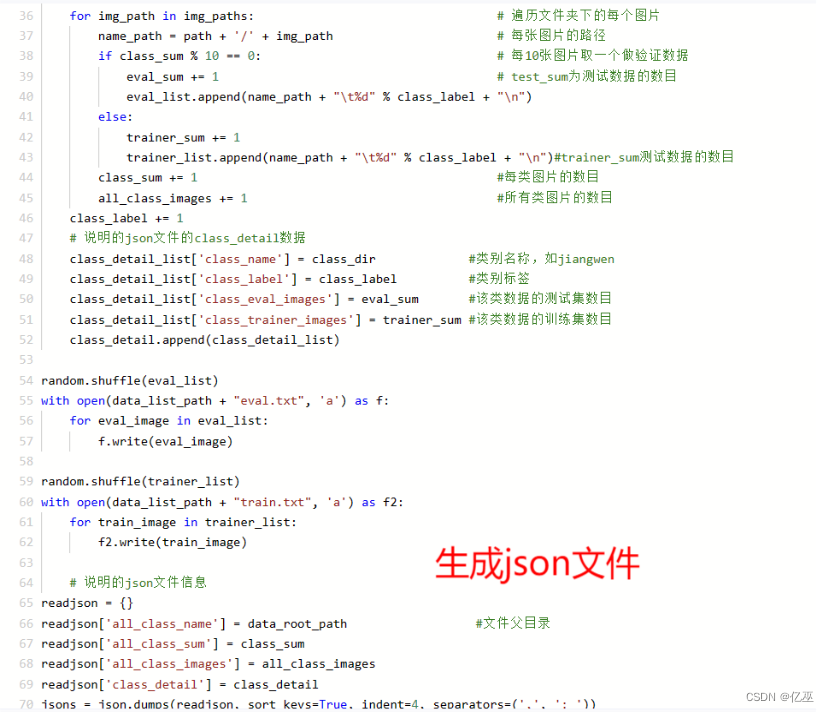
2.1.1生成数据列表
解压数据集
 |
 |
 |

2.1.2定义数据提供器 train_r、test_r
 |
利用函数生成数据集
 |
2.2 搭建网络
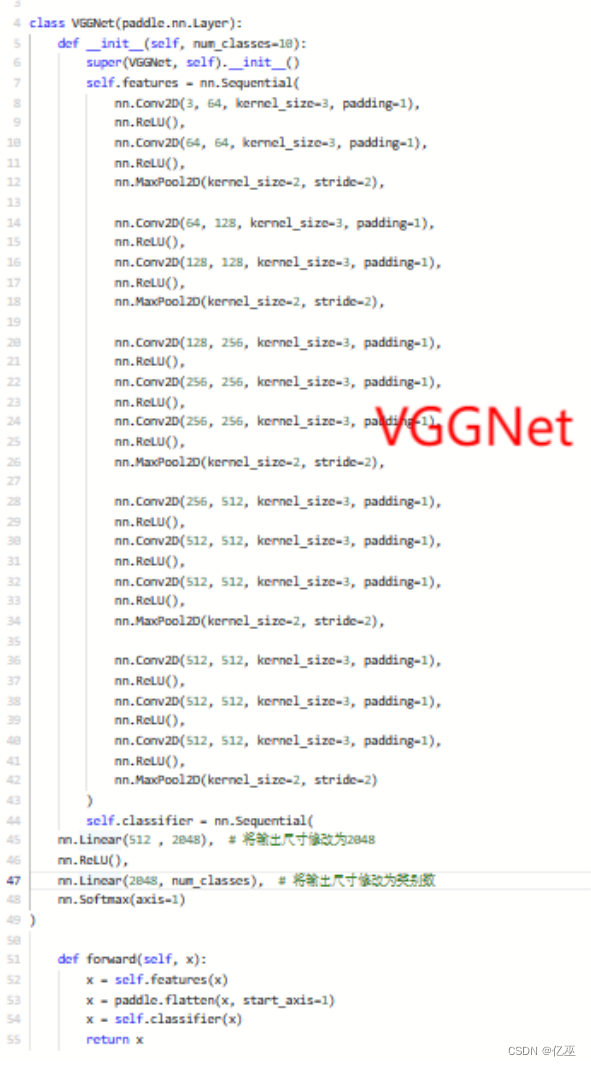
本次实验基于PaddlePaddle搭建了多层感知机、LeNet 和 AlexNet,VGGnet,ResNet,其设计和改良如 1.3 所介绍,其 详细代码如下
 |
 |
 |
 |
 |
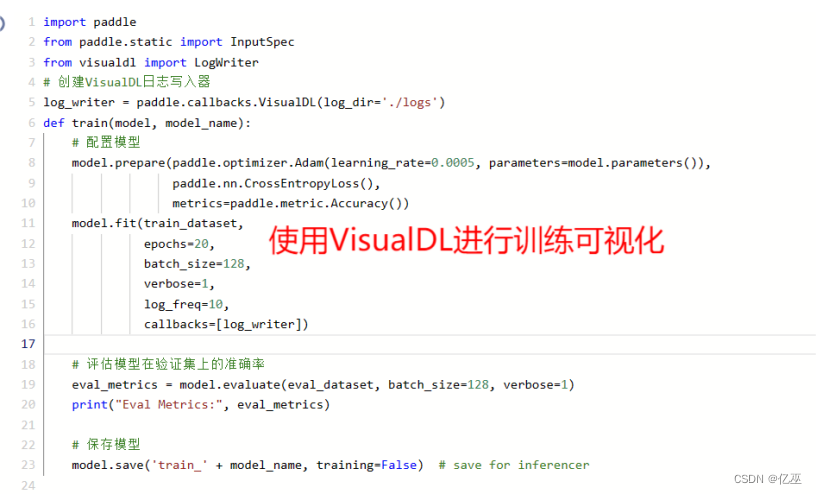
2.3 训练配置
接下来,定义训练函数
 |
 |
2.4 超参调节
为进一步得到更好的模型结果,因此利用均匀步长搜索法在验证集上进行超参数的调节,其中参数调节范围如下所示:
超参数 范围 ,第三个为步长
learning_rate (0.0005 0.001 0.0001)
代码如下
 |
寻找最优学习率为 0.0005,准确率为0.9937
三、 实验结果
3.1 模型准确率比较
接下来,我比较了各模型在 echos=20 时的模型时的表现
| Model | train_loss | test_acc |
| MYCNN | 2.2725 | 0.9273 |
| MLP | 2.3773 | 0.8215 |
| LeNet | 2.2830 | 0.8993 |
| AlexNet | 2.7169 | 0.4418 |
| VGGnet | 2.7169 | 0.4418 |
| ResNet | 0.1823 | 0.9744 |
可视化分析
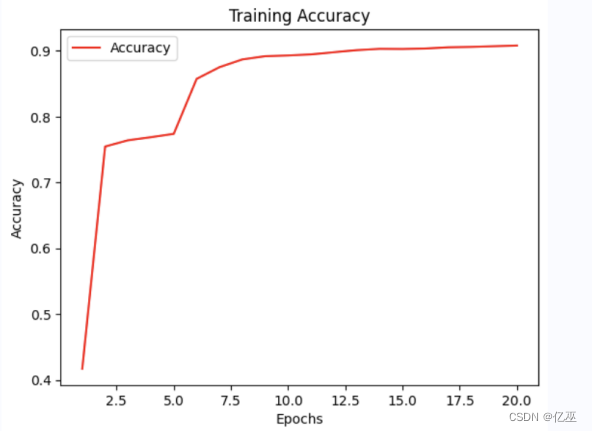
图 1 MYCNN结果
 |
图 2 LeNet结果
根据表格数据,我们可以对各个模型在 echos=20 时的表现进行分析:
1. MYCNN模型:
- 训练损失(train_loss)为2.2725,说明模型在训练数据上的拟合效果较好。
- 测试准确率(test_acc)为0.9273,说明模型在测试数据上的分类精度较高,能够正确预测大部分样本的类别。
2. MLP模型:
- 训练损失为2.3773,略高于其他模型,可能表示模型在训练数据上的拟合程度稍低。
- 测试准确率为0.8215,较MYCNN模型的测试准确率较低,可能表示MLP模型在应对复杂数据的分类任务上相对较弱。
3. LeNet模型:
- 训练损失为2.2830,接近于MYCNN模型的训练损失,说明模型在训练数据上的表现较好。
- 测试准确率为0.8993,虽然低于MYCNN模型的测试准确率,但仍表现较好,能够较准确地预测测试数据的类别。
4. AlexNet模型:
- 训练损失为2.7169,较高,可能意味着模型在训练数据上的拟合效果较差。
- 测试准确率为0.4418,远低于其他模型的测试准确率,说明AlexNet模型在该任务上表现不佳。
5. VGGnet模型:
- 训练损失为2.7169,与AlexNet模型的训练损失相同,说明模型的训练效果类似。
- 测试准确率为0.4418,与AlexNet模型的测试准确率相同,说明VGGnet模型在该任务上的表现与AlexNet模型相似。
6. ResNet模型:
- 训练损失为0.1823,远低于其他模型的训练损失,表明ResNet模型在训练数据上的拟合效果非常好。
- 测试准确率为0.9744,是所有模型中最高的,说明ResNet模型在该任务上具有很好的分类能力,能够准确地预测测试数据的类别。
3.2 模型预测

 |
四、 实验感想
图1是Visual可视化,图2是通过代码实现的可视化,可以发现paddlepaddle这个可视化分析很好用,并且在平台上可以通过鼠标移动看到每一个值,就很方便。
#导入必要的包import zipfileimport osimport randomimport paddleimport matplotlib.pyplot as pltfrom paddle.nn import MaxPool2D,Conv2D,BatchNormfrom paddle.nn import Linearimport sysimport numpy as npfrom PIL import Imagefrom PIL import ImageEnhanceimport paddlefrom multiprocessing import cpu_countimport matplotlib.pyplot as pltimport json#解压原始数据集,将fish_image.zip解压至data目录下src_path="/home/aistudio/data/data14492/fish_image23.zip"target_path="/home/aistudio/data/fish_image"if(not os.path.isdir(target_path)):z = zipfile.ZipFile(src_path, 'r')z.extractall(path=target_path)z.close()#存放所有类别的信息class_detail = []data_root_path="/home/aistudio/data/fish_image/fish_image"#获取所有类别保存的文件夹名称class_dirs = os.listdir(data_root_path)data_list_path="/home/aistudio/data/"TRAIN_LIST_PATH=data_list_path + "train.txt"EVAL_LIST_PATH=data_list_path + "eval.txt"#每次执行代码,首先清空train.txt和eval.txtwith open(TRAIN_LIST_PATH, 'w') as f:passwith open(EVAL_LIST_PATH, 'w') as f:pass#总的图像数量all_class_images = 0#存放类别标签class_label=0#存储要写进test.txt和train.txt中的内容trainer_list=[]eval_list=[]#读取每个类别,['fish_01', 'fish_02', 'fish_03']for class_dir in class_dirs:#每个类别的信息class_detail_list = {}eval_sum = 0trainer_sum = 0#统计每个类别有多少张图片class_sum = 0#获取类别路径path = data_root_path + "/" + class_dir# 获取所有图片img_paths = os.listdir(path)for img_path in img_paths: # 遍历文件夹下的每个图片name_path = path + '/' + img_path # 每张图片的路径if class_sum % 10 == 0: # 每10张图片取一个做验证数据eval_sum += 1 # test_sum为测试数据的数目eval_list.append(name_path + "\t%d" % class_label + "\n")else:trainer_sum += 1trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目class_sum += 1 #每类图片的数目all_class_images += 1 #所有类图片的数目class_label += 1# 说明的json文件的class_detail数据class_detail_list['class_name'] = class_dir #类别名称,如jiangwenclass_detail_list['class_label'] = class_label #类别标签class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目class_detail.append(class_detail_list)random.shuffle(eval_list)with open(data_list_path + "eval.txt", 'a') as f:for eval_image in eval_list:f.write(eval_image)random.shuffle(trainer_list)with open(data_list_path + "train.txt", 'a') as f2:for train_image in trainer_list:f2.write(train_image)# 说明的json文件信息readjson = {}readjson['all_class_name'] = data_root_path #文件父目录readjson['all_class_sum'] = class_sumreadjson['all_class_images'] = all_class_imagesreadjson['class_detail'] = class_detailjsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))with open(data_list_path + "readme.json",'w') as f:f.write(jsons)print ('生成数据列表完成!')import paddleimport paddle.vision.transforms as Timport numpy as npfrom PIL import Imageclass FishDataset(paddle.io.Dataset):"""23种鱼数据集类的定义"""def __init__(self, mode='train'):"""初始化函数"""assert mode in ['train', 'eval'], 'mode is one of train, eval.'self.data = []with open('data/{}.txt'.format(mode)) as f:for line in f.readlines():info = line.strip().split('\t')if len(info) > 0:self.data.append([info[0].strip(), info[1].strip()])if mode == 'train':self.transforms = T.Compose([T.Resize((47,47)), # 随机裁剪大小T.RandomHorizontalFlip(0.5), # 随机水平翻转T.ToTensor(), # 数据的格式转换和标准化、 HWC => CHWT.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化])else:self.transforms = T.Compose([T.Resize((47,47)), # 图像大小修改T.ToTensor(), # 数据的格式转换和标准化 HWC => CHWT.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化])def __getitem__(self, index):"""根据索引获取单个样本"""image_file, label = self.data[index]image = Image.open(image_file)if image.mode != 'RGB':image = image.convert('RGB')image = self.transforms(image)return image, np.array(label, dtype='int64')def __len__(self):"""获取样本总数"""return len(self.data)#定义CNN网络import paddleimport paddle.nn.functional as Fclass MyCNN(paddle.nn.Layer):def __init__(self):super(MyCNN,self).__init__()self.conv1 = Conv2D(in_channels=3, out_channels=20, kernel_size=5,stride=1) self.pool1 = MaxPool2D(kernel_size=2, stride=2)self.conv2 = Conv2D(in_channels=20, out_channels=50, kernel_size=5,stride=1)self.pool2 = MaxPool2D(kernel_size=2, stride=2)self.conv3 = Conv2D(in_channels=50, out_channels=50, kernel_size=5,stride=1)self.pool3 = MaxPool2D(kernel_size=2, stride=2)self.linear1 = Linear(in_features=200, out_features=23)def forward(self, input):x = self.conv1(input)x = F.relu(x)x = self.pool1(x)x = self.conv2(x)x = F.relu(x)x = self.pool2(x)x = self.conv3(x)x = F.relu(x)x = self.pool3(x)x = paddle.flatten(x, start_axis=1,stop_axis=-1) x = self.linear1(x)x=F.softmax(x)return ximport paddleimport paddle.nn as nnclass MLP(paddle.nn.Layer):def __init__(self, input_size, hidden_size, num_classes):super(MLP, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.fc2 = nn.Linear(hidden_size, hidden_size)self.fc3 = nn.Linear(hidden_size, num_classes)def forward(self, x):x = paddle.flatten(x, start_axis=1)x = self.fc1(x)x = nn.functional.relu(x)x = self.fc2(x)x = nn.functional.relu(x)x = self.fc3(x)x = nn.functional.softmax(x, axis=1)return ximport paddleimport paddle.nn as nnimport paddle.nn.functional as Fclass LeNet(paddle.nn.Layer):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2D(in_channels=3, out_channels=6, kernel_size=5, stride=1)self.pool1 = nn.MaxPool2D(kernel_size=2, stride=2)self.conv2 = nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)self.pool2 = nn.MaxPool2D(kernel_size=2, stride=2)self.fc1 = nn.Linear(in_features=16 * 8 * 8, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=23)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.pool1(x)x = self.conv2(x)x = F.relu(x)x = self.pool2(x)x = paddle.reshape(x, shape=[x.shape[0], -1])x = self.fc1(x)x = F.relu(x)x = self.fc2(x)x = F.relu(x)x = self.fc3(x)x = F.softmax(x)return ximport paddleimport paddle.nn as nnclass AlexNet(paddle.nn.Layer):def __init__(self, num_classes=23):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2D(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(),nn.MaxPool2D(kernel_size=3, stride=2),nn.Conv2D(64, 192, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2D(kernel_size=3, stride=2),nn.Conv2D(192, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(384, 256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(256, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2D(kernel_size=3, stride=2))self.classifier = nn.Sequential(nn.Linear(256 * 1 * 1, 4096),nn.ReLU(),nn.Linear(4096, 4096),nn.ReLU(),nn.Linear(4096, num_classes),nn.Softmax(axis=1))def forward(self, x):x = self.features(x)x = paddle.flatten(x, start_axis=1)x = self.classifier(x)return ximport paddleimport paddle.nn as nnclass VGGNet(paddle.nn.Layer):def __init__(self, num_classes=10):super(VGGNet, self).__init__()self.features = nn.Sequential(nn.Conv2D(3, 64, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(64, 64, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2D(kernel_size=2, stride=2),nn.Conv2D(64, 128, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(128, 128, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2D(kernel_size=2, stride=2),nn.Conv2D(128, 256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(256, 256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(256, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2D(kernel_size=2, stride=2),nn.Conv2D(256, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2D(kernel_size=2, stride=2),nn.Conv2D(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2D(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2D(kernel_size=2, stride=2))self.classifier = nn.Sequential(nn.Linear(512 , 2048), # 将输出尺寸修改为2048nn.ReLU(),nn.Linear(2048, num_classes), # 将输出尺寸修改为类别数nn.Softmax(axis=1))def forward(self, x):x = self.features(x)x = paddle.flatten(x, start_axis=1)x = self.classifier(x)return ximport paddleimport paddle.nn as nnclass BasicBlock(paddle.nn.Layer):expansion = 1def __init__(self, in_channels, out_channels, stride=1, downsample=None):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2D(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias_attr=False)self.bn1 = nn.BatchNorm2D(out_channels)self.relu = nn.ReLU()self.conv2 = nn.Conv2D(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias_attr=False)self.bn2 = nn.BatchNorm2D(out_channels)self.downsample = downsampledef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out = paddle.add(out, identity)out = self.relu(out)return outclass ResNet(paddle.nn.Layer):def __init__(self, block, layers, num_classes=1000):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2D(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias_attr=False)self.bn1 = nn.BatchNorm2D(64)self.relu = nn.ReLU()self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)self.layer1 = self.make_layer(block, 64, layers[0])self.layer2 = self.make_layer(block, 128, layers[1], stride=2)self.layer3 = self.make_layer(block, 256, layers[2], stride=2)self.layer4 = self.make_layer(block, 512, layers[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2D((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def make_layer(self, block, out_channels, blocks, stride=1):downsample = Noneif stride != 1 or self.in_channels != out_channels * block.expansion:downsample = nn.Sequential(nn.Conv2D(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias_attr=False),nn.BatchNorm2D(out_channels * block.expansion),)layers = []layers.append(block(self.in_channels, out_channels, stride, downsample))self.in_channels = out_channels * block.expansionfor _ in range(1, blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = paddle.flatten(x, start_axis=1)x = self.fc(x)return xdef resnet18(num_classes=1000):return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)def resnet34(num_classes=1000):return ResNet(BasicBlock, [3, 4, 6, 3], num_classes)import paddlefrom paddle.static import InputSpecfrom visualdl import LogWriter# 创建VisualDL日志写入器log_writer = paddle.callbacks.VisualDL(log_dir='./logs')def train(model, model_name):# 配置模型model.prepare(paddle.optimizer.Adam(learning_rate=0.0005, parameters=model.parameters()),paddle.nn.CrossEntropyLoss(),metrics=paddle.metric.Accuracy())model.fit(train_dataset,epochs=20,batch_size=128,verbose=1,log_freq=10,callbacks=[log_writer])# 评估模型在验证集上的准确率eval_metrics = model.evaluate(eval_dataset, batch_size=128, verbose=1)print("Eval Metrics:", eval_metrics)# 保存模型model.save('train_' + model_name, training=False) # save for inferencermodel = MyCNN()print(model)model = paddle.Model(model)model_name='MyCNN'train(model, model_name)# 定义模型的输入维度、隐藏层维度和类别数input_size = 47*47*3 # 数据集的输入图像大小是47x47x3hidden_size = 256num_classes = 23 # 数据集有23个类别# 创建MLP模型实例model = MLP(input_size, hidden_size, num_classes)print(model)model = paddle.Model(model)model_name='MLP'train(model, model_name)model = LeNet()print(model)model = paddle.Model(model)model_name='LeNet'train(model, model_name)model = AlexNet(num_classes=23)print(model)model = paddle.Model(model)model_name='AlexNet'train(model, model_name)model = VGGNet(num_classes=23)print(model)model = paddle.Model(model)model_name='VGGNet'train(model, model_name)model = resnet18(num_classes=23)print(model)model = paddle.Model(model)model_name='resnet18'train(model, model_name)import matplotlib.pyplot as plt# 定义每个epoch的损失值和准确率loss_values = [2.3818, 2.3505, 2.9212, 2.3581, 2.5047, 2.2194, 2.3727, 2.2091, 2.2604, 2.3504, 2.2075, 2.3504, 2.2084, 2.3504, 2.3504, 2.2075, 2.2075, 2.3505, 2.3490, 2.2089]acc_values = [0.4170, 0.7546, 0.7641, 0.7688, 0.7739, 0.8574, 0.8752, 0.8870, 0.8919, 0.8930, 0.8946, 0.8979, 0.9011, 0.9030, 0.9028, 0.9035, 0.9054, 0.9060, 0.9070, 0.9080]# 绘制损失值曲线plt.plot(range(1, len(loss_values) + 1), loss_values, 'b', label='Loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Training Loss')plt.legend()plt.show()# 绘制准确率曲线plt.plot(range(1, len(acc_values) + 1), acc_values, 'r', label='Accuracy')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.title('Training Accuracy')plt.legend()plt.show()import paddlefrom paddle.static import InputSpecfrom visualdl import LogWriter# 创建VisualDL日志写入器log_writer = paddle.callbacks.VisualDL(log_dir='./logs')class CustomCallback(paddle.callbacks.Callback):def set_model(self, model):self.model = modeldef on_epoch_end(self, epoch, logs=None):# 自定义回调逻辑passdef train(model, model_name, learning_rate):# 配置模型decay_steps = 2000 # 学习率衰减步数end_lr = 0.0005 # 最终学习率lr_scheduler = paddle.optimizer.lr.PolynomialDecay(learning_rate, decay_steps, end_lr)model.prepare(paddle.optimizer.Adam(lr_scheduler, parameters=model.parameters()),paddle.nn.CrossEntropyLoss(),metrics=paddle.metric.Accuracy())# 设置自定义回调函数custom_callback = CustomCallback()model.fit(train_dataset,epochs=20,batch_size=128,verbose=1,log_freq=10,callbacks=[log_writer, custom_callback])# 评估模型在验证集上的准确率eval_metrics = model.evaluate(eval_dataset, batch_size=128, verbose=1)print("Eval Metrics:", eval_metrics)# 保存模型model.save('train_' + model_name, training=False) # save for inferencer# 设置学习率范围learning_rate_range = [0.0005, 0.001]# 遍历学习率范围进行训练for learning_rate in learning_rate_range:model = resnet18(num_classes=23)model = paddle.Model(model)model_name='resnet18'train(model, model_name, learning_rate)# 进行预测操作predict_result = model.predict(eval_dataset)import pandas as pddata=pd.read_csv('./data/eval.txt',header=None,sep='\t')# 定义画图方法from PIL import Imagedef show_img(img, predict):plt.figure()plt.title(predict)plt.imshow(img, cmap=plt.cm.binary)plt.show()# 抽样展示for i in range(10):img_path=data[0][i]real_class=data[1][i]predict_class= np.argmax(predict_result[0][i])img=Image.open(img_path)title=str(i) +' '+ 'real_class: ' +str(real_class)+' '+ 'predict_class: ' + str(predict_class)show_img(img, title)这篇关于【人工智能】海洋生物识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







