本文主要是介绍算法之美:缓存数据淘汰算法分析及分解实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在设计一个系统的时候,由于数据库的读取速度远小于内存的读取速度,那么为加快读取速度,需先将一部分数据加入到内存中(该动作称为缓存),但是内存容量又是有限的,当缓存的数据大于内存容量时,就需要删除一部分数据,以加入新的数据。这时候需要设计一种淘汰机制,计算出哪些数据删除,哪些数据保留,常见的淘汰算法有FIFO、LRU、LFU等淘汰算法,接下来我们将一一讲解及实现。
FIFO淘汰算法

First In First Out,先进先出,淘汰最早被缓存的对象,是一种常用的缓存淘汰算法,它的原理是按照先进先出的原则,当缓存满了之后,先将最早进入缓存的数据淘汰掉,以腾出空间给新的数据,其优点在于实现简单,不需要记录或统计数据的使用次数,只需要记录每个数据进入缓存的时间和每个数据在缓存中的位置即可。
其缺点也是明显的,它不能有效地淘汰最近最少使用的数据,最近最多使用的数据也可能被淘汰掉,这样就会导致缓存的效率不够高。
public class FIFOCache<K, V> {// 定义缓存的最大容量private int maxSize;// 定义当前缓存的容量private int curSize;// 用于存放缓存的keyprivate LinkedList<K> cacheKey;// 用于存放缓存的valueprivate HashMap<K, V> cacheValue;// 读写锁,保证线程安全private Lock lock = new ReentrantLock();// 构造函数public FIFOCache(int maxSize) {this.maxSize = maxSize;this.curSize = 0;this.cacheKey = new LinkedList<K>();this.cacheValue = new HashMap<K, V>();}// 向缓存插入key-valuepublic void put(K key, V value) {// 加锁保证线程安全lock.lock();try {// 如果缓存已满,则删除最老的keyif (curSize == maxSize) {K oldKey = cacheKey.removeFirst();cacheValue.remove(oldKey);curSize--;}// 插入key-valuecacheKey.addLast(key);cacheValue.put(key, value);curSize++;} finally {// 释放锁lock.unlock();}}// 查询指定key的valuepublic V get(K key) {return cacheValue.get(key);}public void printKeys() {System.out.println(this.cacheKey.toString());}public static void main(String[] args) {FIFOCache cache = new FIFOCache<String, String>(5);cache.put("A", "数据结构篇:深度剖析LSM及与B+树优劣势分析");cache.put("B", "数据结构篇:深度剖析跳跃表及与B+树优劣分析");cache.put("C", "算法之美:堆排序原理剖析及应用案例分解实现");cache.printKeys();cache.put("D", "算法之美:二叉堆原理剖析及堆应用案例讲解及实现");cache.printKeys();Object cacheObj1 = cache.get("A");System.out.println("cacheObj1=" + cacheObj1);Object cacheObj2 = cache.get("C");System.out.println("cacheObj2=" + cacheObj2);}}LRU最久未使用算法
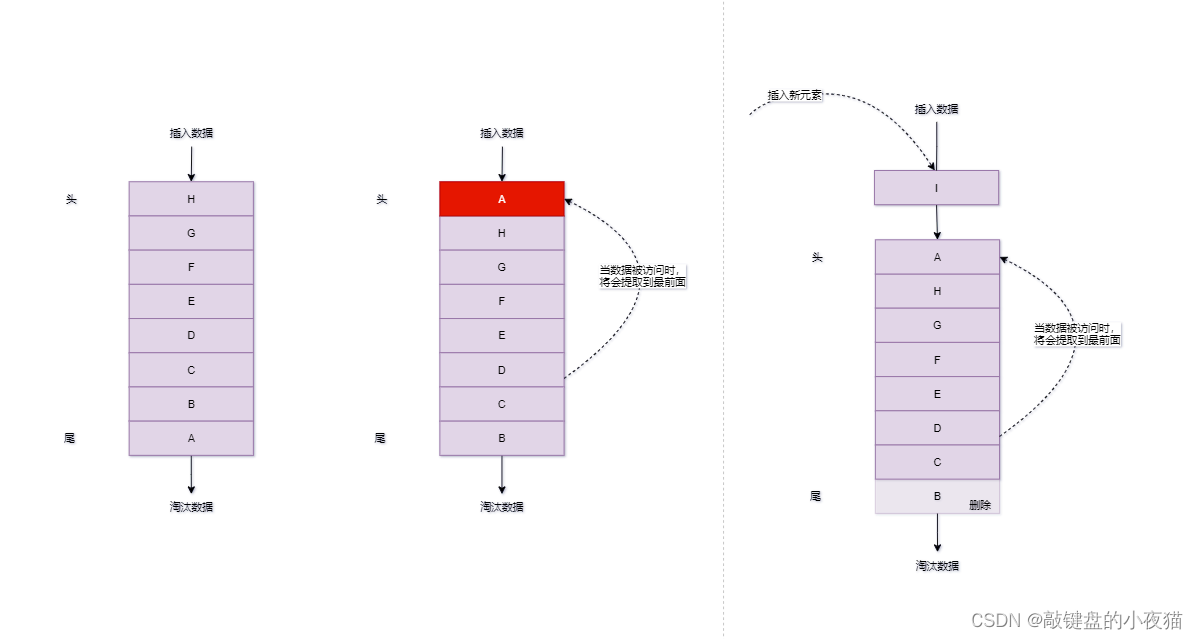
Least Recently Used 淘汰算法以时间作为参考,淘汰最长时间未被使用的数据,设计者认为如果数据最近被访问过,那么将来被访问的几率也更高;当内存满后会优先淘汰最长时间没有被使用的元素(都没人要你了,不淘汰你淘汰谁)
其基本原理就是在缓存满时,将最近最久未使用的数据淘汰出缓存,以便给新的数据留出空间。实现方式可以用:数组、链表等方式,新插入的数据放在头部,最近访问过的也移到头部,空间满时将尾部元素删除。
public class LRUCache {//用于存储key-value数据private HashMap<String, String> map;//用于存储key的顺序private ArrayList<String> list;//数组的容量private int capacity;public LRUCache(int capacity) {this.capacity = capacity;map = new HashMap<>();list = new ArrayList<>();}/*** 查询key对应的value* @param key 键* @return value 值*/public String get(String key) {//如果key存在,则将key移动到最前端if (map.containsKey(key)) {list.remove(key);list.add(0, key);return map.get(key);}return null;}/*** 向缓存中插入key-value* @param key 键* @param value 值*/public void put(String key, String value) {//如果key存在,则将key移动到最前端if (map.containsKey(key)) {list.remove(key);list.add(0, key);map.put(key, value);} else {//如果key不存在,则添加key-valueif (list.size() >= capacity) {//如果容量已满,则删除最后一个keyString lastKey = list.get(list.size() - 1);list.remove(lastKey);map.remove(lastKey);}list.add(0, key);map.put(key, value);}}public void showList(){System.out.println(list.toString());}public static void main(String[] args) {LRUCache cache = new LRUCache(5);cache.put("A", "数据结构篇:深度剖析LSM及与B+树优劣势分析");cache.put("B", "数据结构篇:深度剖析跳跃表及与B+树优劣分析");cache.put("C", "算法之美:堆排序原理剖析及应用案例分解实现");cache.put("D", "海量数据项目大课是营销短链平台项目");cache.put("E", "算法之美:二叉堆原理剖析及堆应用案例讲解及实现");cache.showList();Object cacheObj2 = cache.get("C");System.out.println("cacheObj2=" + cacheObj2);//C被访问,被放置头部cache.showList();cache.put("F", "算法之美:B+树原理、应用及Mysql索引底层原理剖析");//新增了F,超过大小,A由于在尾部,被删除,F被放置头部cache.showList();//G节点不存在,所以不影响顺序Object cacheObj1 = cache.get("G");System.out.println("cacheObj1=" + cacheObj1);cache.showList();}
}LFU最近最少使用算法
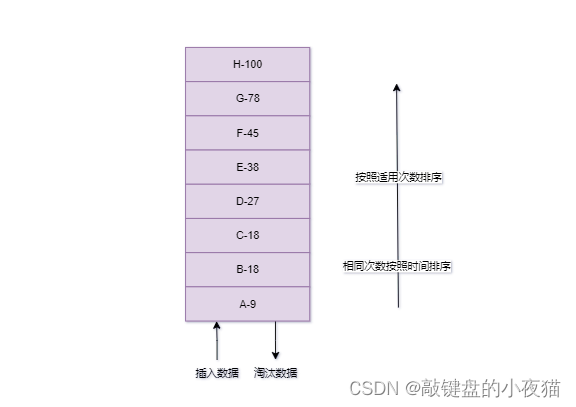
Least Frequently Used 最近最少使用,增加次数作为参考,淘汰一定时期内被访问次数最少的数据。设计者认为如果数据过去被访问多次,那么将来被访问的频率也更高,比LRU多了一个频次统计,需要时间和次数两个维度进行判断是否淘汰。新加入数据插入到队列尾部,需要将引用计数初始值为 1,当队列中的数据被访问后,对应的元素引用计数 +1,队列按【次数】重新排序,如果相同次数则按照时间排序,当需要淘汰数据时,将排序的队列末尾的数据删除,即访问次数最少。
public class LFUCache {//定义缓存容量private int capacity ;//存储key valueprivate Map<String,String> cache ;//存储key的使用频次private Map<String, CacheObj> count;public LFUCache(int capacity){this.capacity = capacity;cache = new HashMap<>();count = new HashMap<>();}//存储public void put(String key, String value) {}//读取public String get(String key) {}//删除元素private void removeElement() {}//更新相关统计频次和时间private void addCount(String key) {}public void showInfo(){System.out.println(cache.toString());System.out.println(count.toString());}class CacheObj implements Comparable<CacheObj>{private String key;private int count;private long lastTime;public String getKey() {return key;}public void setKey(String key) {this.key = key;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}public long getLastTime() {return lastTime;}public void setLastTime(long lastTime) {this.lastTime = lastTime;}public CacheObj(String key, int count, long lastTime) {this.key = key;this.count = count;this.lastTime = lastTime;}//用于比较大小,如果使用次数一样,则比较时间大小@Overridepublic int compareTo(CacheObj o) {int value = Integer.compare(this.count, o.count);return value == 0 ? Long.compare(this.lastTime, o.lastTime) : value;}@Overridepublic String toString() {return "CacheObj{" +"key=" + key +", count=" + count +", lastTime=" + lastTime +'}';}}
}public class LFUCache {//定义缓存容量private int capacity ;//存储key valueprivate Map<String,String> cache ;//存储key的使用频次private Map<String, CacheObj> count;public LFUCache(int capacity){this.capacity = capacity;cache = new HashMap<>();count = new HashMap<>();}//存储public void put(String key, String value) {String cacheValue = cache.get(key);if (cacheValue == null) {//新元素插入,需要判断是否超过缓存容量大小if (cache.size() == capacity) {removeElement();}count.put(key, new CacheObj(key, 1, System.currentTimeMillis()));} else {addCount(key);}cache.put(key, value);}//读取public String get(String key) {String value = cache.get(key);if (value != null) {addCount(key);return value;}return null;}//删除元素private void removeElement() {CacheObj cacheObj = Collections.min(count.values());cache.remove(cacheObj.getKey());count.remove(cacheObj.getKey());}//更新相关统计频次和时间private void addCount(String key) {CacheObj cacheObj = count.get(key);cacheObj.setCount(cacheObj.getCount()+1);cacheObj.setLastTime(System.currentTimeMillis());}public void showInfo(){System.out.println(cache.toString());System.out.println(count.toString());}class CacheObj implements Comparable<CacheObj>{private String key;private int count;private long lastTime;public CacheObj(String key, int count, long lastTime) {this.key = key;this.count = count;this.lastTime = lastTime;}//用于比较大小,如果使用次数一样,则比较时间大小@Overridepublic int compareTo(CacheObj o) {int value = Integer.compare(this.count, o.count);return value == 0 ? Long.compare(this.lastTime, o.lastTime) : value;}@Overridepublic String toString() {return "CacheObj{" +"key=" + key +", count=" + count +", lastTime=" + lastTime +'}';}}
}public static void main(String[] args) {LFUCache cache = new LFUCache(2);cache.put("A", "数据结构篇:深度剖析LSM及与B+树优劣势分析");cache.put("A", "数据结构篇:深度剖析跳跃表及与B+树优劣分析");cache.showInfo();System.out.println("---------");String cacheValue = cache.get("A");System.out.println(cacheValue);cache.showInfo();System.out.println("---------");cache.put("B", "算法之美:堆排序原理剖析及应用案例分解实现");cache.put("B", "算法之美:二叉堆原理剖析及堆应用案例讲解及实现");cache.showInfo();System.out.println("---------");//插入新元素,由于A的count是3,B的count是2,所以淘汰了Bcache.put("C","算法之美:B+树原理、应用及Mysql索引底层原理剖析");cache.showInfo();
}这篇关于算法之美:缓存数据淘汰算法分析及分解实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





