本文主要是介绍论文笔记:Large Language Models as Analogical Reasoners,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
iclr 2024 reviewer打分5558
1 intro
- 基于CoT prompt的大模型能够更好地解决复杂推理问题
- 然而传统CoT需要提供相关的例子作为指导,这就增加了人工标注的成本
- ——>Zero-shot CoT避免了人工标注来引导推理
- 但是对于一些复杂的任务难以完成推理,例如code generation
- ——>论文提出一种“归纳学习”的提示方法
- 首先设计prompt让大模型生成出与当前问题比较相关的问题和答案,以辅助问答提出的问题

2 preliminary
-
给定一个问题x
-
首先通过prompt将问题映射到文本输入ϕ ( x )
-
zero-shot ϕ ( x ) 就是x zero-shot CoT ϕ ( x ) 是[x] think step by step few-shot CoT ϕ ( x ) 是[x]和一些带label的例子
,即
[x1][r1][a1].....[xK][rK][aK][x]
-
-
任务目标是调用LLM解决这个问题【生成目标答案y】
-
生成的目标答案可以包含reasoning path r【推理过程】和答案a
-
-
3 方法
3.1 Self-Generated Exemplars
- 让大模型从在训练阶段掌握的problem-solving knowledge中生成出相关的问题和解决方法

3.1.1 prompt举例

3.1.2 大模型给的答案

大模型先生成出3个相关的且互不相同的problem,并给出相应的解决方案,然后再对目标问题进行解决。
3.1.3 self-generated instruction的三个核心部分
- 明确地让大模型生成相关且不同的样例。
- 因为大模型会偏向于重复地生成一些经典的问题,导致误导
- single-pass VS independent exemplar generation
- 所谓single-pass,就是直接prompt,让模型生成3个样例
- independent exemplar generation:让模型生成若干样例,然后采样3个样例,之后再重新设计prompt让大模型进行生成
- ——>通过实验,发现single-pass效果最好
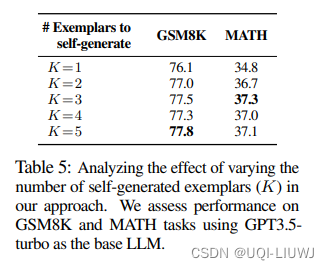
- 生成的样例数量:3~5最佳
3.2 Self-generated Knowledge + Exemplars
- 对于像代码生成等复杂的任务,3.1这样的案例生成方法不一定能过让模型很好地解决此类问题
- ——>论文提出一种high-level generation方法。通过设计如下指令来实现:

- 【让模型先思考选择什么algorithm,以及algorithm对应的tutorial】
有点类似于:论文笔记:Take a Step Back:Evoking Reasoning via Abstraction in Large Language Models-CSDN博客的后退一步?
3.2.1 prompt 案例
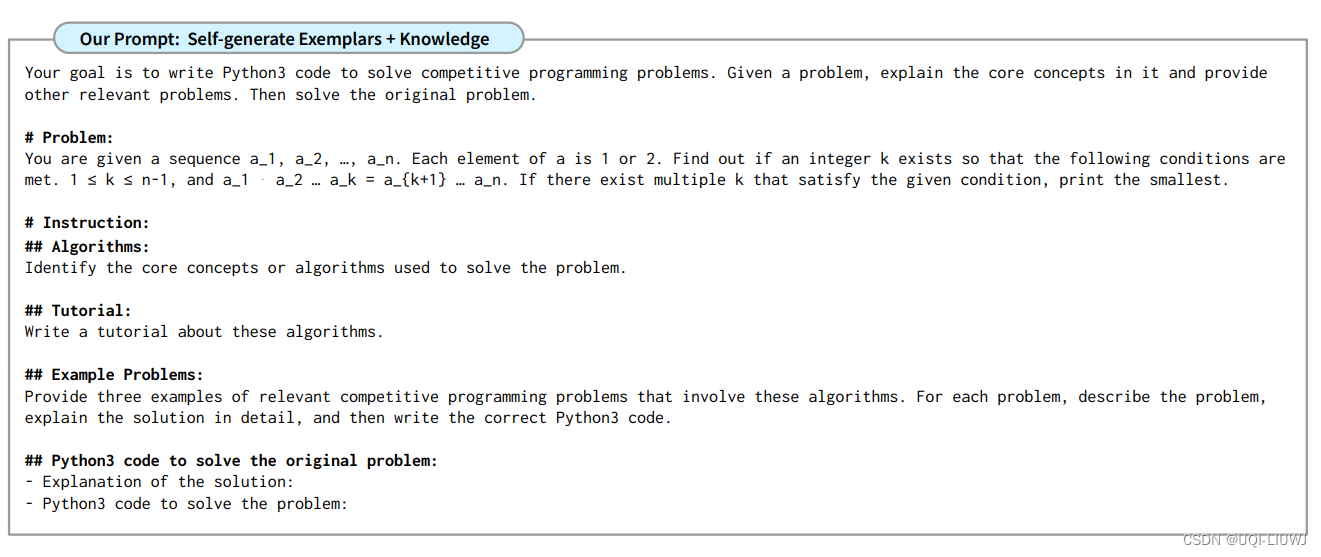
3.2.2 大模型给的答案
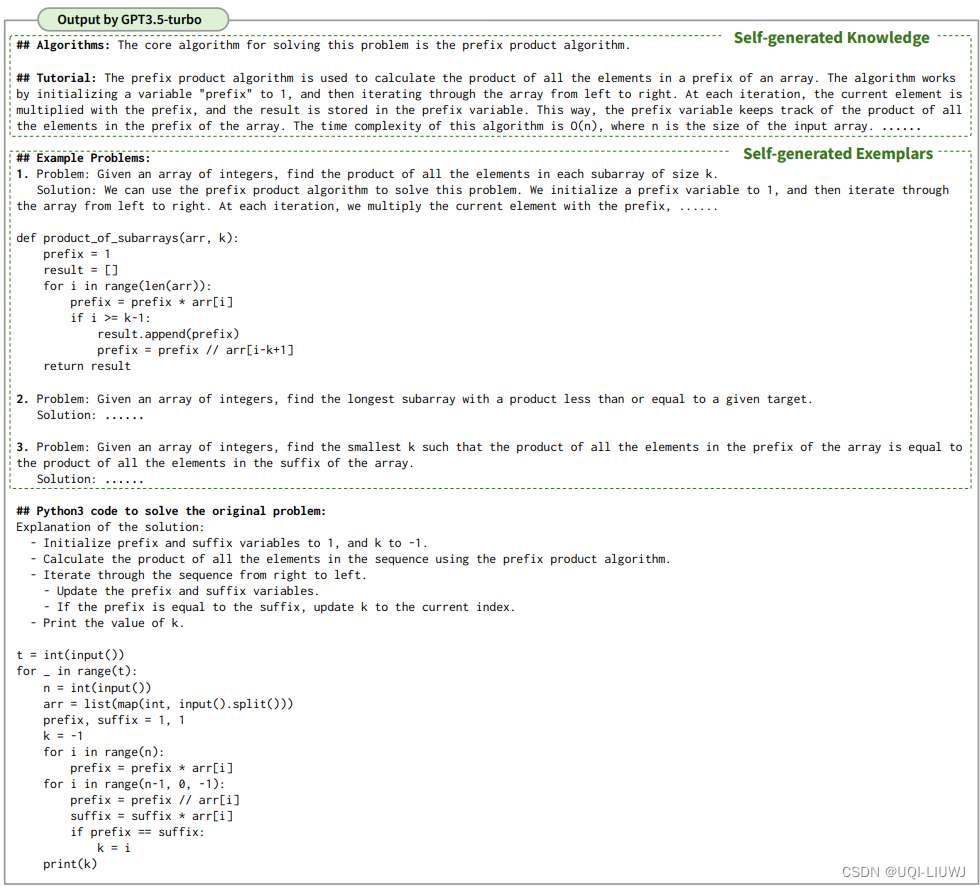
4 实验
4.1 实验任务
- 数学问题:GSM8K、MATH等;
- 代码生成:动态规划、图算法等复杂的编程题
4.2 效果比较
4.2.1 数学问题
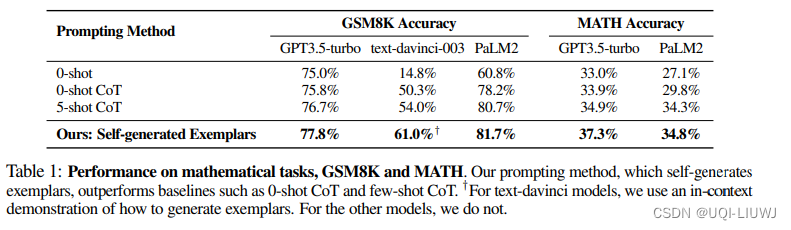
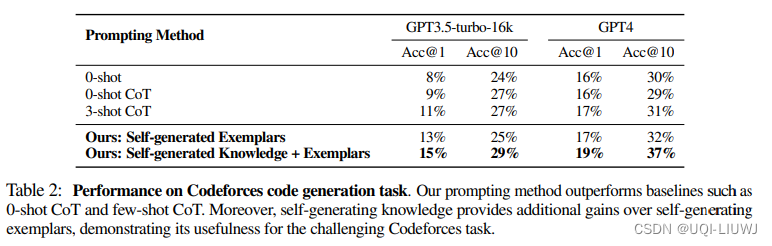
4.2.2 代码生成
4.3 few-shot example 数量的异同
这篇关于论文笔记:Large Language Models as Analogical Reasoners的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







