本文主要是介绍RDD算子(四)、血缘关系、持久化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. foreach
分布式遍历每一个元素,调用指定函数
val rdd = sc.makeRDD(List(1, 2, 3, 4))
rdd.foreach(println)
结果是随机的,因为foreach是在每一个Executor端并发执行,所以顺序是不确定的。如果采集collect之后再调用foreach打印,则是在Driver端执行。
RDD的方法之所以叫算子,就是为了与scala集合的方法区分开来, scala集合的方法是在同一个节点执行的,而RDD的算子则是在Executor(分布式节点)执行的。从计算的角度讲,RDD算子外部的操作都是在Driver端执行,算子内部的操作都是在Executor端执行。
2. 闭包检测
class User {var age : Int = 30
}val rdd = sc.makeRDD(List(1, 2, 3, 4))
val user = new User()
rdd.foreach(num => {println("age = " + (user.age + num))
})因为foreach内部的操作是在Executor上执行的,所以在Driver上创建的user需要传递给各个Executor,如果user没有序列化,则会报错

class User extends Serializable{var age : Int = 30
}或者将User变为样例类,因为样例类在编译时会自动混入序列化特质(实现可序列化接口)
case class User {var age : Int = 30
}如果把原始集合变为空,依然会报错,这是因为RDD算子中传递的函数会包含闭包操作(匿名函数,算子内用到了算子外的数据),所以会进行闭包检测,即检查里面的变量是否序列化。
val rdd = sc.makeRDD(List[Int]())
val user = new User()
rdd.foreach(num => {println("age = " + (user.age + num))
})再看如下案例:
class Search(query:String) {def isMatch(s:String): Boolean {s.contains(query)}def getMatch1(rdd: RDD[String]): RDD[String] {rdd.filter(isMatch)}def getMatch2(rdd: RDD[String]): RDD[String] {rdd.filter(x => x.contains(query))}
}val rdd = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
val search = new Search("h")
search.getMatch1(rdd).collect().foreach(println)此时会报错Search类没有序列化,因为在rdd的filter算子内调用了query,而query作为类的构造参数,实际上是类的私有变量,isMatch方法相当于:
def isMatch(s:String): Boolean {s.contains(this.query)
}this相当于类的对象,因此需要进行闭包检测。getMatch2也有类似的问题。除了将类序列化以及改为样例类之外,还可以将query赋给方法内部的临时变量:
def getMatch2(rdd: RDD[String]): RDD[String] {val s = queryrdd.filter(x => x.contains(s))
}3. 依赖关系
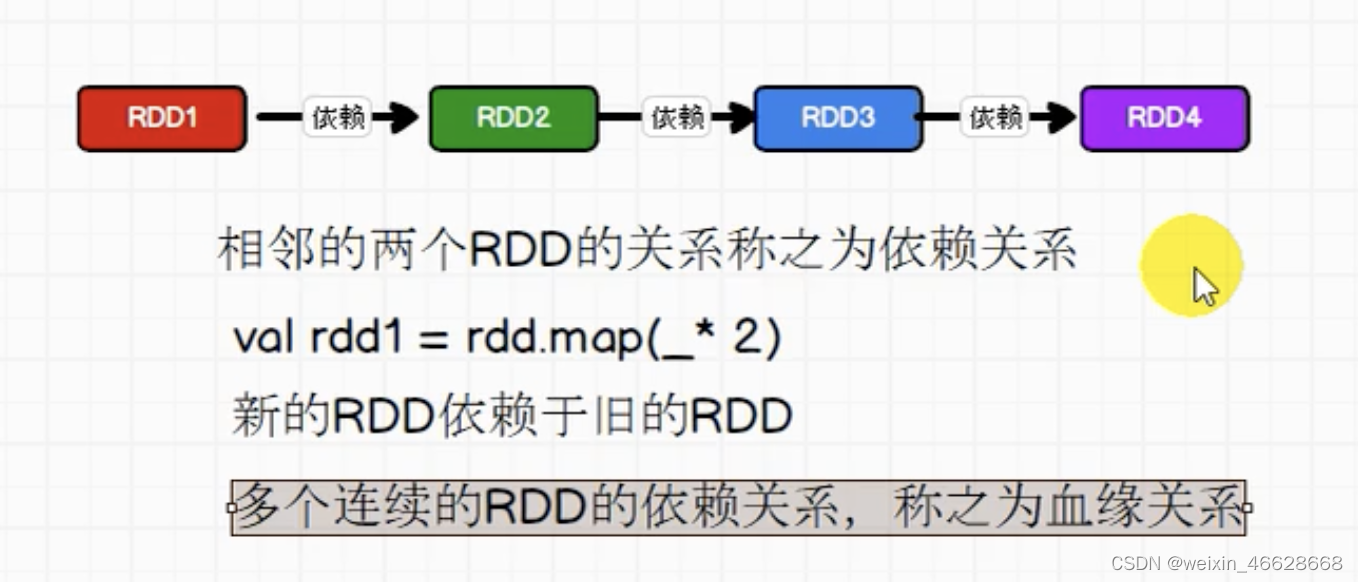
每个RDD会保存血缘关系(不会保存数据),这样提高了容错性,因为如果其中某个RDD转换到另一个RDD失败了,就可以根据血缘关系来重新读取。RDD保存依赖关系而示意图如下:
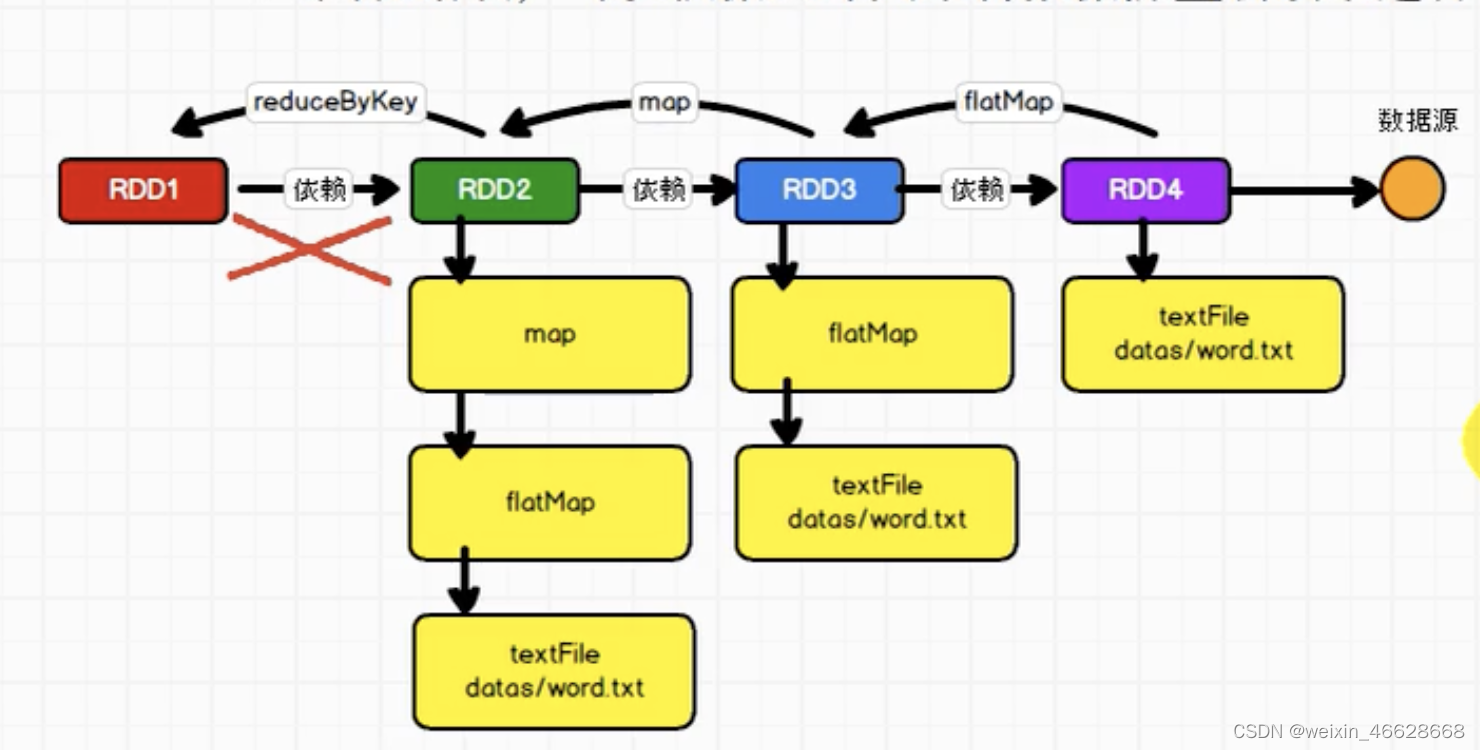
血缘关系展示代码:
val lines : RDD[String] = sc.textFile("datas")
println(lines.toDebugString)
println("******************")val words : RDD[String] = lines.flatMap(_.split(" "))
println(words.toDebugString)
println("******************")val wordToOne = words.map(word=>(word, 1))
println(wordToOne.toDebugString)
println("******************")val wordToSum : RDD[(String, Int] = wordToOne.reduceByKey(_+_)
println(wordToSum.toDebugString)
println("******************")



查看依赖关系只需直接将代码中的toDebugString改为dependencies即可
val lines : RDD[String] = sc.textFile("datas")
println(lines.dependencies)
println("******************")val words : RDD[String] = lines.flatMap(_.split(" "))
println(words.dependencies)
println("******************")val wordToOne = words.map(word=>(word, 1))
println(wordToOne.dependencies)
println("******************")val wordToSum : RDD[(String, Int] = wordToOne.reduceByKey(_+_)
println(wordToSum.dependencies)
println("******************")


一对一的依赖关系表示新的RDD的一个分区的数据来源于旧的RDD的一个分区的数据,也叫窄依赖,而Shuffle依赖关系表示新的RDD的一个分区的数据来源于旧的RDD的多个分区的数据,也叫宽依赖。
4. 阶段和任务划分
窄依赖中,分区有多少个,就有多少个任务,只有一个阶段;宽依赖中,有两个阶段,每个阶段的任务数等于分区数。
RDD阶段由有向无环图(DAG)表示

Application->Job->Stage->Task每一个层级是1对n的关系。
每个Application中可能会提交多个作业,一个作业会划分为多个阶段(阶段数=宽依赖个数+1),一个阶段可能因为多个分区而包含多个任务,一个阶段中的任务数=最后一个RDD的分区数。
5. cache和persist
如果对于同一份数据源,想做多个不同的功能(比如统计单词数以及根据单词分组),这些不同的功能在实现过程中有很多重复的步骤(比如很多相同的RDD转换),此时可能会引入性能问题。虽然看起来RDD转换的过程复用了,但是RDD不存储数据,只有逻辑,所以最终的行为算子会从头开始再读取相同的数据,比如下面代码:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)
可以看到,在一行*上下,@都执行了,说明数据从头开始读取,从最开始的RDD再次执行。
为了解决这种性能问题,可以对mapRDD里的数据进行缓存,要么缓存在内存中,要么缓存在磁盘中,得看具体情况,这就是RDD的持久化操作。使用cache方法缓存在内存中:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.cache()val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)
放在内存中可能不安全,使用persist方法缓存在磁盘中:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.persist(StorageLevel.DISK_ONLY)val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)注意:持久化操作也是等到行动算子触发才会真正执行。持久化操作不一定都是为了重用才引入的,有些情况下,前面一些RDD转换操作耗时很长或者数据很重要的场合,也可以进行持久化操作,这样一旦中间出了问题,重新执行任务不至于再执行之前耗时很长的操作。
除了以上的cache和persist方法,还可以使用检查点(checkpoint)的方法进行持久化操作。checkpoint需要落盘,因此需要指定存储路径,之前的persist方法也要落盘,只不过它存储在临时路径,任务执行完就会删除,而checkpoint是永久化存储。
sc.setCheckPointDir("cp")val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.checkpoint()val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)但是checkpoint会单独再开启一个作业,因此效率可能更低。但是与cache联合执行,即先cache,再checkpoint,就不会开启新的作业。
另外,使用cache方法会改变RDD的血缘关系:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.checkpoint()
println(mapRDD.toDebugString)val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")
println(mapRDD.toDebugString)

可以看到,cache方法(其实persis方法也会) 在血缘关系中添加新的依赖(原来的依赖还保留)。但是checkpoint方法会改变原来的血缘关系,建立新的血缘关系(等同于数据源变了):
sc.setCheckPointDir("cp")val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.checkpoint()
println(mapRDD.toDebugString)val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")
println(mapRDD.toDebugString)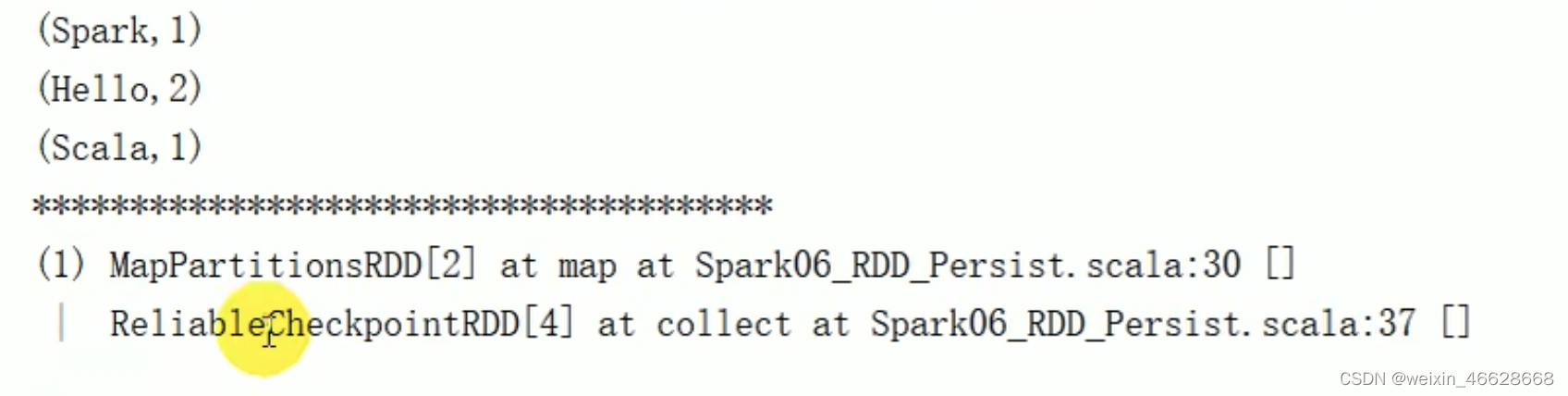
6. 自定义分区器
class MyPartitioner extends Partitioner {override def numPartitions : Int = n //自定义,可以写死override def getPartition(key : Any) : Int = {key match {case "xxx" => 0case _ => 1}}}分区器传给RDD:
val partitionRDD = rdd.partitionBy(new MyPartitioner)
这篇关于RDD算子(四)、血缘关系、持久化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








