持久专题

Redis的持久化之RDB和AOF机制详解
《Redis的持久化之RDB和AOF机制详解》:本文主要介绍Redis的持久化之RDB和AOF机制,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录概述RDB(Redis Database)核心原理触发方式手动触发自动触发AOF(Append-Only File)核

Redis持久化机制之RDB与AOF的使用
《Redis持久化机制之RDB与AOF的使用》:本文主要介绍Redis持久化机制之RDB与AOF的使用方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录Redis持久化机制-RDB与AOF一、RDB持久化机制1、RDB简介2、RDB的工作原理3、RDB的优缺点4

SpringCloud之consul服务注册与发现、配置管理、配置持久化方式
《SpringCloud之consul服务注册与发现、配置管理、配置持久化方式》:本文主要介绍SpringCloud之consul服务注册与发现、配置管理、配置持久化方式,具有很好的参考价值,希望... 目录前言一、consul是什么?二、安装运行consul三、使用1、服务发现2、配置管理四、数据持久化总

Redis事务与数据持久化方式
《Redis事务与数据持久化方式》该文档主要介绍了Redis事务和持久化机制,事务通过将多个命令打包执行,而持久化则通过快照(RDB)和追加式文件(AOF)两种方式将内存数据保存到磁盘,以防止数据丢失... 目录一、Redis 事务1.1 事务本质1.2 数据库事务与redis事务1.2.1 数据库事务1.

Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(4)
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(3)-CSDN博客 这节就是真正的存储数据了 理清一下思路: 1.存储路径并检查 //2进制文件类存储private static string Data_Binary_Pa
iptables持久化命令:netfilter-persistent save
在Linux上,使用netfilter-persistent命令可以保存iptables防火墙规则,确保它们在系统重启后仍然有效。以下是如何使用netfilter-persistent来保存iptables规则的步骤: 打开终端:首先,你需要打开Linux系统的终端。保存规则:使用netfilter-persistent save命令可以保存当前的iptables规则。这个命令会调用所有插件,将

Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(3)
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(2) (*****生成数据结构类的方式特别有趣****)-CSDN博客 做完了数据结构类,该做一个存储类了,也就是生成一个字典类(只是声明) 实现和上一节的数据结构类的方式大同小异,所

Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(2) (*****生成数据结构类的方式特别有趣****)
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 Unity数据持久化 之 一个通过2进制读取Excel并存储的轮子(1)-CSDN博客 本节内容 实现目标 通过已经得到的Excel表格数据,生成对应类对象(不赋值),一张表就是一个对象,其中包含了如下的字段 就像这样子 实现思路 上

hibernate泛型Dao,让持久层简洁起来
【前言】hibernate作为持久层ORM技术,它对JDBC进行非常轻量级对象封装,使得我们可以随心所欲的使用面向对象的思想来操作数据库。同时,作为后台开发的支撑,的确扮演了一个举足轻重的角色,那么我们在项目中如何灵活应用hibernate,也会给项目维护以及项目开发带来便利,下面我将展示我们项目中是如何来对hibernate进行应用和操作。 【目录】 -
小程序端pinia持久化
index.ts // 创建 pinia 实例const pinia = createPinia()// 使用持久化存储插件pinia.use(persist)// 默认导出,给 main.ts 使用export default pinia main.ts import { createSSRApp } from 'vue'import pinia from './stores'

Unity数据持久化 之 使用Excel.DLL读写Excel表格
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 终于找到一个比较方便容易读表的方式了,以前用json读写excel转的cvs格式文件我怎么使用怎么别扭,觉得太繁琐了 1.Excel.Dll Excel.dll 是一个库文件,通常用于在C#等编程语言中处理Excel文件。它并不是一个插件,
uniapp微信小程序开发踩坑日记:Pinia持久化报错Cannot read property ‘localStorage‘ of undefined
插件默认使用 localStorage 实现持久化,小程序端不兼容,需要替换持久化 API import { defineStore } from 'pinia' export const useCommonStore = defineStore('pack-store', {state: (): State => ({wwInfo: {},globalData: {},timerLoc

Hadoop Namenode元数据持久化机制与SecondaryNamenode的作用详解
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 我们都知道namenode是用来存储元数据的,他并不是用来存储真正的数据。 那么他的元数据怎么进行持久化呢! FsImage 文件系统的镜像文件叫fsImage,它包括了文件和块信息的映射,还有文件系统的属性信息。 datan

K8s的Pv和Pvc就是为了pod数据持久化
一、 1.pv(persistent volume):是k8s虚拟化的存储资源,实际上就是存储,列如本地的硬盘、网络文件系统(Nfs)、lvm、RAID、云存储。 2.pvc:pod对存储资源的请求,定义了需要存储的空间大小,以及对存储空间的访问模式,有了pvc请求之后,再和pv进行匹配,匹配到了之后进行绑定,绑定成功之后就可以使用pv的存储空间。 二、pv和pvc生命周期 1.配置定
Node.js 数据库操作详解:构建高效的数据持久化层
Node.js 数据库操作详解:构建高效的数据持久化层 目录 🔍 MongoDB 📌 使用 mongoose 连接 MongoDB📌 定义模型和数据验证📌 实现 CRUD 操作 🛠️ MySQL 📌 使用 mysql 或 mysql2 模块连接 MySQL📌 执行 SQL 查询📌 处理结果和错误 📊 SQLite 📌 使用 sqlite3 模块连接 SQLite📌 执行

【codeforces】484E. Sign on Fence 可持久化线段树
传送门:【codeforces】484E. Sign on Fence 题目分析:看了题解才会呢,感觉太巧妙了~ 先对高度从高到低排序,然后构造可持久化线段树,每个节点保存一个高度下对应区间的左连续最大1个数,右连续最大1个数,区间最长连续1个数,然后查询一个区间内最长连续1长度就是线段树区间合并操作。每次询问【L,R,W】就是二分询问的高度(每个高度是一棵线段树),然后看询问区间的连续

利用 FastCoding 将对象进行本地持久化
FastCoding https://github.com/nicklockwood/FastCoding A faster and more flexible binary file format replacement for NSCoding, Property Lists and JSON 一个用来替换 NSCoding , Property Lists 以及 JSON 方案

OpenHarmony持久化存储UI状态:PersistentStorage
前两个小节介绍的LocalStorage和AppStorage都是运行时的内存,但是在应用退出再次启动后,依然能保存选定的结果,是应用开发中十分常见的现象,这就需要用到PersistentStorage。 PersistentStorage是应用程序中的可选单例对象。此对象的作用是持久化存储选定的AppStorage属性,以确保这些属性在应用程序重新启动时的值与应用程序关闭时的值相同。 概述

Unity数据持久化 之 向文件流读写(详细Plus版)
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 在 Unity 手册中,FileStream 并没有单独的详细介绍,因为它是 .NET 框架的一部分,而不是 Unity 特有的类 Unity - Manual: Streaming Assets (unity3d.com) 前置知识:Unity数据持

【kubernetes】持久化存储 —— 存储类storageclass
前言 PV和PVC模式都是需要先创建好PV,然后定义好PVC和PV进行一对一的Bond后,才可以创建Pod进行使用。 但是如果PVC请求成千上万,那么就需要创建成千上万的PV,对于运维人员来说维护成本很高。因此,Kubernetes提供一种自动创建PV的机制,叫StorageClass。它的作用就是创建PV的模板。k8s集群管理员通过创建storageclass可以动态生成一个存储卷PV供k8

DDD设计方法-3-仓储,封装持久化数据
前情提要:一共包含 如下六篇文章(篇幅精简,快速入门) 1、初识DDD 2、聚合、实体、值对象 3、仓储,封装持久化数据 4、端口和适配器 5、领域事件 6、领域服务,实现约定 DDD设计方法-3-仓储,封装持久化数据 前言1、概念 什么是仓储?2、优缺点 为什么要用?3、和mapper到底什么区别?有关系吗?4、实例: 这里吧mapper 和 Repository 都写出来做个比较更直
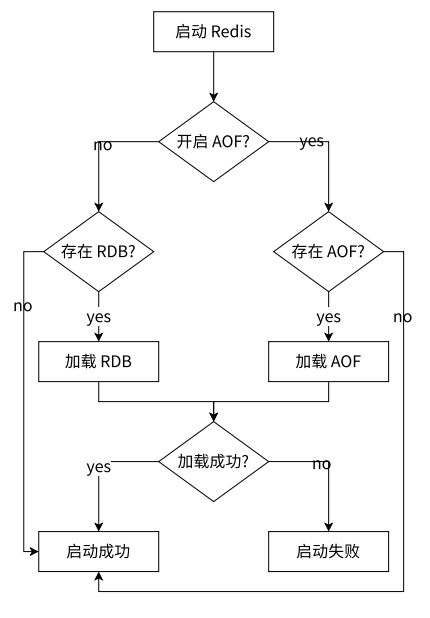
【Redis】Redis 持久化机制详解:RDB、AOF 和混合持久化的工作原理及优劣分析
目录 持久化RDB触发机制流程说明RDB ⽂件的处理RDB 的优缺点 AOF使⽤ AOF命令写⼊⽂件同步重写机制启动时数据恢复 混合持久化小结 持久化 回顾 MySQL 的事务的特性: 原子性一致性持久性(持久化)隔离性 持久化:把数据存储在硬盘上就是持久的(重启进程/主机,数据还会存在),把数据存储在内存上就是不持久。 Redis 是一个内存数据库,要想做到持久,就要

深入Redis:细谈持久化
Redis的数据是保存在内存中的,内存里面的数据是不持久的,要想做到持久化,必须要把在内存中的数据储存到硬盘上。 Redis速度非常快,数据只有在内存中才有这样的速度,但是为了持久,数据还是要想办法保存到硬盘上去。于是,Redis决定,内存中也存数据,硬盘上也存数据,这样的两份数据理论上是完全一样的。 当需要插入一个新的数据的时候,就把这个数据同时写入到内存和硬盘,当查询某个数据的时候直接从内

吃透Redis系列(五):RDB和AOF持久化详细介绍
Redis系列文章: 吃透Redis系列(一):Linux下Redis安装 吃透Redis系列(二):Redis六大数据类型详细用法 吃透Redis系列(三):Redis管道,发布/订阅,事物,过期时间 详细介绍 吃透Redis系列(四):布隆(bloom)过滤器详细介绍 吃透Redis系列(五):RDB和AOF持久化详细介绍 吃透Redis系列(六):主从复制详细介绍 吃透Redi

Unity (编辑器)数据持久化 之 ScriptableObject初识与创建
1.什么是ScriptableObject ScriptableObject - Unity 手册 如题,一个可以在Unity编辑器中方便编辑数据的工具 一个脚本继承该类,并且序列化或者有公共变量,即可在Inspector窗口看到它们 其特点: Q:是否可以将 ScriptableObject的数据保存到本地? A:可以,可以通过Json的序列化与反序列化保存 Scriptab