血缘关系专题

探索利用 LineageLogger 获取hive的字段级血缘关系
apache hive 源码中有 org.apache.hadoop.hive.ql.hooks.LineageLogger 类可以获取 insert hql 的字段之间的关系。但是又由于 org.apache.hadoop.hive.ql.optimizer.Optimizer的原因,使我们重写 hook 类无法实现字段级血缘。 if (hiveConf.getBoolVar(HiveCo

Spark RDD序列化与血缘关系
RDD序列化 从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。所以需要涉及到网络传输,且如果计算中涉及到算子以外的数据那么就要求这个数据进行序列化,因为没有序列化就代表无法进行网络传输也就无法将值传到其它Excutor端执行,就会发生错误。 (1)闭包检查 在scala的函数式编程中,函数内经常会用到函数外变量,这样就会形成闭包效果,
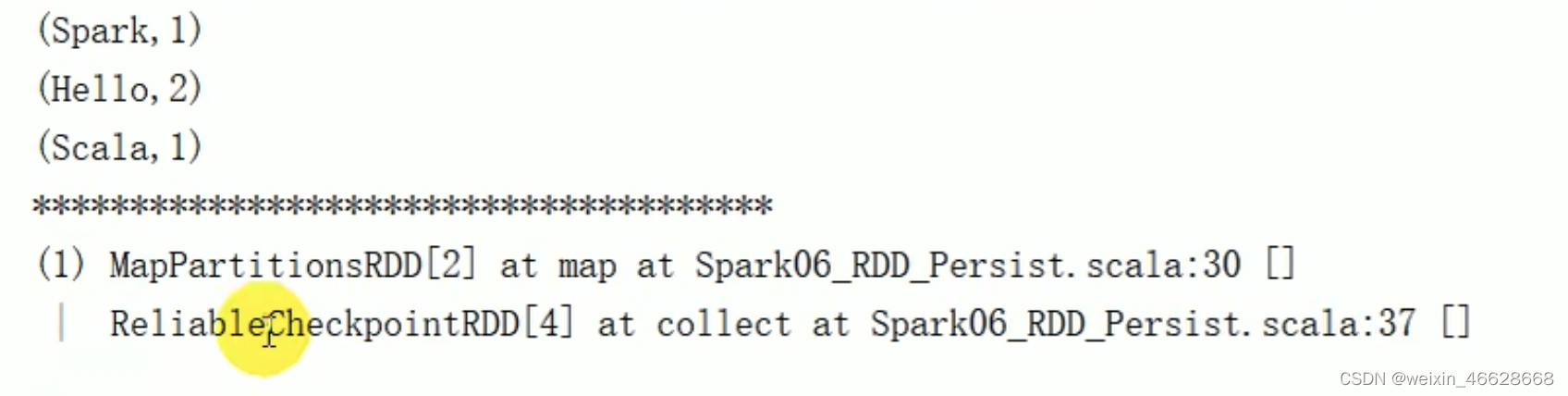
RDD算子(四)、血缘关系、持久化
1. foreach 分布式遍历每一个元素,调用指定函数 val rdd = sc.makeRDD(List(1, 2, 3, 4))rdd.foreach(println) 结果是随机的,因为foreach是在每一个Executor端并发执行,所以顺序是不确定的。如果采集collect之后再调用foreach打印,则是在Driver端执行。 RDD的方法之所以叫算子,就是为了与sc

阻断血缘关系以及checkpoint文件清理
spark-sql读写同一张表,报错Cannot overwrite a path that is also being read from 1. 增加checkpoint,设置检查点阻断血缘关系 sparkSession.sparkContext.setCheckpointDir("/tmp/spark/job/OrderOnlineSparkJob")val oldOneIdTagSql
Linux-实现没有血缘关系的进程之间的通信
目录 一.makefile的编写 二.comm.hpp头文件的编写 三.serve.cc文件的编写 四.client.cc文件的编写 一.makefile的编写 .PHONY:allall:serve clientserve : serve.ccg++ -o $@ $^ -g -std=c++11client : client.ccg++