本文主要是介绍Cache多核之间的一致性MESI,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
快速链接:
- 【精选】ARMv8/ARMv9架构入门到精通-[目录] 👈👈👈
思考:
1、为什么要学习MESI协议? 哪里用到了?你确定真的用到了?
2、MESI只是一个协议,总得依赖一个硬件去执行该协议吧,那么是谁来维护或执行的呢?
3、你不理解的真的是MESI吗,真的需要学习MESI吗? 应该是cache架构吧
4、core0和core1之间的一致性是MESI? 那cluster0和cluster1之间的呢? sytem1和sytem2之间的呢?
5、MESI协议中的M、E、S、I 的比特位,都是存在哪里的?
1、系统中有哪些一致性需要维护
进入正文,我们来看现代ARM 架构体系(DynamIQ架构)中的cache层级关系图。注意L1/L2都在core中,L3在cluster中。
所以从以下图中就能够直观的看到答案了:
- (1)core0、core1…之间的一致性 需要维护
- (2)cluster0和cluster1之间的L3 Cache一致性 需要维护
- (3)system之间的一致性需要维护

其中,core0、core1之间的一致性是遵从MESI协议,而cluster0/cluster1之间的一致性、多个system之间的一致性并没有遵从MESI协议。
所以本文重点介绍的,也就是core0、core1之间的一致性,即MESI协议。
2、core硬件对MESI协议的支持
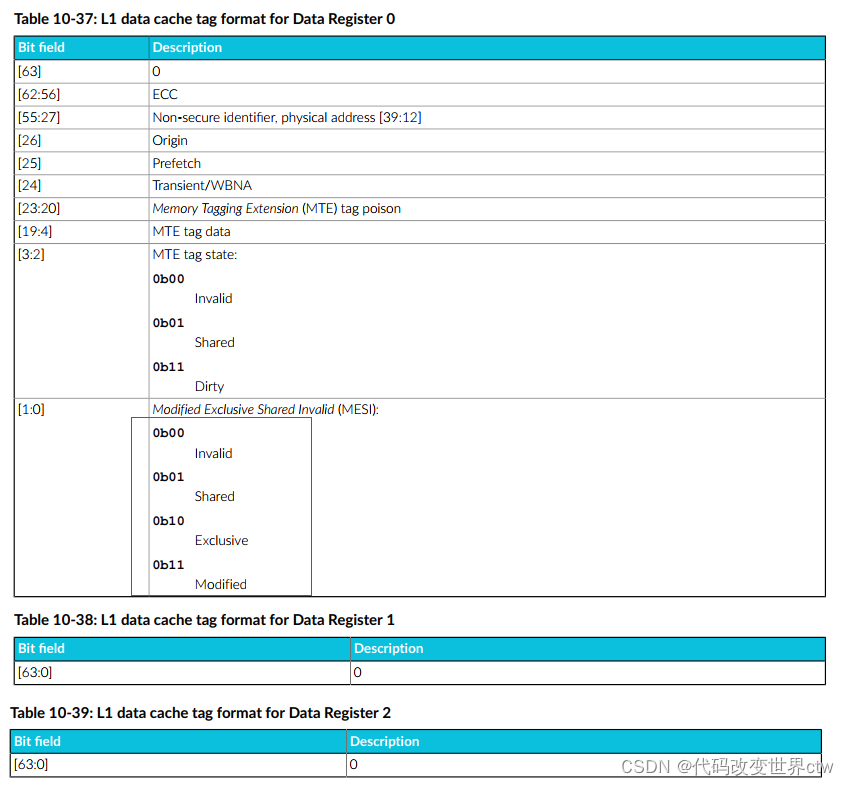
接下来,进入下一个问题, MESI协议中的M、E、S、I 的比特位都是存在哪里的? 这个问题并不难,告别懒惰,多翻一翻ARM TRM手册就能找到答案,如下是armv9 -- cortex-A710 TRM手册中的,cache的TAG里都有什么?
答案显然易见,在Cache的TAG中,有两个比特位表示了MESI的状态
3、MESI协议的原理
接下来进入本文的核心,MESI协议到底是什么?怎样维护一致性的?
(看以下图表,我就不说话了)



Events:
- RH = Read Hit
- RMS = Read miss, shared
- RME = Read miss, exclusive
- WH = Write hit
- WM = Write miss
- SHR = Snoop hit on read
- SHI = Snoop hit on invalidate
- LRU = LRU replacement
Bus Transactions:
- Push = Write cache line back to memory
- Invalidate = Broadcast invalidate
- Read = Read cache line from memory
关注"Arm精选"公众号,备注进ARM交流讨论区。

这篇关于Cache多核之间的一致性MESI的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




