本文主要是介绍回溯算法|491.递增子序列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
力扣题目链接
class Solution {
private:vector<vector<int>> result;vector<int> path;void backtracking(vector<int>& nums, int startIndex) {if (path.size() > 1) {result.push_back(path);// 注意这里不要加return,要取树上的节点}unordered_set<int> uset; // 使用set对本层元素进行去重for (int i = startIndex; i < nums.size(); i++) {if ((!path.empty() && nums[i] < path.back())|| uset.find(nums[i]) != uset.end()) {continue;}uset.insert(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了path.push_back(nums[i]);backtracking(nums, i + 1);path.pop_back();}}
public:vector<vector<int>> findSubsequences(vector<int>& nums) {result.clear();path.clear();backtracking(nums, 0);return result;}
};这题要在理解的“子集II”这题的基础上写会好很多~
代码随想录 (programmercarl.com)
思路
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II (opens new window)。
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II (opens new window)中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
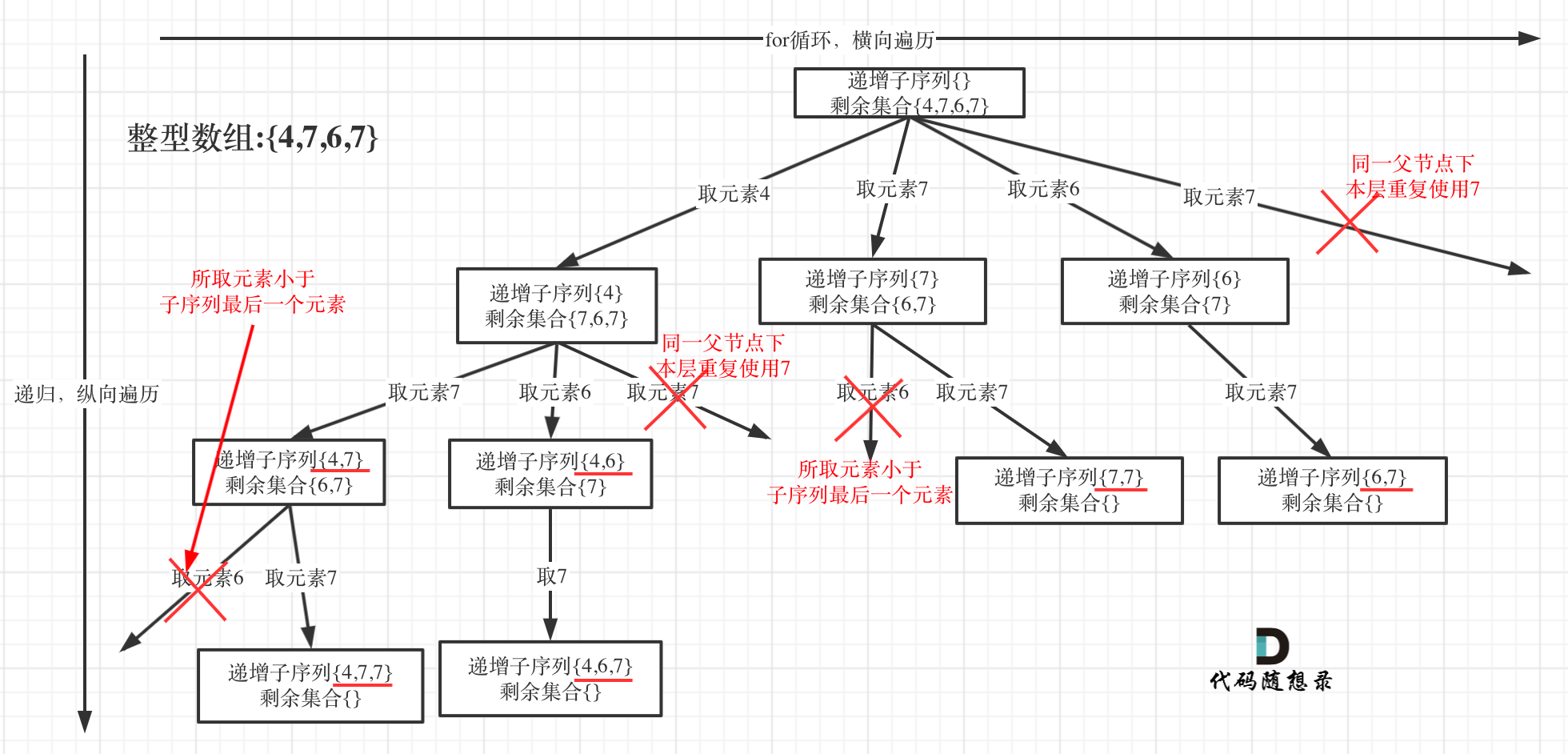
#回溯三部曲
- 递归函数参数
本题求子序列,很明显一个元素不能重复使用,所以需要startIndex,调整下一层递归的起始位置。
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex)
- 终止条件
本题其实类似求子集问题,也是要遍历树形结构找每一个节点,所以和回溯算法:求子集问题! (opens new window)一样,可以不加终止条件,startIndex每次都会加1,并不会无限递归。
但本题收集结果有所不同,题目要求递增子序列大小至少为2,所以代码如下:
if (path.size() > 1) {result.push_back(path);// 注意这里不要加return,因为要取树上的所有节点
}
- 单层搜索逻辑
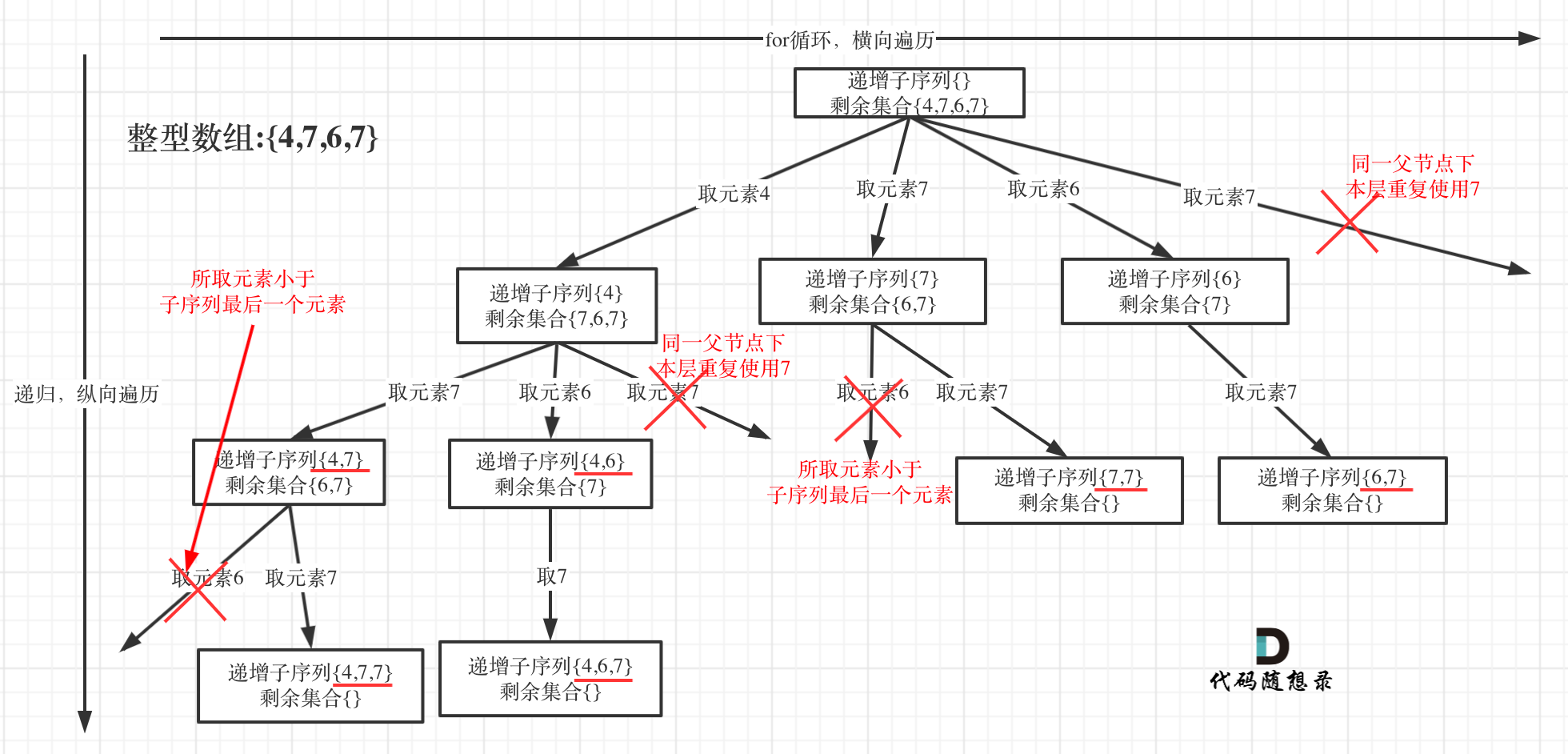
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了
那么单层搜索代码如下:
unordered_set<int> uset; // 使用set来对本层元素进行去重
for (int i = startIndex; i < nums.size(); i++) {if ((!path.empty() && nums[i] < path.back())|| uset.find(nums[i]) != uset.end()) {continue;}uset.insert(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了path.push_back(nums[i]);backtracking(nums, i + 1);path.pop_back();
}
对于已经习惯写回溯的同学,看到递归函数上面的uset.insert(nums[i]);,下面却没有对应的pop之类的操作,应该很不习惯吧
这也是需要注意的点,unordered_set<int> uset; 是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层!
自己理解的思路:
知识点:
unordered_set和unorder_map很类似,内部都是无序的!
unordered_set是一种无序集合,其底层实现基于hashtable,因此具有快速的查找和删除,添加的优点,因此在需要多次查找和删除的场景里可以用unordered_set来存储数据!
那个去重部分的代码还是不好理解,自己还没完全掌握。
这篇关于回溯算法|491.递增子序列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








