本文主要是介绍【御控物联】JSON结构数据转换在物流调度系统中的应用(场景案例三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、前言
- 二、场景概述
- 三、解决方案
- 四、在线转换工具
- 五、技术资料
一、前言
物流调度是每个生产厂区必不可少的一个环节,主要包括线边物流和智能仓储。线边物流是指将物料定时、定点、定量配送到生产作业一线的环节,其包括从集中仓库到线边仓、从生产线的上游工位到下游工位、从工位到缓冲仓。智能仓储是以信息交互为主线,使用条形码、RFID、传感器、定位系统、智能小车(AGV)等先进的物联网技术,可以实现物料运输、物料入库存储、物料搬运、产品分拣等作业全流程自动化、智能化。
随着越来越多新技术、新产品的出现,很多工厂正在逐步通过引进新产品,对既有产线物流进行升级改造,直接造成系统和系统之间、系统和设备之间交互逻辑越来越多,越来越复杂,从而增大了公司的运维成本。如何利用技术手段减少各系统之间、系统和设备之间交互逻辑的定制开发、降低运维成本、提高管理效率是每个企业亟待解决的问题。
增大运维成本主要受两方面影响,第一,系统与系统之间、系统与设备交互逻辑定制化,比如WMS和WCS,WCS和各种智能设备(AGV、叉车)之间,一旦出现业务变动,各交互系统都需要技术人员更新代码逻辑。第二,数据格式不统一,这一方面也是引起运维成本增加的部分,比如(WMS、WCS)采用的JSON数据格式和(WCS、AGV)之间交互采用的JSON数据格式不一致,这就造成WCS需要针对不同的交互对象维护两套不同的数据格式解析代码,一旦数据格式有调整,将造成成本的无限增加。
针对第一方面影响,工厂可搭建零编程、可拖拽、支持在线调式的规则引擎中间件,此中间件可实现与各业务单元的逻辑交互,减少系统与系统之间、系统与设备之间的交互,进而保证业务逻辑协同化;针对第二方面的影响,工厂应该考虑在系统中集成灵活实现数据格式转化的功能,而且支持业务人员操作,这样可降低开发成本和以后的运维成本。
本文针对第二方面影响提出我们的解决方案,一套JSON数据格式转换代码库(JS),在业务系统集成此库可灵活应对各类JSON数据格式的相互转化,包括从外部系统对接过来的JSON数据,也支持将自己数据编码后转发给其它业务系统或设备,实现JSON数据格式自由转换。目前支持以下映射关系转化:数据源键(Key)->目标键(Key)、数据源键(Key)->目标值(Value)、数据源值(Value)->目标键(Key)、数据源值(Value)->目标值(Value)。
本文结合案例对JSON格式数据转换进行如下讲解。
二、场景概述
某工厂生产线具备MES、WMS、WCS业务系统,同时配备了AGV小车、立体库等智能设备。具体业务场景如下图所示。工人在组装产品过程中需要A物料,然后通过MES系统将物料信息发送给WMS,WMS系统收到数据后进行解析,找到物料所在位置及数量,WMS系统确认后会给WCS系统下发去C库区001号位置获取物料,WCS反馈物料到位信息;然后WMS会向AGV发送任务指令(拣选、搬运和配送),AGV将物料送至位置后反馈执行状态和进度给WMS,同时MES也会给WMS一条反馈指令,告知物料已到位,形成物料配送闭环。
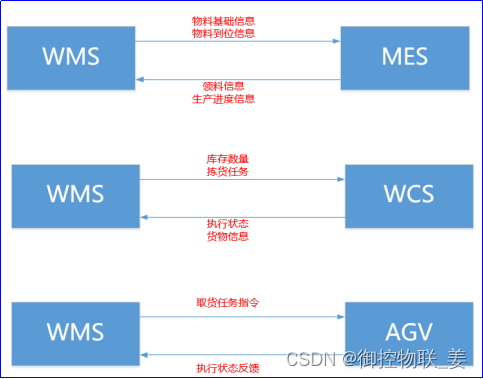
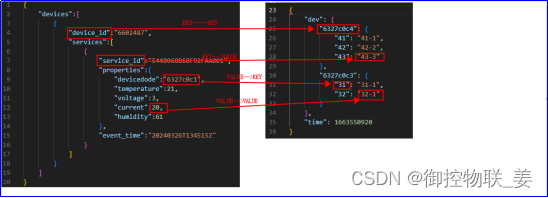
以上系统与系统交互、系统与设备交互均采用HTTP通讯方式,数据交互格式采用JSON,由于供应商不同,造成数据交互结构层次各不相同。
WMS与MES交互数据格式如下:
WMS与WCS交互数据格式如下:
如果没有我们的JS库,WMS需要针对以上三种数据交互格式定制化开发三套代码,非常不利于产品的打磨,尤其在项目前期,业务变动非常大,一些小的数据格式改动,都会引起大的开发工作,进而提高了开发成本。
三、解决方案
如果系统引入JSON数据格式转换JS库后,只需要业务人员根据不同厂家的数据结构进行关系映射,即可应对各类数据格式变换的场景,无需技术人员修改代码。
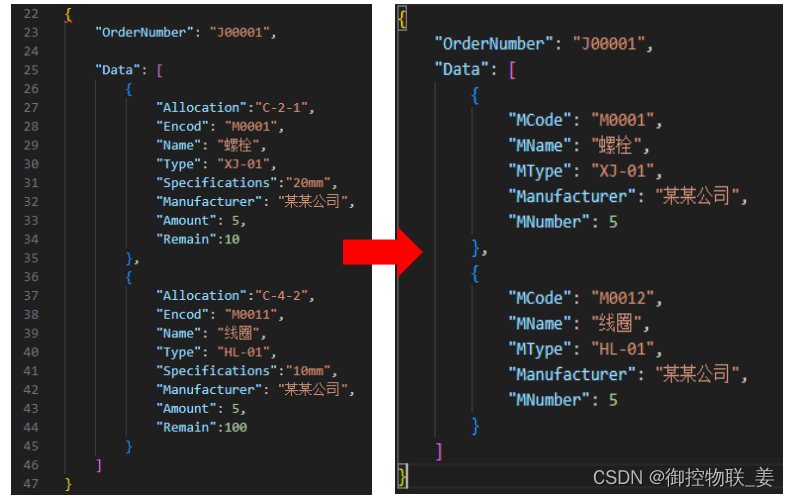
WMS与MES建立映射关系如下:
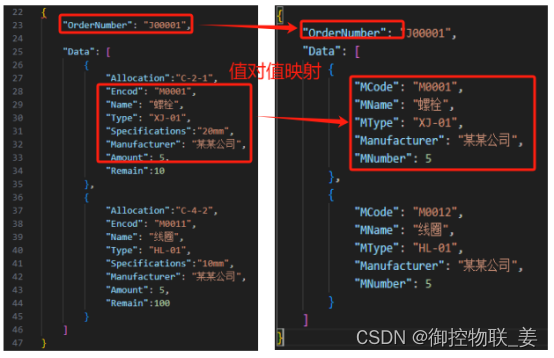
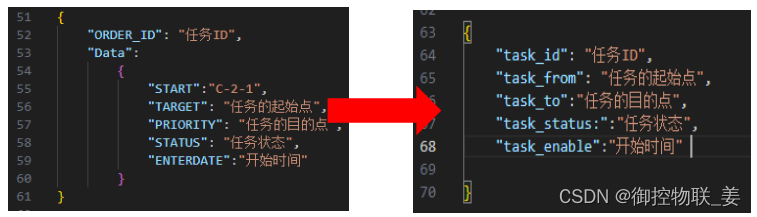
WMS与WCS建立映射关系如下:

通过JSON数据格式转化JS库可方便业务人员快速搭建各业务场景的数据映射,特别适用于不同厂家系统和设备的数据交互,减少业务定制,降低开发成本。
为了更直观体现JSON数据格式转化的功能,特此做了一套转化工具,以下为DEMO展示,可实现值对值映射,键和值映射,对象和数组内容映射
四、在线转换工具
为了让使用者更加方便的配置出映射关系,为此开发了一套在线转换工具,可在工具中通过拖拽即可配置想要的结构转换关系,并可对转换关系所能实现的效果实时进行预览更改。
工具地址:数据转换工具

五、技术资料
- Github:edq-ebara/data-transformation-javascript: 数据转化(javascript) (github.com)
- 技术探讨QQ群:775932762
- 工具连接:数据转换工具
- 御控官网:https://www.yu-con.com/
这篇关于【御控物联】JSON结构数据转换在物流调度系统中的应用(场景案例三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




