本文主要是介绍一起重新开始学大数据-MySQL篇-Day36-case值替换,备份表,稍微了解一下视图,事务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 一起重新开始学大数据-MySQL篇-Day36-sql(4) |

| case:值的替换 |
格式:
case when 条件 then 为true的结果 [when 条件 then 为true的结果] [else 为false的结果] end
背景:发现查询性别的时候,写的是0或1
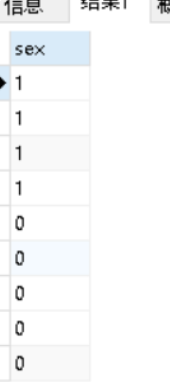
解决:使用case,进行值得替换
SELECT name, CASE WHEN sex=1 THEN '女' ELSE '男' END AS 性别 FROM students;
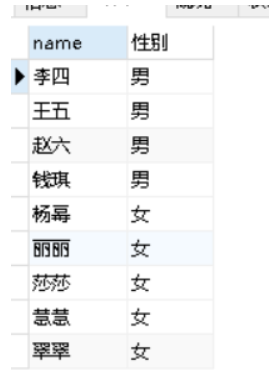
| 从其他表加载数据(备份,复制) |
格式1:
create table 表名 as 查询语句;
格式2:
insert into 表名 查询语句;
注意:
字段属性和数据类型和其他表保持一致
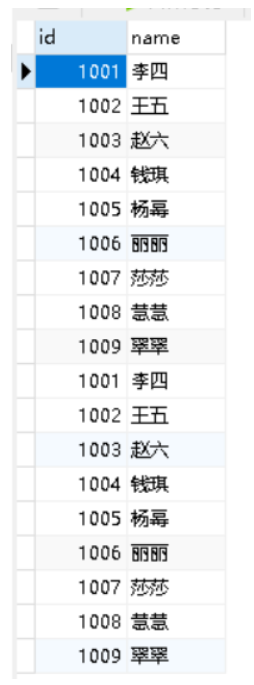
CREATE TABLE 名单 AS SELECT id,name FROM students;
INSERT INTO 名单 SELECT id,name AS 姓名 FROM students;

| 视图: |
由查询结果得到的一张虚拟表(临时表,虚表),虚拟表和基本表有一对一和一对多的关系
创建:
create view 视图名称 as 查询语句
CREATE VIEW 名单视图 AS SELECT id,name FROM students;
CREATE VIEW 信息名单 AS SELECT 名单.*,students.age,students.sex FROM 名单 LEFT JOIN students ON 名单.id=students.id;


一对一(数据和基本表一样):增删改查
一对一(数据由基本表聚合):查
一对多(数据由基本表聚合):查
一对多(数据由连表联查):查改
注意:虚拟表不存储任何数据,数据存储在基本表中,基本表当中数据发生改变虚拟表中的数据也能发生改变创建视图,查询语句中不能出现子查询(不能作为一张表,可以作为结果进行筛选),把子查询作为视图之后再创建视图
查询视图结构:
desc 视图名称;
show create view/table 视图名称;
desc 信息名单;
SHOW CREATE VIEW 信息名单;

删除视图:
drop view 视图名称;
DROP VIEW 名单视图;

| 执行计划 |
查询语句遵循顺序:from–where–group by–having–select–order by
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by按照什么样的顺序来查看返回的数据
| 索引 |
定义
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果.表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间
添加:
alter table 表名 add index 索引名称(字段);
删除:
alter table 表名 drop index 索引名称;
注意:每个字段都可以添加索引
主键默认含有索引
不要每个字段都添加索引(索引也需要消耗资源),只需要给常用字段添加索引
事务:批处理,保证多个sql语句一起执行成功或一起执行失败(回滚撤销当前操作)
什么是是事务?
首先,什么是事务?事务就是一段sql 语句的批处理,但是这个批处理是一个
atom(原子),不可分割,要么都执行,要么回滚(rollback)都不执行。
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
在 MySQL 中只有使用了Innodb数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
事务用来管理insert,update,delete语句
事务的特性:
原子性(A):事务是最小单位,不可再分
一致性(c ):事务要求所有的DML语句操作的时候,必须保证同时成功或者同时失败
隔离性(I):事务A和事务B之间具有隔离性
持久性(D):是事务的保证,事务终结的标志(内存的数据持久到硬盘文件中)
开始事务:
begin;
回滚事务:
rollback;
提交事务:
commit;
结束事务:
end;
注意:
没有
commit或end之前,事务中的所有操作都是临时的(在缓存中的)
commit或end之后,把这些临时的(在缓存中的)数据提交到原始数据中进行修改
end默认执行commit;
|
|
|
|
|
上一章-一起重新开始学大数据-MySQL篇-Day35-练习题
下一章-MySQL篇-Day37-sql(5)-shell操作MySQL,java操作MySQL、附带JDBC的NullPointerException
|
|
|
|
| 听说长按大拇指👍会发生神奇的事情呢!好像是下面的画面,听说点过的人🧑一个月内就找到了对象的💑💑💑,并且还中了大奖💴$$$,考试直接拿满分💯,颜值突然就提升了😎,虽然对你好像也不需要,是吧,吴彦祖🤵! |



这篇关于一起重新开始学大数据-MySQL篇-Day36-case值替换,备份表,稍微了解一下视图,事务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



