本文主要是介绍【御控物联】JSON结构数据转换在物联业务中应用(场景案例二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、物联网业务场景现状
- 二、物联网业务场景数据交互格式
- 三、JSON格式数据转换案例
- 四、JSON数据格式转换DEMO
一、物联网业务场景现状
目前,市场上多数物联网关与物联平台捆绑售卖,网关采集到设备数据只能按照指定的协议和规定的数据格式传输到绑定的物联平台。
一旦用户想把不同厂家网关采集的设备数据上传至现在已经建设的物联平台,或者是想把现在已经使用网关的数据传输到不同厂家平台,都需要定制化开发。
定制化体现在两个方面,第一,协议定制化,市面上大部分网关都支持标准的MQTT协议,可实现快速的开发复制,甚至很多网关都集成了对外转发的各种协议,比如HTTP、WebSocket,只需简单配置即可实现协议的连接通讯。第二,数据格式定制化,这一方面是用户比较困扰的地方,大部分网关或平台与不同厂家的系统进行数据交互需要定制开发,当然现在市面上也有一分部网关或平台内置JS、Lua脚本编辑器,支持通过编写逻辑代码实现各种数据结构的转换,此方案更多面向技术人员,业务人员无法入手,而且执行效率比较低。
二、物联网业务场景数据交互格式
目前物联业务场景常采用二进制、XML、JSON方式进行数据传输。
二进制是一种轻量化的数据格式,结构简洁,占用网络带宽小,传输效率高,也是现在主要推广的数据传输方式,特别对采用SIM卡传输数据的场景,可以大大减少流量消耗,但是结构不够直观,可读性比较差。
XML(Extensible Markup Language,扩展标记语言)是一种“重量级”的数据交换格式,XML格式统一、语法要求严格,标准化程度和可读性都非常高,但占用存储空间大,网络传输慢,不太适合大数据量传输的场景。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,结构简洁,层次分明,解析起来更快,占用的存储空间少,网络传输也较快,是目前物联业务常用的数据交互格式。
本文针对物联业务JSON格式数据转换转化设计了一种面向业务人员的标准JS库,可实现不同厂家网关、不同平台之间任意JSON数据格式无缝转换。网关或物联平台集成JS库可实现JSON格式数据转换:数据源键(Key)->目标键(Key)、数据源键(Key)->目标值(Value)、数据源值(Value)->目标键(Key)、数据源值(Value)->目标值(Value)。
三、JSON格式数据转换案例
本文结合实际案例对JSON格式数据转换进行如下讲解。
案例概述:
某知名水泥公司现场有PLC、仪表类设备(水表、电表、气表)以及一套成熟的物联网平台,由于部分设备改造升级,采购了一批新的物联网关(御控),要求将改造设备数据通过新网关以原有物联平台要求的JSON数据格式上传,前提是不改动原有物联网平台的任何逻辑功能。
御控网关与PLC采用OPC UA方式进行通信,与仪表采用MODBUS协议进行通信,采集数据通过MQTT协议上传至物联网平台,由物联网平台进行数据存储和展示,逻辑图如下所示:
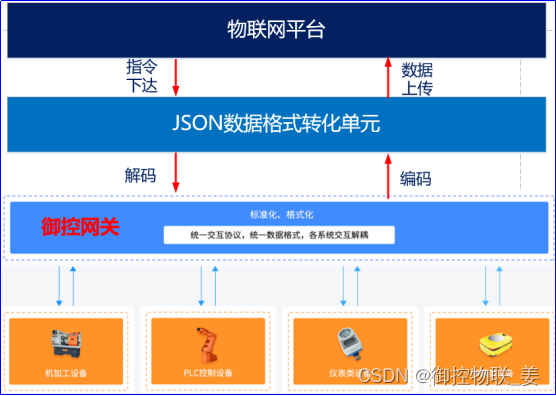
御控网关创建PLC和仪表设备监控点表(属性)->配置JSON格式转化->配置MQTT转发信息->物联网平台。
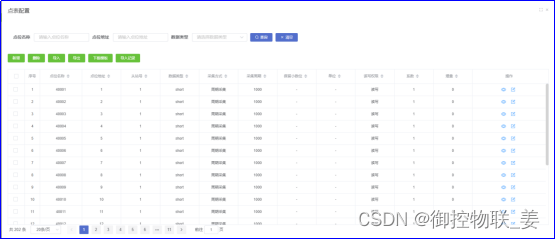
御控网关根据PLC、仪表设备检测点维护点表信息,包含名称、数据类型、点位标识、采集方式、采集周期等。
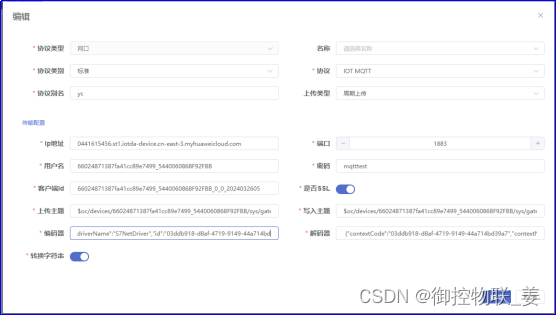
御控网关通过界面维护与水泥厂原有物联网云平台进行MQTT连接的信息,包括IP、端口、用户名、密码等信息。
御控网关集成JSON数据格式转化库,实现数据编码和数据解码两种功能。其中数据编码将网关内部采集的数据按照物联网平台要求的JSON数据格式进行转换,上传至平台。数据解码可以将物联网平台下发的JSON格式指令进行反向解析,转换为网关支持的JSON数据,实现物联网平台对网关的反向控制。
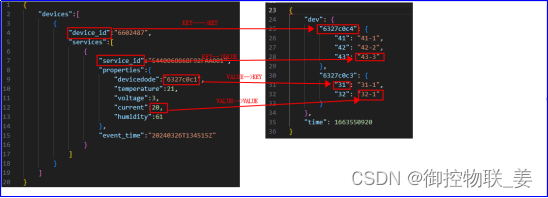
其中御控网关采集PLC点表上传的数据格式为:

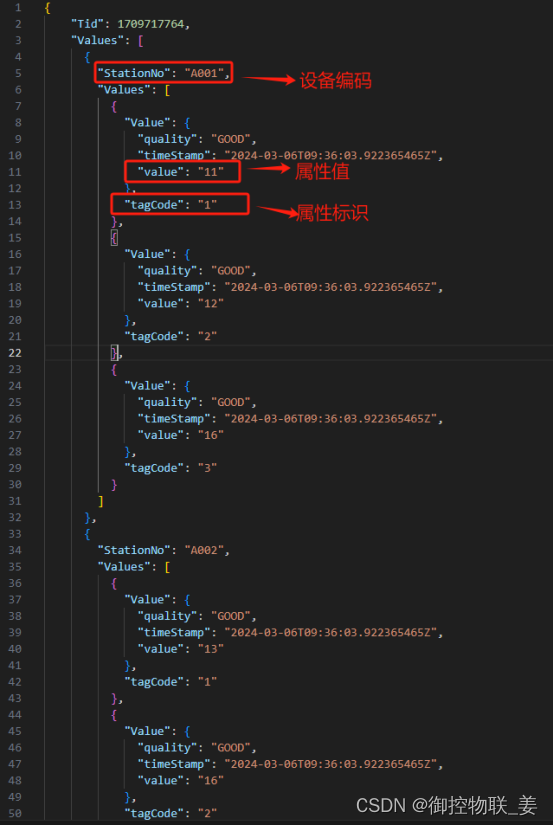
水泥厂物联网平台接受的数据格式为:
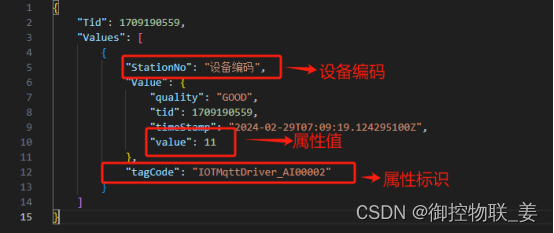
通过数据转换将御控网关上传的“设备编码”、“设备属性值”、“时间戳”分别通过数据源键(Key)->目标值(Value)、数据源值(Value)->目标值(Value)两种映射关系实现了数据转化,转化结果如下所示:
通过JSON数据格式转化JS库可方便业务人员快速搭建各业务场景的数据映射,特别适用于不同厂家网关和不同厂家物联网平台的解耦和数据交互,减少业务定制,降低开发成本。
四、JSON数据格式转换DEMO
为了更直观体现JSON数据格式转化的功能,特此针对以上场景做了一套转化工具,以下为DEMO展示。
这篇关于【御控物联】JSON结构数据转换在物联业务中应用(场景案例二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




