本文主要是介绍视觉Transformer和Swin Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视觉Transformer概述
ViT的基本结构:
①输入图片首先被切分为固定尺寸的切片;
②对展平的切片进行线性映射(通过矩阵乘法对维度进行变换);
③为了保留切片的位置信息,在切片送入Transformer编码器之前,对每个切片加入位置编码信息;
④Transformer编码器由L个Transformer模块组成,每个模块由层归一化(LN)、多头自注意力模块(MHSA)、多层感知机(MLP)及残差连接等构成;
多层感知机(MLP)![]() https://blog.csdn.net/JasonH2021/article/details/131021534
https://blog.csdn.net/JasonH2021/article/details/131021534
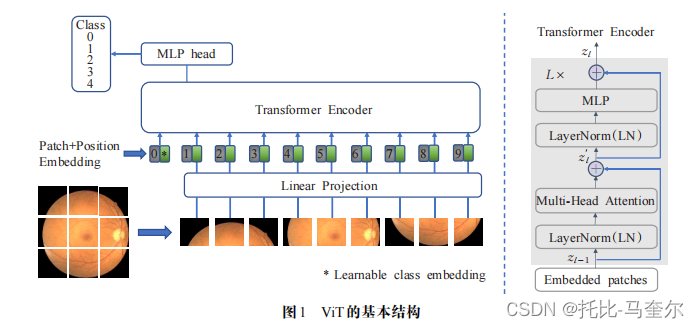
其中, 和
分别表示第
个模块中MHSA和MLP的输出特征
由于ViT关注分类问题,编码器的输出只关注最后一个Transformer模块的MLP头部信息,。只有在大规模数据集上进行预训练再迁移到中小规模数据集的条件下,ViT才能取得与当时最新卷积结构媲美的性能。
Swin Transformer
最大的贡献在于降低了self-attention的计算复杂度。
Swin Transformer在视觉Transformer的基础上引入了移动窗口(shifted windows)机制,采用“分而治之”的思想,将自注意力的计算限制在各个窗口内从而使得模型只有和输入图片尺寸相关的线性复杂度。
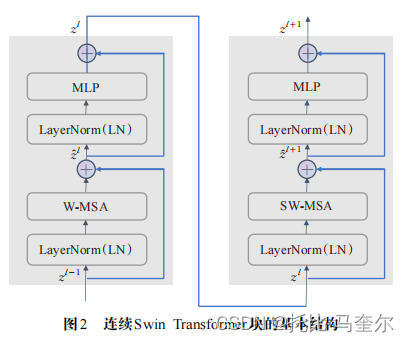
连续Swin Transformer块
其在Transformer编码器基础上,将对头自注意力模块(MHSA)替换为常规窗口多头自注意力(W-MHSA)和移动窗口多头自注意力(SW-MHSA)模块。
其中,和
分别表示第
个模块中(S)W-MSA和MLP的输出特征
这篇关于视觉Transformer和Swin Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!