本文主要是介绍2004-2022年上市公司企业战略激进度数据(含原始数据+计算代码+计算结果),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2004-2022年上市公司企业战略激进度数据(含原始数据+计算代码+计算结果)
1、时间2004-2022年
2、来源:原始数据整理自csmar
3、指标:
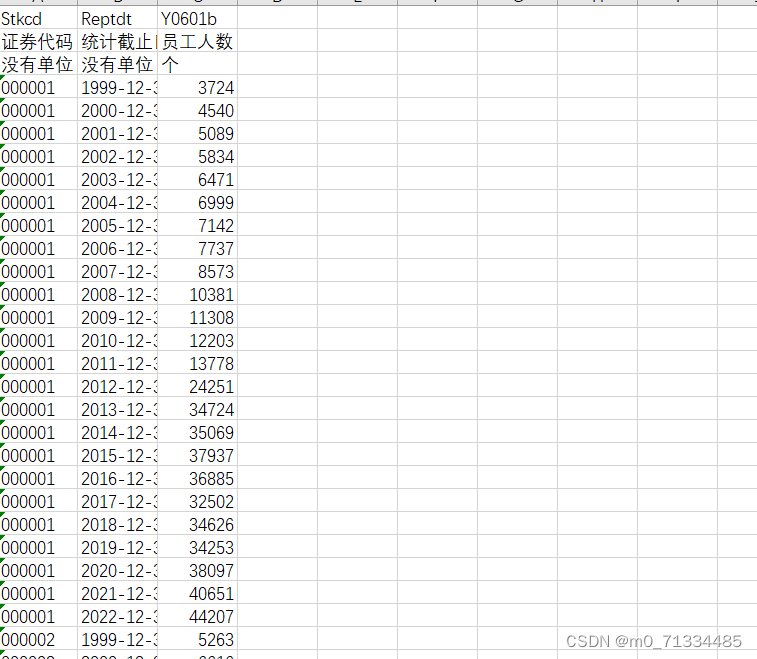
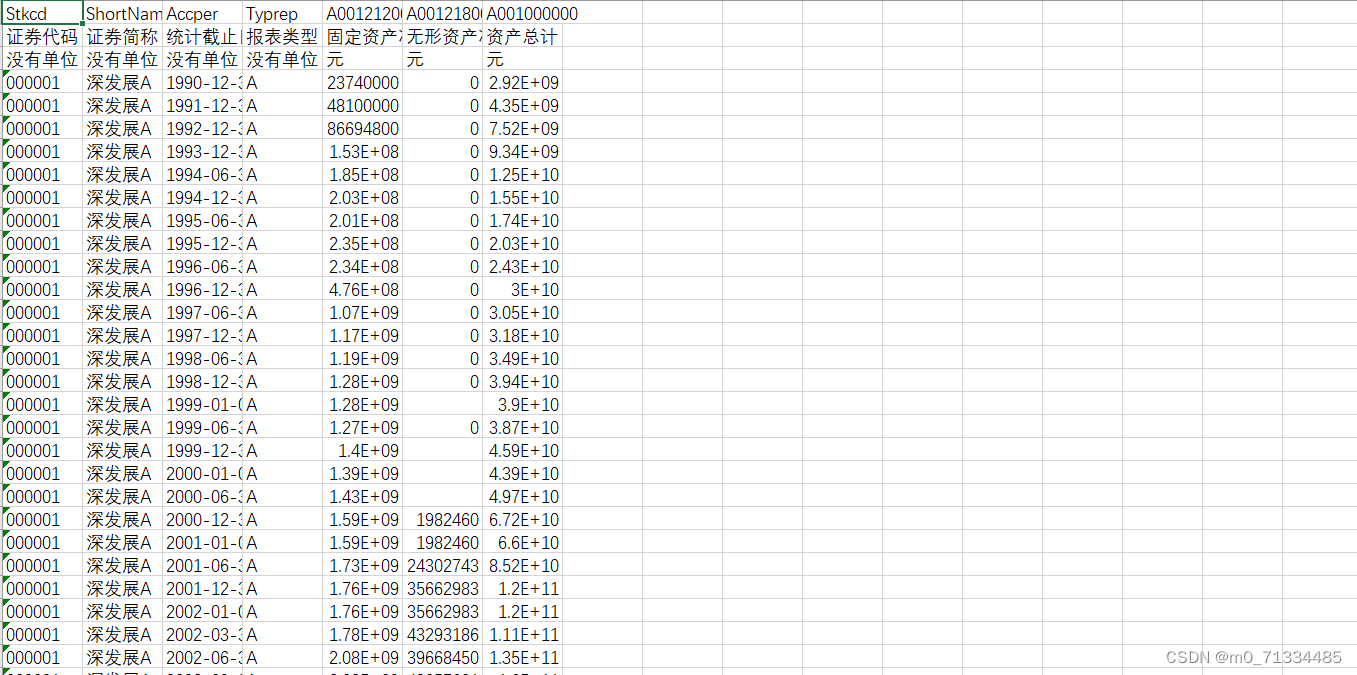
证券代码、统计截止日期、员工人数、证券简称、报表类型、固定资产净额、无形资产净额、资产总计、证券代码、证券简称、统计截止日期、报表类型、营业收入、销售费用、管理费用、报表类型、研发人员数量、研发人员数量占比(%) 研发投入金额、研发投入占营业收入比例(%) 研发投入(支出)费用化的金额、研发投入(支出)资本化的金额、资本化研发投入(支出)占研发投入的比例(%)、资本化研发投入(支出)占当期净利润的比重(%)、币种、说明、
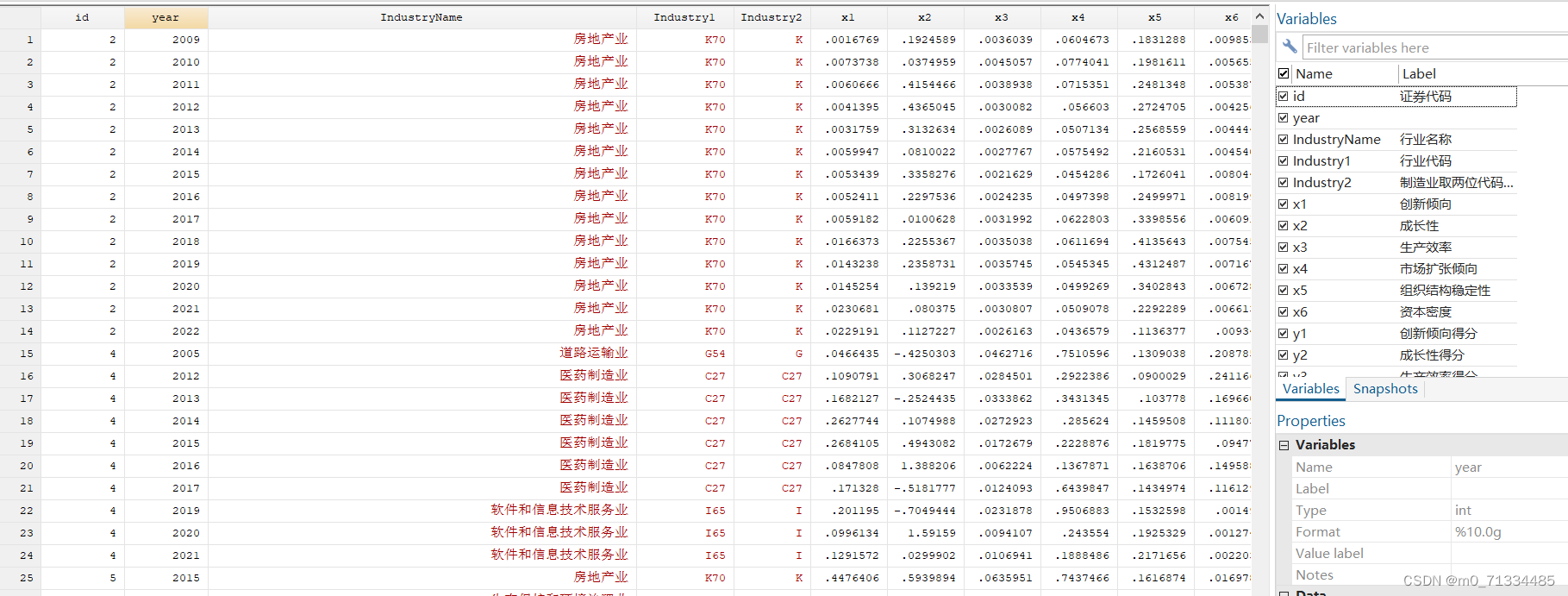
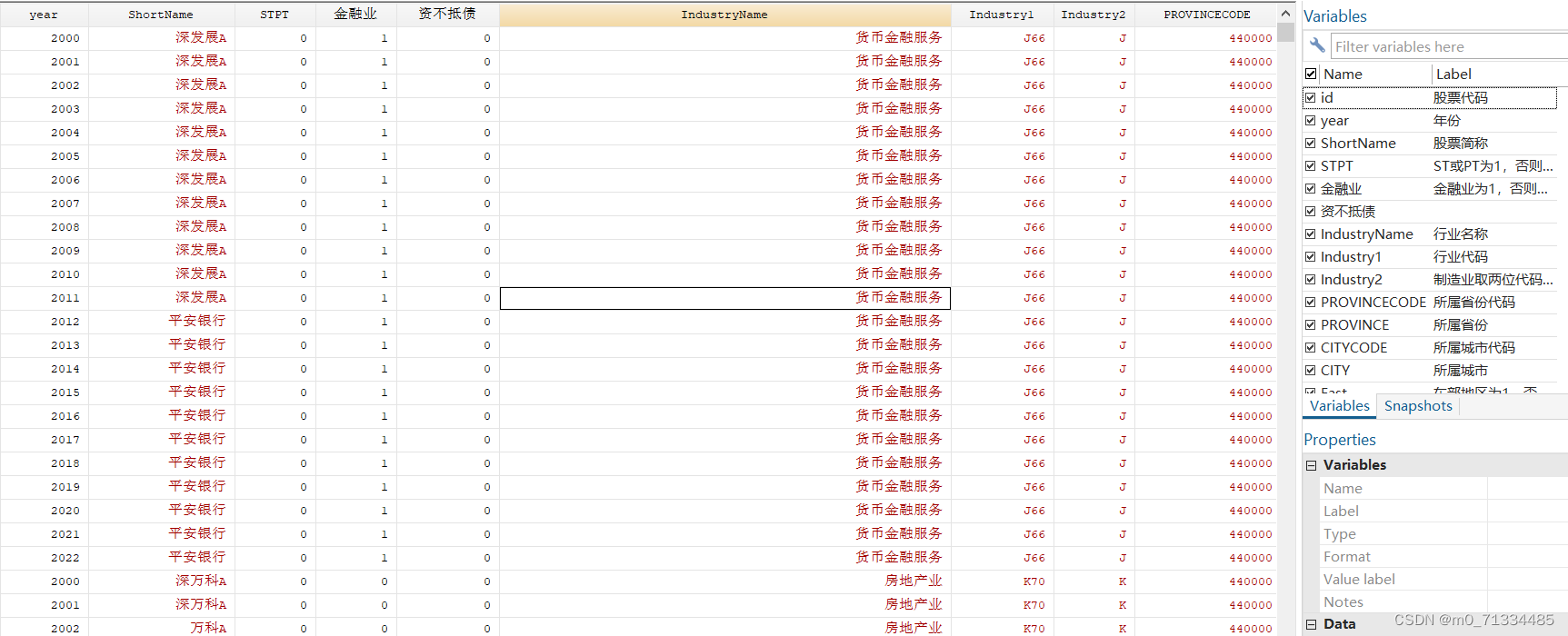
结果:证券代码、行业名称、行业代码、制造业取两位代码,其他行业用大类、创新倾向、成长性、生产效率、市场扩张倾向、组织结构稳定性、资本密度、创新倾向得分、成长性得分、生产效率得分、市场扩张倾向得分、组织结构稳定性得分、资本密度得分、企业战略激进度(值越大,战略越激进、企业战略、防御型企业战略、分析型企业战略、进攻型企业战略
4、范围:上市公司
5、样本量:3.2W+
6、参考文献:企业数字化程度对战略激进度的影响研究_王墨林
7、用途:可以用来衡量一家公司在一定时期内的业务扩张和风险承担程度。
8、下载链接:
2004-2022年上市公司企业战略激进度数据(含原始数据+计算代码+计算结果)![]() https://download.csdn.net/download/m0_71334485/89055773
https://download.csdn.net/download/m0_71334485/89055773
这篇关于2004-2022年上市公司企业战略激进度数据(含原始数据+计算代码+计算结果)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






