本文主要是介绍论文笔记:ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ICLR 2024 最终评分 55666
1 背景
- 文本评估通常需要大量的人力和时间成本
- 随着LLM的出现,研究人员探索了LLMs作为人工评估替代方案的潜力
- 基于单一代理的方法表现出潜力,但实验结果表明需要进一步的进展来弥合它们当前的有效性和人类级别的评估质量之间的差距
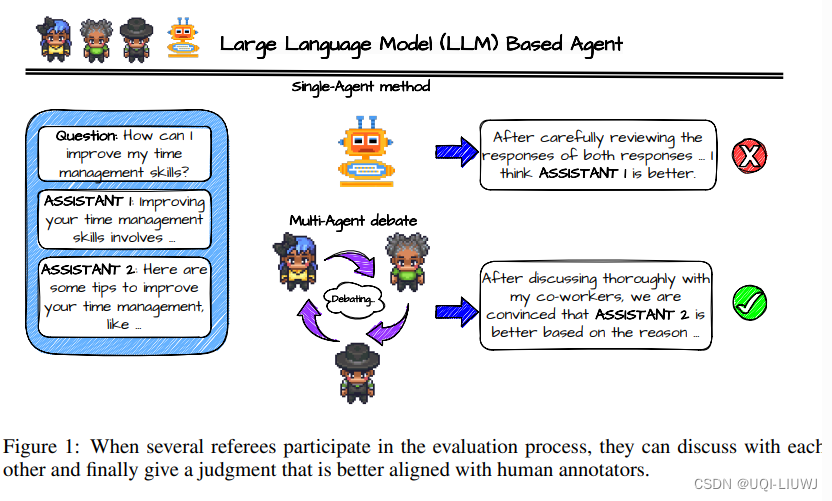
- ——>论文采用了多agent辩论框架
- 利用它们各自的能力和专业知识来提高处理复杂任务的效率和效果
- 构建了一个名为ChatEval的多agent裁判团队,允许每个agent使用不同的沟通策略进行协作讨论,以制定最终判断
- 为了丰富评估动态,ChatEval中的每个代理都赋予了独特的个性(persona)
- ——>确保每个代理专注于不同的视角或带来特定的专业知识。
- ——>通过这样做,集体评估从更全面的视角受益,捕捉单一视角可能忽略的细微差别
2 方法
- 将每个LLM视为一个agent,并要求它们从给定的prompt中生成response。
- 来自其他agent的response作为聊天历史记录,填入prompt template。

2.1 举例

2.2 沟通策略
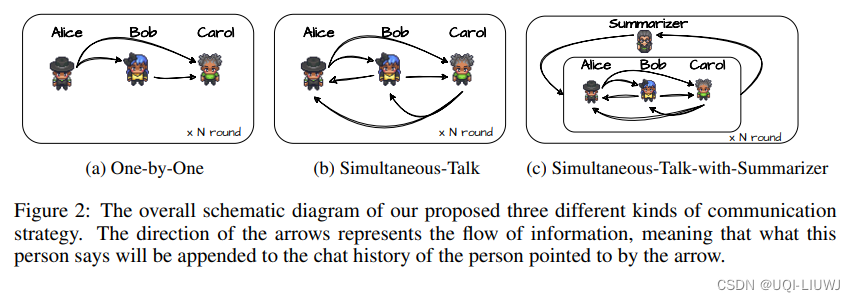
2.1.1 One-By-One
- 在每一轮的辩论中,agents轮流按照固定的顺序根据当前的观察产生他们的response。
- 当一个agent响应时,直接将之前其他agent所说的内容连接到它的聊天历史中。
2.1.2 Simultaneous-Talk
同时说话,即提示agent在每次讨论迭代中异步生成响应,以消除说话顺序的影响
2.1.3 Simultaneous-Talk-with-Summarizer
- 使用了另一个LLM作为总结器。
- 在辩论的每次迭代结束时,提示这个额外的LLM总结迄今为止所传达的信息,并将这个摘要送到所有辩手代理的聊天历史中。
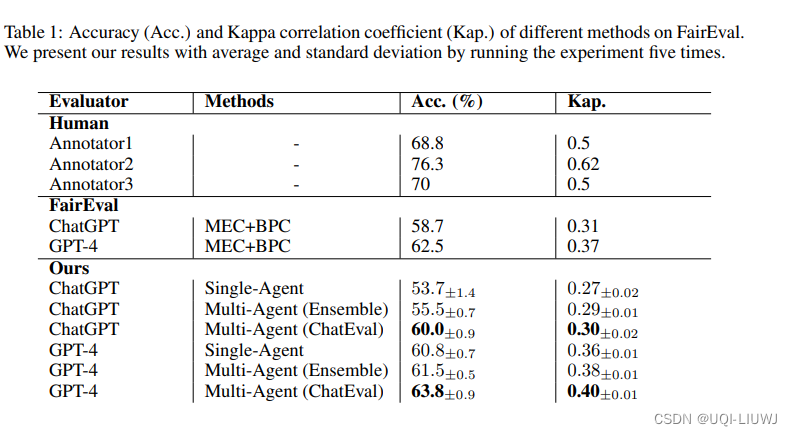
3 实验
3.1 效果
3.2 ablation study

这篇关于论文笔记:ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





