本文主要是介绍通过搜索引擎让大模型获取实时数据-实现类似 perplexity 的效果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、前言
- 二、初衷
- 三、实现方式
- 四、总结
一、前言
汇报一下这周末的工作,主要是开发了一门课程:通过搜索引擎让大模型获取实时数据,第一次开发一门课程,难免会有很多不熟悉和做的不好的地方。
已经训练好的大模型有气数据的局限性,比如 GPT-4,只有 2023年4月之前的数据。关于最新发生的一些事情,它无法回答。
 目前已经有一些公司在做类似的事情:让大模型获取最新数据,从而让用户得到更加满意的答案,比如 perplexity。
目前已经有一些公司在做类似的事情:让大模型获取最新数据,从而让用户得到更加满意的答案,比如 perplexity。
二、初衷
这门课其实就是简单解析 perplexity 的背后原理。perplexity 不知道有没有听说过,其估值或翻番至10亿美元
Perplexity AI 提供类似于 Google Search 和 Bing Search 的搜索服务,用户可以用自然语言输入问题,可以获得类似于 ChatGPT 的答案。
整体使用的效果是这样的:
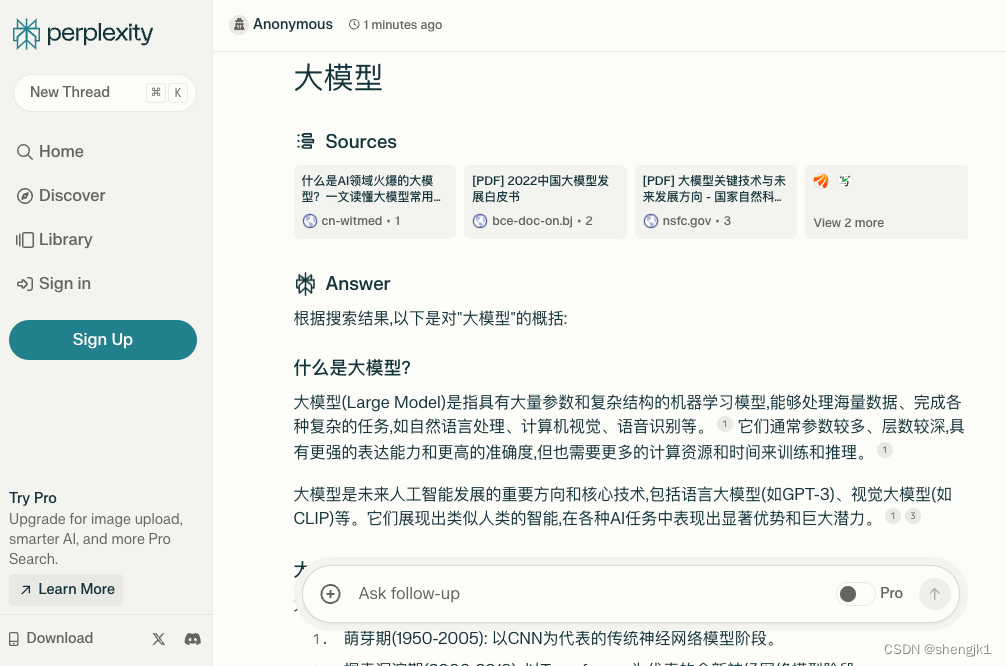 通过搜索引擎获取数据,然后通过大模型总结后进行回答。
通过搜索引擎获取数据,然后通过大模型总结后进行回答。
三、实现方式
搜索引擎+大模型,目前仅仅实现了后端,前段并没有做。当然了整体的效果肯定是不如 perplexity,毕竟 perplexity 有自己训练的大模型,以及要做自己的搜索引擎,另外我也没有进行任何优化。仅仅是探索 perplexity 背后的技术
四、总结
文章汇报了新开发的课程,主要涉及通过搜索引擎实现大模型获取实时数据的过程。初衷在于解析Perplexity的原理,作者介绍了该模型以及其提供的搜索服务。同时,作者也提及目前实现的局限性和技术探索的过程。
这篇关于通过搜索引擎让大模型获取实时数据-实现类似 perplexity 的效果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







