【ReadPapers】A Survey of Large Language Models
2024-03-30 19:52
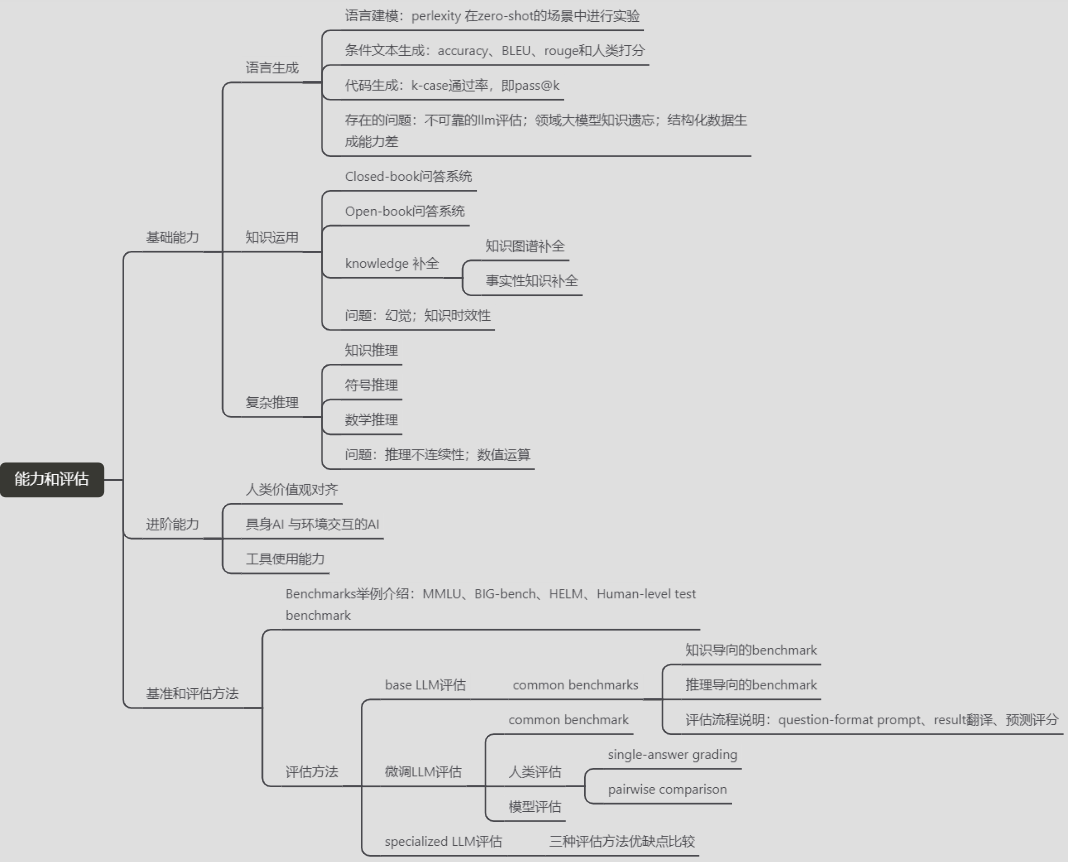
http://www.chinasem.cn/article/862425。
23002807@qq.com
相关文章

论文翻译:arxiv-2024 Benchmark Data Contamination of Large Language Models: A Survey
Benchmark Data Contamination of Large Language Models: A Survey https://arxiv.org/abs/2406.04244 大规模语言模型的基准数据污染:一项综述 文章目录 大规模语言模型的基准数据污染:一项综述摘要1 引言 摘要 大规模语言模型(LLMs),如GPT-4、Claude-3和Gemini的快

论文翻译:ICLR-2024 PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS
PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS https://openreview.net/forum?id=KS8mIvetg2 验证测试集污染在黑盒语言模型中 文章目录 验证测试集污染在黑盒语言模型中摘要1 引言 摘要 大型语言模型是在大量互联网数据上训练的,这引发了人们的担忧和猜测,即它们可能已

UML- 统一建模语言(Unified Modeling Language)创建项目的序列图及类图
陈科肇 ============= 1.主要模型 在UML系统开发中有三个主要的模型: 功能模型:从用户的角度展示系统的功能,包括用例图。 对象模型:采用对象、属性、操作、关联等概念展示系统的结构和基础,包括类图、对象图、包图。 动态模型:展现系统的内部行为。 包括序列图、活动图、状态图。 因为要创建个人空间项目并不是一个很大的项目,我这里只须关注两种图的创建就可以了,而在开始创建UML图

速通GPT-3:Language Models are Few-Shot Learners全文解读
文章目录 论文实验总览1. 任务设置与测试策略2. 任务类别3. 关键实验结果4. 数据污染与实验局限性5. 总结与贡献 Abstract1. 概括2. 具体分析3. 摘要全文翻译4. 为什么不需要梯度更新或微调⭐ Introduction1. 概括2. 具体分析3. 进一步分析 Approach1. 概括2. 具体分析3. 进一步分析 Results1. 概括2. 具体分析2.1 语言模型

高精度打表-Factoring Large Numbers
求斐波那契数,不打表的话会超时,打表的话普通的高精度开不出来那么大的数组,不如一个int存8位,特殊处理一下,具体看代码 #include<stdio.h>#include<string.h>#define MAX_SIZE 5005#define LEN 150#define to 100000000/*一个int存8位*/int num[MAX_SIZE][LEN];void
A Comprehensive Survey on Graph Neural Networks笔记
一、摘要-Abstract 1、传统的深度学习模型主要处理欧几里得数据(如图像、文本),而图神经网络的出现和发展是为了有效处理和学习非欧几里得域(即图结构数据)的信息。 2、将GNN划分为四类:recurrent GNNs(RecGNN), convolutional GNNs,(GCN), graph autoencoders(GAE), and spatial–temporal GNNs(S
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模
ModuleNotFoundError: No module named ‘diffusers.models.dual_transformer_2d‘解决方法
Python应用运行报错,部分错误信息如下: Traceback (most recent call last): File “\pipelines_ootd\unet_vton_2d_blocks.py”, line 29, in from diffusers.models.dual_transformer_2d import DualTransformer2DModel ModuleNotF
阅读笔记--Guiding Attention in End-to-End Driving Models
作者:Diego Porres1, Yi Xiao1, Gabriel Villalonga1, Alexandre Levy1, Antonio M. L ́ opez1,2 出版时间:arXiv:2405.00242v1 [cs.CV] 30 Apr 2024 这篇论文研究了如何引导基于视觉的端到端自动驾驶模型的注意力,以提高它们的驾驶质量和获得更直观的激活图。 摘 要 介绍

阅读笔记(四)NoSQL的选择指引《NoSQL database systems: a survey and decision guidance》
一. 前言 《NoSQL database systems: a survey and decision guidance》是一篇很好的综述类论文,详细的论述了NoSQL的特点和各种不同NoSQL数据库的选择依据。 传统的关系型数据库(relational database management systems ,RDBMSs)可以在保证一致性、可靠性、稳定性的前提下提供强有力的数据存储