本文主要是介绍JavaScript动态渲染页爬取——Playwright的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Playwright的使用
Playwright是微软在2020年年初开源的新一代自动化测试工具,其功能和Selenium、Pyppeteer等类似,都可以驱动浏览器进行各种自动化操作。Playwright对市面上的主流浏览器都提供了支持,API功能简洁又强大,虽然诞生比较晚,但是现在发展的非常火热。
1. Playwright的特点
- Playwright支持当前所有的主流浏览器,包括Chrome和Edge(基于Chromium)、Firefox、Safari(基于WebKit),提供完善的自动化控制API。
- Playwright支持移动端页面测试,使用设备模拟技术,可以让我们在移动Web浏览器中测试响应式Web应用程序。
- Playwright支持所有浏览器的无头模式和非无头模式的测试。
- Playwright的安装和配置过程非常简单,安装过程中会自动安装对应的浏览器和驱动,不需要额外配置WebDriver等
- Playwright提供和自动等待相关的API,在页面加载时会自动等待对应的节点加载,大大减小了API编写的复杂度。
2. 安装
命令如下:
pip3 install playwright
完成后需要进行一些初始化操作:
playwright install
这时Playwright会安装Chromium、Firefox和WebKit浏览器并配置一些驱动,我们不必关心具体的配置过程,Playwright会自动为我们配置好。
3. 基本使用
Playwright支持两种编写模式,一种是和Pyppeteer一样的异步模式,一种是和Selenium一样的同步模式,可以根据实际需要选择使用不同的模式。
先来看一个同步模式的例子:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:for browser_type in [p.chromium, p.firefox, p.webkit]:browser = browser_type.launch(headless=False)page = browser.new_page()page.goto('<https://www.baidu.com>')page.screenshot(path=f'screenshot-{browser_type.name}.png')print(page.title())browser.close()
注意:如果不把headless参数设置为False,就会以默认的无头模式启动浏览器,我们将看不到任何窗口。
这里我们首先导入并直接调用了sync_playwright方法,该方法的返回值是一个PlaywrightContextManager对象,可以理解为一个浏览器上下文管理器,我们将其赋值为p变量。然后依次调用p的Chromium、firefox和webkit属性创建了Chromium、Firefox以及Webkit浏览器实例。接着用一个for循环依次执行了这3个浏览器的launch方法,同时设置headless参数为False。运行一下这段代码,可以看到有3个浏览器依次启动,分别是Chromium、Firefox和Webkit浏览器,启动后都是加载百度首页,页面加载后,生成页面截图,然后把页面标题打印到控制台,就退出了。
控制台的运行结果如下:
百度一下,你就知道
百度一下,你就知道
百度一下,你就知道
可以发现,我们非常方便地启动了三种浏览器,完成了自动化操作,并通过几个API获取了页面的截图和数据,整个过程速度非常快,这就是Playwright最为基本的用法。
当然,除了同步模式,Playwright还提供了支持异步模式的API, 如果我们的项目里面使用了asyncio关键字,就应该使用异步模式,写法如下:
from playwright.async_api import async_playwright
import asyncioasync def main():async with async_playwright() as p:for browser_type in [p.chromium, p.firefox, p.webkit]:browser = await browser_type.launch()page = await browser.new_page()await page.goto('<https://www.baidu.com>')await page.screenshot(path=f'screenshot-{browser_type.name}.png')print(await page.title())await browser.close()asyncio.run(main())
写法和同步模式基本一样,只不过是这里导入的是async_playwright方法,不再是sync_playwright方法,以及写法上添加了async/await 关键字,最后的运行效果和同步模式是一样的。
4. 代码生成
Playwright还有一个强大的功能,可以录制我们在浏览器中操作并自动生成代码,有了这个功能,我们甚至一行代码都不用写。这个功能可以通过playwright命令行调用codegen实现,先来看看codegen命令都有什么参数,输入如下命令:
playwright codegen --help
结果类似如下:
Usage: playwright codegen [options] [url]open page and generate code for user actionsOptions:-o, --output <file name> saves the generated script to a file--target <language> language to generate, one of javascript,playwright-test, python, python-async,python-pytest, csharp, csharp-mstest,csharp-nunit, java, java-junit (default:"python")--save-trace <filename> record a trace for the session and saveit to a file--test-id-attribute <attributeName> use the specified attribute to generatedata test ID selectors-b, --browser <browserType> browser to use, one of cr, chromium, ff,firefox, wk, webkit (default:"chromium")--block-service-workers block service workers--channel <channel> Chromium distribution channel, "chrome","chrome-beta", "msedge-dev", etc--color-scheme <scheme> emulate preferred color scheme, "light"or "dark"--device <deviceName> emulate device, for example "iPhone 11"--geolocation <coordinates> specify geolocation coordinates, forexample "37.819722,-122.478611"--ignore-https-errors ignore https errors--load-storage <filename> load context storage state from thefile, previously saved with--save-storage--lang <language> specify language / locale, for example"en-GB"--proxy-server <proxy> specify proxy server, for example"<http://myproxy:3128>" or"socks5://myproxy:8080"--proxy-bypass <bypass> comma-separated domains to bypass proxy,for example".com,chromium.org,.domain.com"--save-har <filename> save HAR file with all network activityat the end--save-har-glob <glob pattern> filter entries in the HAR by matchingurl against this glob pattern--save-storage <filename> save context storage state at the end,for later use with --load-storage--timezone <time zone> time zone to emulate, for example"Europe/Rome"--timeout <timeout> timeout for Playwright actions inmilliseconds, no timeout by default--user-agent <ua string> specify user agent string--viewport-size <size> specify browser viewport size in pixels,for example "1280, 720"-h, --help display help for commandExamples:$ codegen$ codegen --target=python$ codegen -b webkit <https://example.com>
可以看到结果中有个选项,-o代表输出的代码文件的名称;-target代表使用的语言,默认是python,代表会生成同步模式的操作代码。
了解这些用法后,我们来尝试启动一个Firefox浏览器,然后将操作结果输出到script.py文件,命令如下:
playwright codegen -o script.py -b firefox
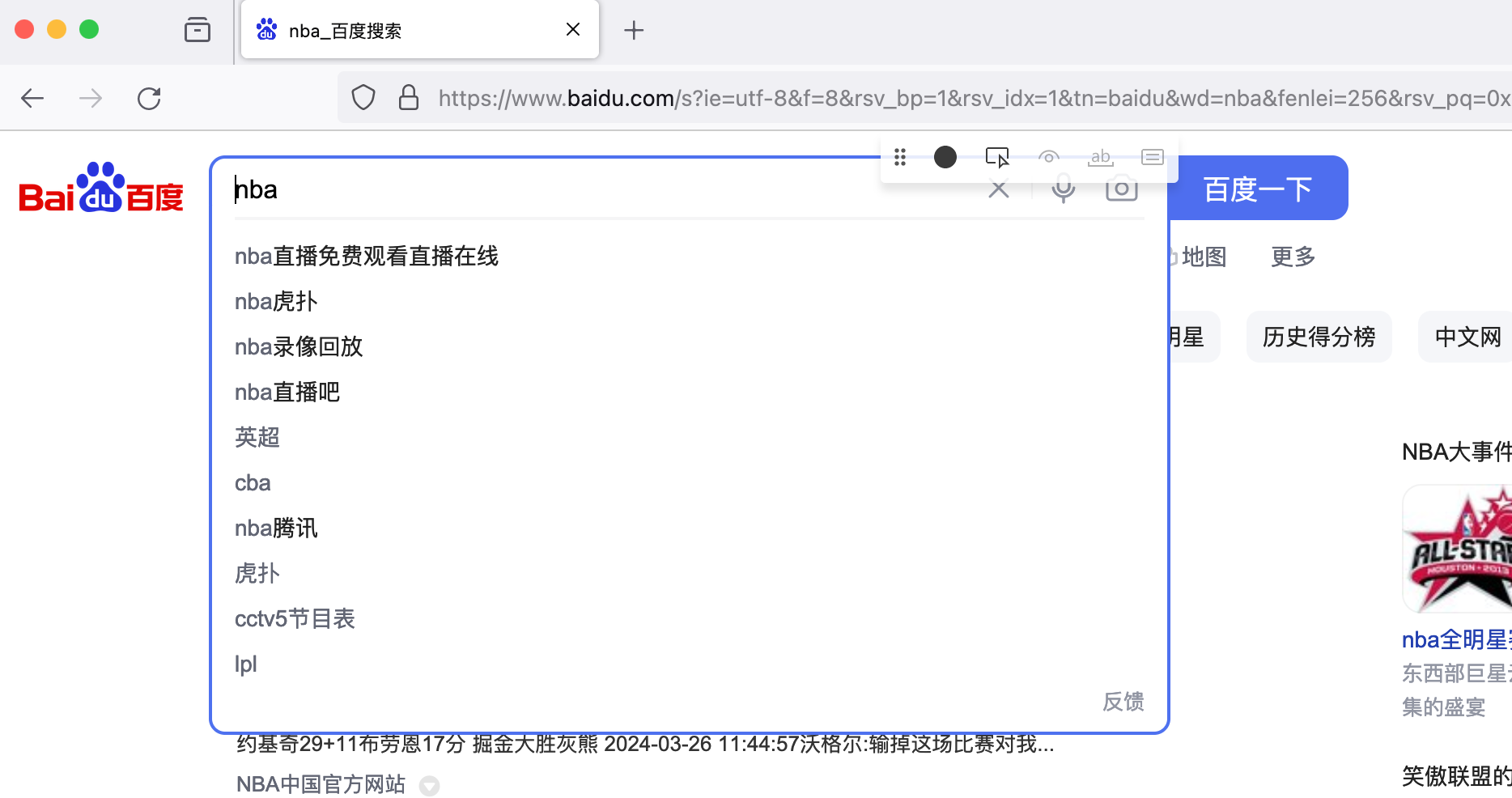
可以看到,浏览器中会高亮显示我们正在操作的页面节点,同时显示对应的选择器字符串 page.locator(“#kw”).fill(“nba”),右侧代码窗口如下图:
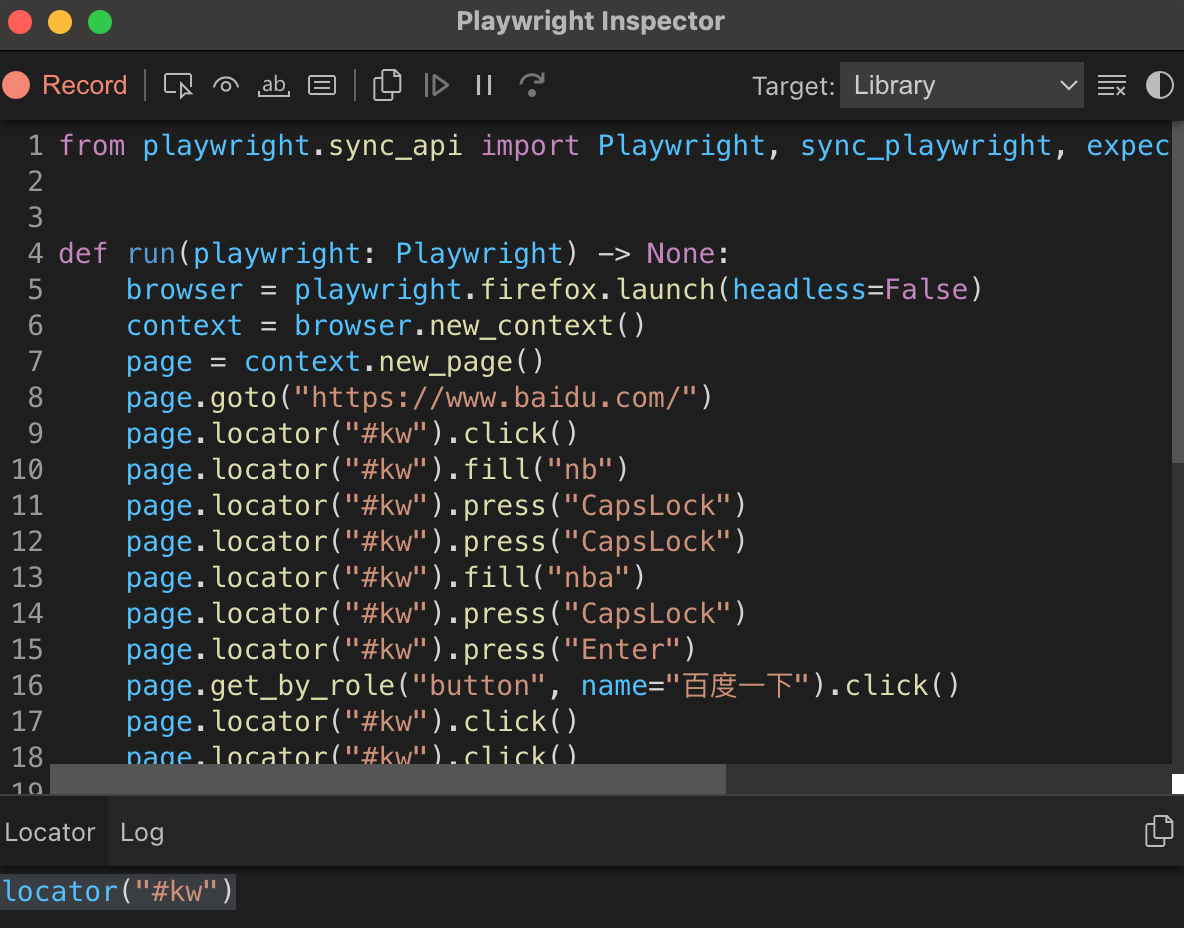
在操作浏览器的过程中,该窗口中的代码会跟着实时变化,现在这里已经生成了刚刚一系列操作对应的代码,例如:
page.locator("#kw").fill("nba")
这行代码就对应在搜索框中输入nba的操作,所有操作完毕之后,关闭浏览器,Playwright会生成一个script.py文件,内容如下:
from playwright.sync_api import Playwright, sync_playwright, expectdef run(playwright: Playwright) -> None:browser = playwright.firefox.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("<https://www.baidu.com/>")page.locator("#kw").click()page.locator("#kw").press("CapsLock")page.locator("#kw").fill("nba")# ---------------------context.close()browser.close()with sync_playwright() as playwright:run(playwright)
可以看到这里生成的代码和我们之前写的示例代码几乎差不多,而且也可以运行,运行之后会看到它在浮现我们刚才所做的操作。所以,有了代码生成功能,只通过简单的可视化点击操作就能生成代码,可谓非常方便。
5. 支持移动端浏览器
Playwright的另一个特色就是支持模拟移动端浏览器,例如模拟打开iPhone12 Pro Max上的Safari浏览器。
示例代码如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:iphone_12_pro_max = p.devices['iPhone 12 Pro Max']browser = p.webkit.launch(headless=False)context = browser.new_context(**iphone_12_pro_max, locale='zh-CN')page = context.new_page()page.goto('<https://www.whatismybrowser.com/>')page.wait_for_load_state(state='networkidle')page.screenshot(path='browser-iphone.png')browser.close()
这里我们先用PlaywrightContextManager对象的devices属性指定了一台移动设备,传入的参数是移动设备的型号,例如iPhone 12 Pro Max,当然也可以传入其他内容,例如iPhone 8、Pixel 2等。
运行一下代码,可以发现弹出了一个移动版浏览器,然后加载出了对应的页面,如下图所示:
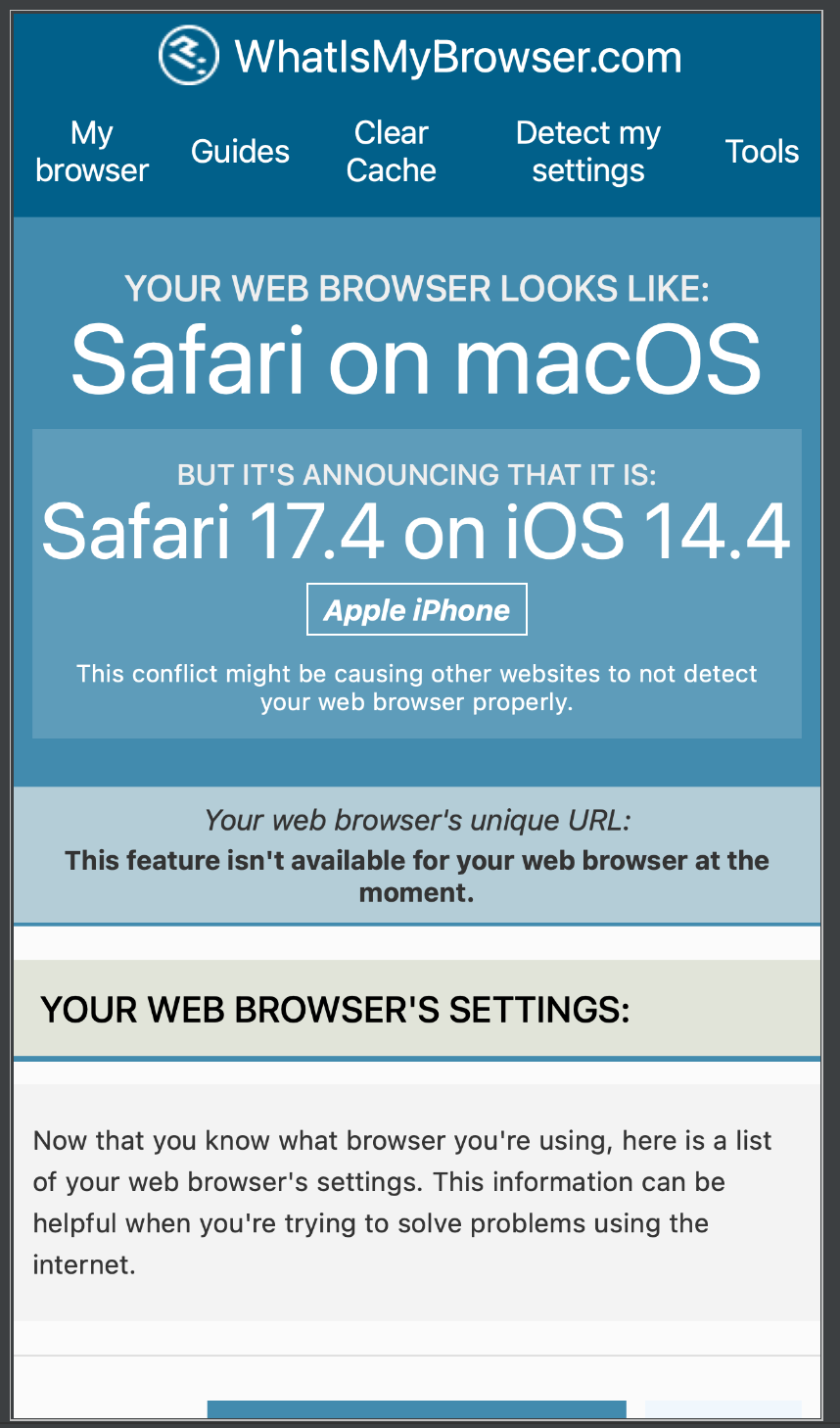
输出的截图也是浏览器中显示的结果,可以看到,这里显示的浏览器信息是iPhone上的Safari浏览器。也就是我们成功模拟了一个移动端浏览器。
6. 选择器
Playwright扩展了方便好用的规则,直接根据文本内容筛选、根据节点层级结构筛选等。
- 文本选择
文本选择支持直接使用text=这样的语法进行筛选,示例如下:
page.click("text=Log in")
- CSS选择器
根据id或class筛选:
page.click("button")
page.click("#nav-bar .contact-us-item")
根据特定的节点属性筛选:
page.click("[data-test=login-button]")
page.click("[aria-label='Sign in']")
- CSS选择器+文本值
可以使用CSS选择器结合文本值的方式进行筛选,比较常用的方法是has-text和text,前者代表节点中包含指定的字符串,后者代表节点中的文本值和指定的字符串完全匹配,示例如下:
page.click("article:has-text('Playwright')")
page.click("#nav-bar :text('Contact us')")
第一行代码就是选择文本值中包含Playwright字符串的article节点,第二行代码是选择id为nav-bar的节点中文本值为Contact us的节点。
- CSS选择器 + 节点关系
CSS选择器还可以结合节点关系来筛选节点,例如使用has指定另外一个选择器,示例如下:
page.click(".item-description:has(.item-promo-banner")
- XPath
当然,XPath也是支持的,不过xpath这个关键字需要我们自行指定,示例如下:
page.click("xpath=//button")
这里在开头指定“xpath=字符串”,代表这个字符串是一个XPath表达式。
7. 常用的操作方法
所有的方法都可以从Page对象的API文档查找,文档地址是https://playwright.dev/python/docs/api/class-page。
- 事件监听
Page对象提供一个on方法,用来监听页面中发送的各个事件,例如close、console、load、request、response等。
这里监听reponse事件,在每次网络请求得到响应的时候会出发这个事件,我们可以设置回调方法来获取响应中的全部信息,示例如下:
from playwright.sync_api import sync_playwrightdef on_response(response):print(f'Statue {response.status}: {response.url}')with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.on('response', on_response)page.goto('<https://spa6.scrape.center/>')page.wait_for_load_state('networkidle')browser.close()
创建Page对象后,开始监听response事件,同时将回调方法设置为on_response,on_response接收一个参数,然后输出响应中的状态码和链接。
运行上述代码后,可以看到控制台输出如下结果:
Statue 200: <https://spa6.scrape.center/>
Statue 200: <https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css>
Statue 200: <https://spa6.scrape.center/css/app.ea9d802a.css>
Statue 200: <https://spa6.scrape.center/js/chunk-vendors.77daf991.js>
Statue 200: <https://spa6.scrape.center/js/app.5ef0d454.js>
Statue 200: <https://spa6.scrape.center/js/chunk-2f73b8f3.8f2fc3cd.js>
....
....
Statue 200: <https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa7e187c3df767253.jpg@464w_644h_1e_1c>
Statue 200: <https://p0.meituan.net/movie/289f98ceaa8a0ae737d3dc01cd05ab052213631.jpg@464w_644h_1e_1c>
Statue 200: <https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c>
Statue 200: <https://p0.meituan.net/movie/223c3e186db3ab4ea3bb14508c709400427933.jpg@464w_644h_1e_1c>
Statue 200: <https://p1.meituan.net/movie/b607fba7513e7f15eab170aac1e1400d878112.jpg@464w_644h_1e_1c>
Statue 200: <https://p0.meituan.net/movie/8959888ee0c399b0fe53a714bc8a5a17460048.jpg@464w_644h_1e_1c>
Statue 200: <https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e1438406.jpg@464w_644h_1e_1c>
可以发现,这个输出结果其实正好对应浏览器Network面板中的所有请求和响应,和下图的内容一一对应。
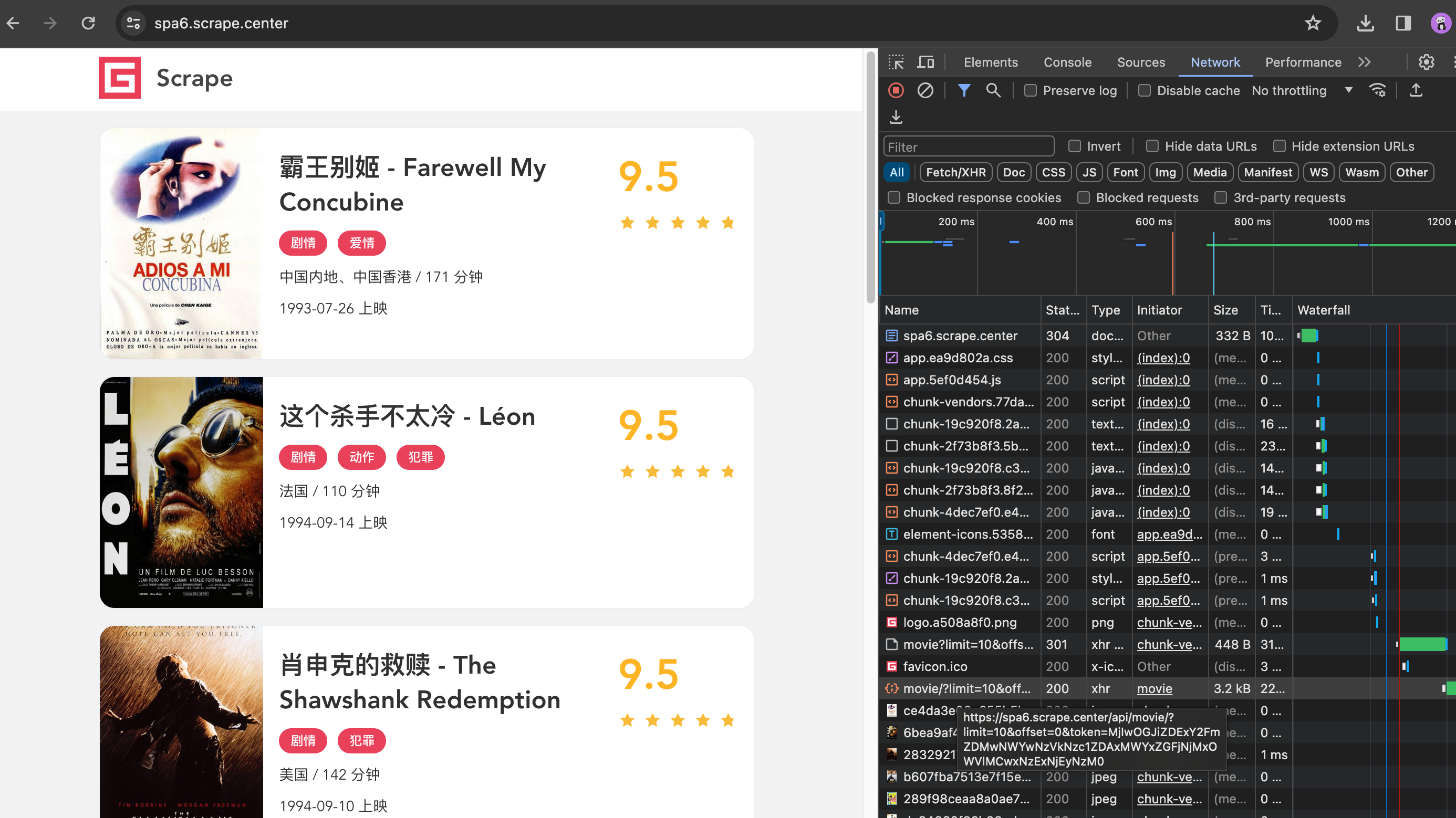
这个网站,真实数据都是Ajax加载的,同时Ajax请求中还带有加密参数,不好轻易获取。但有了on_response方法,如果我们想截获Ajax请求,岂不是就非常容易了?改写一下这里的判定条件,输出对应的JSON的结果,代码如下:
from playwright.sync_api import sync_playwrightdef on_response(response):if '/api/movie/' in response.url and response.status == 200:print(response.json())with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.on('response', on_response)page.goto('<https://spa6.scrape.center/>')page.wait_for_load_state('networkidle')browser.close()
控制台的输出结果如下:
{'count': 102, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine', 'cover': '<https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@_644h_1e_1c>',
'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'minute': 171, 'score': 9.5, 'regions': ['中国内地', '中国香港']}, {'id': 2, 'name': '这个杀手不on', 'cover': '<https://p1.meituan.net/movie/6bea9af4524dfbd0b6>....
113e174332.jpg@464w1e_1c', 'categories': ['剧情', '喜剧', '爱情'], 'published_at': '1999-02-13', 'minute': 85, 'score': 9.5, 'regions': ['中国香港']}, {'id': 9, 'name': '楚门的世界', 'alias':ow', 'cover': '<https://p0.meituan.net/movie/8959888ee0c399b0fe53a714bc8a5a17460048.jpg@464w_644h_1e_1c>', 'categories': ['剧情', '科幻'], 'published_at': None, 'minute': 103core': 9.0, 'regions': ['美国']}, {'id': 10, 'name': '狮子王', 'alias': 'The Lion King', 'cover': '<https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e1438406.jpg@644h_1e_1c>', 'categories': ['动画', '歌舞', '冒险'], 'published_at': '1995-07-15', 'minute': 89, 'score': 9.0, 'regions': ['美国']}]}
通过on_response方法拦截了Ajax请求,直接拿到了响应结果,即使这个Ajax请求中有加密参数,也不用担心,因为我们截获的是最后的响应结果。
- 获取页面源代码
获取页面源代码的过程其实很简单,直接调用Page对象的content方法就行,用法如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto('<https://spa6.scrape.center>')page.wait_for_load_state('networkidle')html = page.content()print(html)browser.close()
运行结果就是页面源代码,获取了页面源代码之后,借助一些解析工具就可以提取想要的信息了。
- 页面点击
实现页面点击的方法,就是click方法。click方法的API定义如下:
page.click(selector, **kwargs)
必须传入的参数是selector,其他参数都是可选的。selector代表选择器,用来匹配想要点击的节点,如果有多个节点和传入的选择器相匹配,那么只使用第一个节点。
- 文本输入
文本输入对应的方法是fill,其API定义如下:
page.fill(selector, value, **kwargs)
这个方法有两个必传参数,第一个也是selector,依然代表选择器;第二个是value,代表输入的文本内容;
- 获取节点属性
除了操作节点本身,我们还可以获取节点的属性,方法是get_attribute,其API定义如下:
page.get_attribute(selector, name, **kwargs)
两个必传参数,第一个还是selector,第二个是name,代表要获取的属性的名称;还可以通过timeout参数指定查找对应节点的最长等待时间。示例如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto('<https://spa6.scrape.center/>')page.wait_for_load_state('networkidle')href = page.get_attribute('a.name', 'href')print(href)browser.close()
调用get_attribute方法,传入的selector参数值是a.name,代表查找class为name的a节点,name参数值传入了href,代表获取链接的内容,输出结果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
- 获取多个节点
使用query_selector_all方法可以获取所有节点,它会返回节点列表,通过遍历得到其中的单个节点后,可以接着调用上面介绍的针对单个节点的方法完成一些操作和获取属性,示例如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto('<https://spa6.scrape.center/>')page.wait_for_load_state('networkidle')elements = page.query_selector_all('a.name')for element in elements:print(element.get_attribute('href'))print(element.text_content())browser.close()
这里通过query_selector_all方法获取了所有匹配到的节点,每个节点各对应一个ElementHandle对象,可以调用ElementHandle对象的get_attribute方法获取节点属性,也可以通过text_content方法获取节点文本。
运行结果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
霸王别姬 - Farewell My Concubine
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIy
这个杀手不太冷 - Léon
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIz
.......
乱世佳人 - Gone with the Wind
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI4
喜剧之王 - The King of Comedy
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI5
楚门的世界 - The Truman Show
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIxMA==
狮子王 - The Lion King
- 获取单个节点
获取单个节点也有特定的方法,就是query_selector,如果传入的选择器匹配到多个节点,那它只会返回第一个,示例如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto('<https://spa6.scrape.center/>')page.wait_for_load_state('networkidle')element = page.query_selector('a.name')print(element.get_attribute('href'))print(element.text_content())browser.close()
运行结果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
霸王别姬 - Farewell My Concubine
- 网络劫持
实用方法——route,利用这个方法可以实现网络劫持和修改操作,例如修改request的属性,修改响应结果等,示例如下:
from playwright.sync_api import sync_playwright
import rewith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()def cancel_request(route, request):route.abort()page.route(re.compile(r"(\\.png)|(\\.jpg)"), cancel_request)page.goto('<https://spa6.scrape.center/>')page.wait_for_load_state('networkidle')page.screenshot(path='no_picture.png')browser.close()
这里调用了route方法,第一个参数通过正则表达式传入了URL路径,这里的(.png)| (.jpg)代表所有包含.png或.jpg的链接,遇到这样的请求,会回调cancle_request方法做处理。cancel_request方法接收两个参数,一个是route,代表一个CallalbeRoute对象;另一个是request,代表Request对象。这里我们直接调用CallableRoute对象的abort方法,取消了这次请求,导致最终的结果如是取消全部图片的加载。
运行结果如下图,可以看到图片全都加载失败了。
这个设置看起来没什么用啊?其实是有用的,图片资源都是二进制文件,我们在爬取过程中可能并不想关心具体的二进制文件的内容,而只关系图片的URL是什么,所以浏览器中是否把图片加载出来就不重要了,如此设置可以提高整个页面的加载速度,提高爬取效率。
利用这个功能,还可以对一些响应内容进行修改,例如直接将响应结果修改为自定义的文本内容。这里首先定一个HTML文本文件,命名为custom_response.html,内容如下:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Hack Response</title>
</head>
<body><h1>Hack Response</h1>
</body>
</html>
代码编写如下:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()def modify_response(route, request):route.fulfill(path="./custom_response.html")page.route('**/*', modify_response)page.goto("<https://spa6.scrape.center/>")time.sleep(10)browser.close()
这里我们使用CallableRoute对象的fulfill方法指定了一个本地文件,就是刚才我们定义的HTML文件,运行结果如图所示:
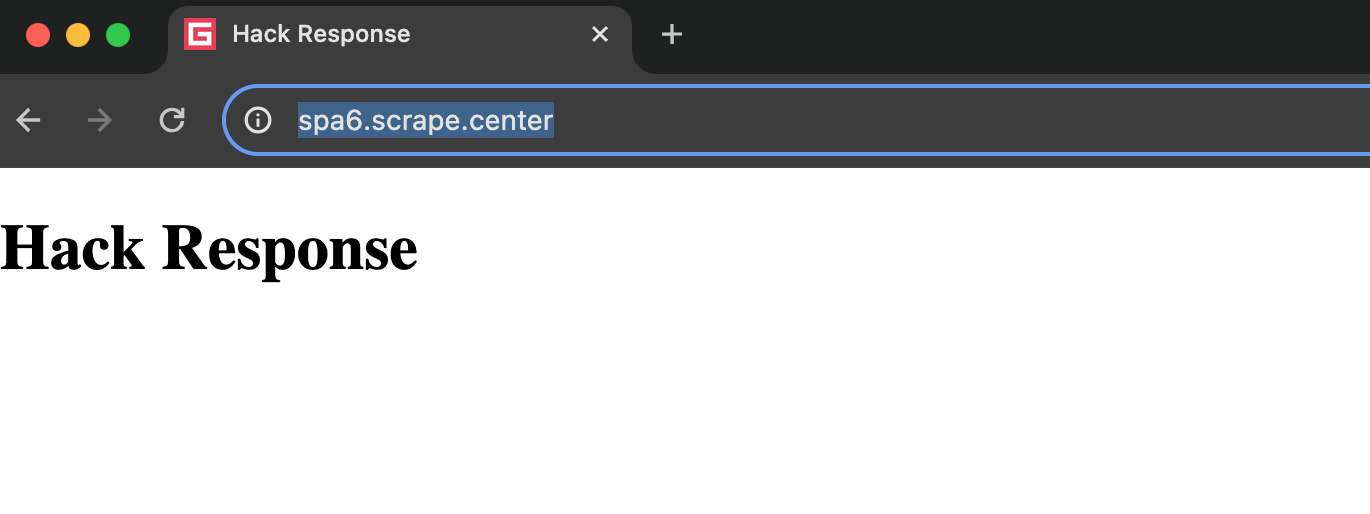
可以看到,响应结果已经被我们修改了,URL依然不变,但结果已经变成我们修改后的HTML代码。所以通过route方法,可以灵活地控制请求和响应的内容,从而在某些场景下达成某些目的。
获取更多体验可以访问[小蜜蜂AI][https://zglg.work]
这篇关于JavaScript动态渲染页爬取——Playwright的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





