本文主要是介绍论文笔记——Fully Convolutional Networks for Semantic Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 Abstract
- 2 Introduction
- 3 Related work
- 3.1 Fully convolutional network
- 3.2 Dense prediction with convnet
- 4 Fully convolutional networks
- 4.1 Adapting classifiers for dense prediction
- 4.2 Shift-and-stitch is filter rarefaction
- 4.3 Upsampling is backwards strided convolution
- 5 Segmentation Architecture
- 5.1 From classifier to dense FCN
- 5.2 Combine what and where
- 5.3 Experimental framework
- Optimization
- Fine-tuning
- More Training Data
- Patch Sampling
- Class Balancing
- Dense Prediction
- Augmentation
- Implementation
- 6 Results
- Metrics
- PASCAL VOC
- NYUDv2
- SIFT FLOW
- 7 Conclusion
1 Abstract
- 构建全卷积神经网络,可以接受任意大小的输入并输出相应大小的输出
- 详细解释了FCN在稠密预测任务中的应用,并和之前的模型进行了对比
- 改编了分类网络:AlexNet、VGG、GooLeNet
- 定义了一个跳跃连接将深层的粗糙的语义信息与浅层的细致的外观信息结合起来以产生精确的、详细的分割。
- 在分割数据集PASCAL VOC上取得了最先进的精确
2 Introduction
- FCN的方法是高效的,不需要其他工作中的一些复杂方法
- 全局信息决定是什么,局部信息决定在哪(定义了一个跳跃连接将深层的粗糙的语义信息与浅层的细致的外观信息结合起来以产生精确的、详细的分割。)
3 Related work
方法基于深度分类网路和迁移学习的最新成功
3.1 Fully convolutional network
- Matan等人首先提出将卷积网络扩展到任意大小的输入
- FCN以前的应用:
Sermanet等人的滑动窗口预测
Pinheiro 和 Collobert 的语义分割,
Eign等人的图像修复
Tomspon等人有效的使用全卷积神经网络进行了像素到像素的训练- He等人扔掉了分类网络的非卷积部分来制作一个特征提取器
3.2 Dense prediction with convnet
- 几个最近的应用卷积网络进行稠密预测的工作
Ning et al., Farabet et al., and Pinheiro and Collobert 等人的语义分割
Ciresan et al.的电子显微镜的成像的边界预测
Ganin and Lempitsky 的 natural images by a hybrid convnet/nearest neighbor model
Eigen et al.的图像修复和深度估计
- 这些方法的共同原理
小模型限制了能力和接收域
patchwise训练
通过超像素投影、随机场正则化、滤波或局部分类进行后处理
进行输入移位和输出偏移来达到稠密输出
多尺度金字塔处理
饱和tanh非线性
ensembles
- FCN模型
没有使用这些机制,
研究patchwise训练和"shift-and-stitch"稠密输出
改变深度分类架构,使用图像分类进行监督的
微调全卷积
4 Fully convolutional networks
理解平移不变形见:https://www.cnblogs.com/Terrypython/p/11147490.html
感受野
卷积网络的平移不变形
实数损失函数
4.1 Adapting classifiers for dense prediction
把全连接层改成卷积层
4.2 Shift-and-stitch is filter rarefaction
理解shift-and-stitch借用这篇博客:https://www.jianshu.com/p/e534e2be5d7d
4.3 Upsampling is backwards strided convolution
5 Segmentation Architecture
训练和交叉验证集用的是PASCAL VOC 2011分割挑战赛
损失函数是逐像素的多项式逻辑损失(per-pixel multinomial logistic loss)
交叉验证用的是mean pixel intersection over union,其中均值来自于所有类别,包括背景
训练中忽略的像素被从真值中mask out(有歧义或者困难)
5.1 From classifier to dense FCN
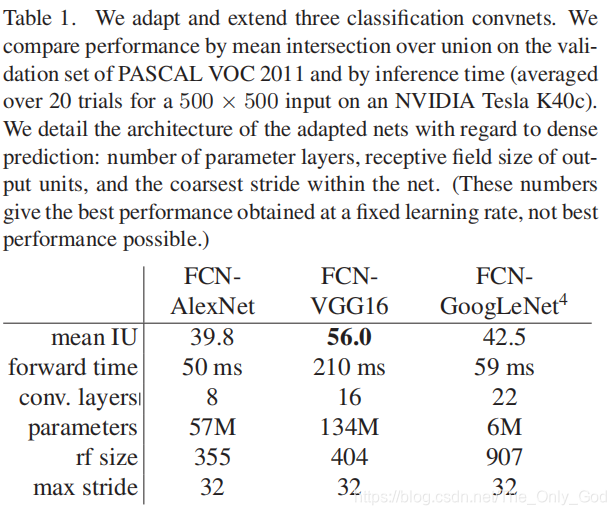
改造了三个分类网络:AlexNet、VGG-16、GooLeNet(只用了最后的损失层,并通过丢弃最后的平均池化层实现了效果的提升)
改造方法:将这些网络最后的分类层去掉,用卷积层替代所有的全连接层。用1X1卷积(通道数21)来预测所有coarse output中在PASCAL上对应的每个类别(包括背景),再用deconvolution layer对coarse outputs进行双线性上采样实现像素级稠密估计
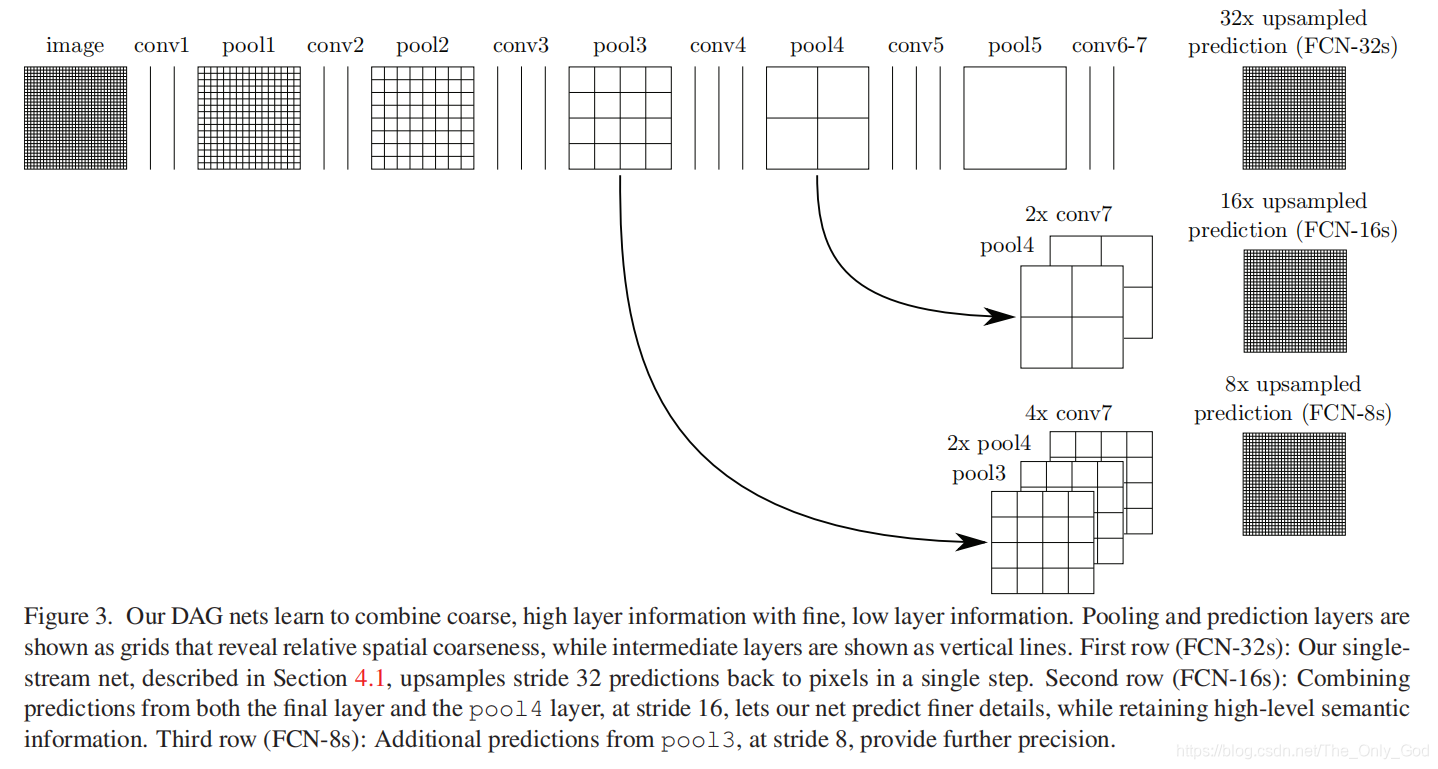
5.2 Combine what and where
对原图像进行卷积conv1、pool1后原图像缩小为1/2;
之后对图像进行第二次conv2、pool2后图像缩小为1/4;
接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;
接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;
最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时进行32倍的上采样可以得到原图大小,这个时候得到的结果就是叫做FCN-32s.
在FCN-32s的基础上进行fine tuning,把pool4层和conv7的2倍上采样结果相加之后进行一个16倍的上采样,得到的结果是FCN-16s.
之后在FCN-16s的基础上进行fine tuning,把pool3层和2倍上采样的pool4层和4倍上采样的conv7层加起来,进行一个8倍的上采样,得到的结果就是FCN-8s.
参考:https://blog.csdn.net/ztsucceed/article/details/80564113

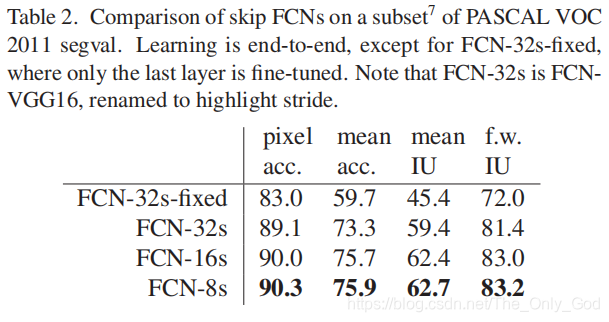
5.3 Experimental framework
Optimization
SGD with momentum
minibatch size of 20 images
fixed learning rates
Fine-tuning
More Training Data
Patch Sampling
Class Balancing
Dense Prediction
Augmentation
尝试通过随机镜像和将图像各个维度jittering至最高32像素(相对于coarse scale of prediction)来扩张输入,但是这个操作没有带来明显提升。
Implementation
6 Results
在PASCAL VOC,NYUDv2和SIFT Flow上进行了测试
Metrics

PASCAL VOC

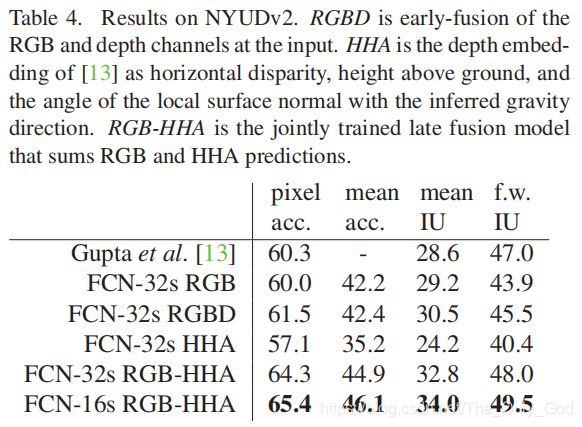
NYUDv2
SIFT FLOW

7 Conclusion
Recognizing this extending these classification nets to segmentation, and improving the architecture with multi-resolution layer combinations dramatically improves the state-of-the-art, while simultaneously simplifying and speeding up learning and inference

这篇关于论文笔记——Fully Convolutional Networks for Semantic Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







