本文主要是介绍ElasticSearch学习篇11_ANNS之基于图的NSW、HNSW算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
往期博客ElasticSearch学习篇9_文本相似度计算方法现状以及基于改进的 Jaccard 算法代码实现与效果测评_elasticsearch 文字相似度实现方法-CSDN博客 根据论文对文本相似搜索现状做了一个简要总结,然后对论文提到的改进杰卡德算法做了实现,并结合业务场景测评,另外对其他两种改进杰卡德算法做了测评总结适用的业务场景。
面对多维数据,空间紧邻搜索被应用在多种场景的检索需求,如人脸识别、图片搜索、商品的推荐搜索等。如何高效的从海量数据中紧邻搜索热点数据是某些搜索业务场景所要求的,下面是学术界常用的用在空间紧邻搜索的四种算法思想,在此基础上也衍生的很多工业界针对不同业务场景的开源检索算法入ANNOY、faiss、QSG-NGT等
而Lucene和ES使用的多维数据紧邻搜索是改进的BKD以及HNSW,Lucene从6.0版本引入了BKD,关于BKD原理参考往期博客,该BKD结构就是基于空间分割算法。Elasticsearch从8.0版本开始引入了向量近邻检索k-nearest neighbor(kNN)search功能,该功能支持使用HNSW(Hierarchical Navigable Small World)算法来优化向量检索的性能。下面主要了解相关算法以及学习基于图的NSW、HNSW算法。
目录
一、ANNS
1、ANNS概述
ANNS(Approximate Nearest Neighbor Search)翻译为近似最近搜索。是指在大型数据集中找到给定查询点的最近邻点。ANNS 旨在最小化计算成本并同时高效找到近似最近邻。
ANNS和ANN(Artificial Neural Network)和KNN(K-Nearest Neighbors)是三种不同的概念,它们在目的、原理和应用场景上有所区别:
- ANNS(Approximate Nearest Neighbor Search):
- 目的:ANNS旨在高维空间中快速找到与查询点近似最近的邻居,牺牲一定的精确度以换取搜索速度的提升。
- 原理:通过构建特定的数据结构(如基于空间划分的KD-Tree、局部敏感哈希LSH等)或使用特定的算法逻辑来减少在高维空间中搜索最近邻所需的计算量。
- 应用场景:广泛应用于推荐系统、图像检索、模式识别等领域,特别是在处理大规模高维数据时。
- ANN(Artificial Neural Network):
- 目的:ANN是一种模仿生物神经网络行为的计算模型,用于识别数据中的复杂模式和关系,进行分类、回归等任务。
- 原理:由多层神经元组成,通过前向传播和反向传播算法,调整神经元之间的连接权重,以学习输入与输出之间的映射关系。
- 应用场景:广泛应用于图像识别、语音识别、自然语言处理等领域。
- KNN(K-Nearest Neighbors):
- 目的:KNN是一种基于实例的学习方法,用于分类或回归任务,通过查找最近的K个邻居来预测新样本的类别或值。
- 原理:不需要显式的训练过程,而是直接根据距离度量(如欧氏距离)在训练数据集中找到与新样本最近的K个样本,然后根据这些邻居的信息进行预测。
- 应用场景:适用于小到中等规模的数据集,常用于分类问题、推荐系统等。
总结:
- ANNS关注于高维空间中的近似最近邻搜索,主要解决搜索效率问题。
- ANN是一种模拟人脑神经网络的计算模型,用于学习数据的复杂模式。
- KNN是一种简单直接的基于距离的分类或回归方法,侧重于通过最近的邻居进行预测。
2、常见的ANNS算法以及原理简单概述
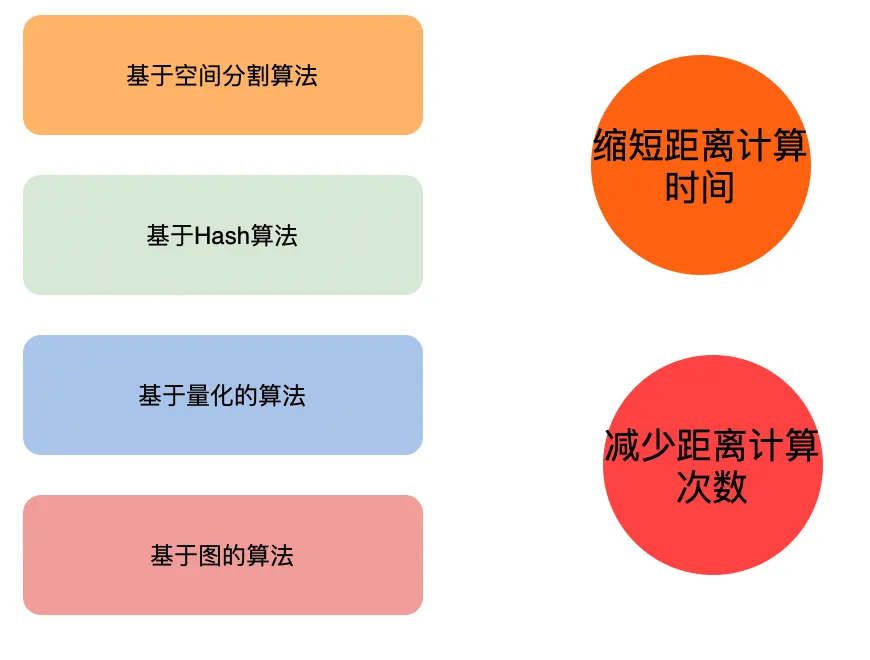
大概可以分为四大类
- 基于空间分割算法:思想参考BSP,常见的结构比如KD-Tree以及BKD、BBF等优化结构算法,主要思路就是构建多维数据索引树,BKD则是基于KD-Tree、B-Tree考虑到磁盘存储利用率、更新破坏结构而提出的一种动态磁盘树结构,BBF则是利用优先队列减少KD-Tree回溯判断次数,提升检索效率。还有其他的一些结构如R-Tree、四叉树等实现KNN,都是基于这个思路。
- 基于哈希的算法:Locality-Sensitive Hashing 高维空间的两点若距离很近,他们哈希值有很大概率是一样的;若两点之间的距离较远,他们哈希值相同的概率会很小 。一般是根据具体的场景需求选取哈希函数,这种算法因为损失了大量数据,精度可能不是那么好,但是效率比较高。
- 基于量化的算法:基本思路就是向量维度分治,牺牲部分精度,提高效率。把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(quantization),这样每个向量就能由多个低维空间的量化code组合表示 。比如PQ(Product Quantization,乘积量化)是一种常用的近似最近邻搜索算法。还有一些优化算法如IVFPQ,基于倒排的乘积量化算法,增加粗量化阶段,对样本进行聚类,划分为较小的region ,减少候选集数据量(之前是需要遍历全量的样本,时间复杂度为O(N*M))。
- 基于图的算法:基本思路就是基于图的紧邻查找,比如NSW、HNSW算法
还有一些商业开源ANNS比如Spotify 的 ANNOY、Google 的 ScaNN、Facebook的Faiss等,性能基准参考ann-benchmarks:https://github.com/erikbern/ann-benchmarks#evaluated ,使用的算法不同,应对的业务检索场景不同,测试数据集不同,算法的表现性能就可能不同,因此性能好只是相对的。
摘自论文-基于图的近似最近邻搜索的综合综述和实验比较
观察各种数据集上的评估结果(详细信息参见§5),我们发现许多算法在不同数据集上的性能存在显着差异。也就是说,算法在某些数据集上的优势可能很难扩展到其他数据集上。例如,当搜索精度达到 0.99 时,对于 Msong [2] 上的每个查询,NSG 的加速比 HNSW 高 125 倍。然而,在 Crawl [3] 上,当 NSG 达到相同的搜索精度 0.99 时,其加速比 HNSW 低 80 倍。这表明算法的优越性取决于数据集,而不是固定于其性能。通过评估和分析不同场景的数据集,可以更好地理解基于图的ANNS算法在不同场景下的性能差异,为不同领域的从业者选择最合适的算法提供依据。
1、ANNOY (Approximate Nearest Neighbors Oh Yeah) 特点: ANNOY使用了基于树的算法来构建索引,通过构建多棵树并在这些树上进行搜索来实现快速的近似最近邻查找。ANNOY特别适用于在内存中进行大规模搜索,因为它的数据结构可以高效地加载和查询。应用场景: 音乐推荐、图像搜索等。这个有点类似BKD,创建多颗二叉树以及使用优先队列,但是还是不太一样。它的原理基于两个关键思想:随机投影和候选筛选。
- 首先,ANNOY使用随机投影来降低向量的维度。它将高维向量映射到低维空间,以减少计算和存储的开销。随机投影是一种快速的降维方法,它通过随机选择一组投影向量来将原始向量映射到低维空间。通过降低维度,ANNOY能够在保持搜索质量的同时,显著减少计算和存储的成本。
- 其次,ANNOY使用候选筛选来加速搜索过程。在搜索时,ANNOY首先使用随机投影将查询向量映射到低维空间。然后,它使用一种快速的候选筛选方法,如局部敏感哈希(Locality Sensitive Hashing)或随机k-d树(Random k-d Tree),来找到一组候选近邻。最后,ANNOY对候选集进行精确的距离计算,以找到最近的邻居。
2、ScaNN (Scalable Nearest Neighbors) 开发者: Google 特点: ScaNN是一种用于向量相似性搜索的库,它通过优化量化和树搜索的结合来提高搜索效率和准确性。ScaNN旨在提供高效的搜索能力,特别是在处理超大规模数据集时。应用场景: 大规模图像检索、文本相似性搜索等。ScaNN(Scalable Nearest Neighbors)是一种用于高效近邻搜索的算法。它的原理基于两个关键思想:分层索引和候选筛选。
- 首先,ScaNN使用分层索引来组织数据。它将数据集划分为多个层级,每个层级都有一个索引结构。这些索引结构可以是传统的索引方法,如KD-Tree或LSH(Locality Sensitive Hashing),也可以是近似索引方法,如HNSW(Hierarchical Navigable Small World)。通过使用分层索引,ScaNN可以将搜索空间分解为多个子空间,从而减少搜索的复杂度。
- 其次,ScaNN使用候选筛选来加速搜索过程。在搜索时,ScaNN首先使用索引结构找到一组候选近邻。然后,它使用一种快速的候选筛选方法,如乘积量化(Product Quantization)或局部敏感哈希(Locality Sensitive Hashing),来进一步缩小候选集。最后,ScaNN对缩小后的候选集进行精确的距离计算,以找到最近的邻居。
3、Faiss (Facebook AI Similarity Search) 开发者: Facebook 特点: Faiss是一个高效的相似性搜索库,专注于密集向量的快速检索和聚类。Faiss使用了先进的向量量化技术,能够支持在大规模数据集上进行高效的相似性搜索。 应用场景: 图像检索、聚类分析、大规模机器学习等。Faiss的原理基于两个关键思想:索引结构和量化编码。
- 首先,Faiss使用索引结构来组织向量数据。它支持多种索引结构,包括平面索引(Flat Index)、倒排索引(IVF Index)、乘积量化索引(PQ Index)等。这些索引结构可以根据数据集的特点和需求进行选择。例如,倒排索引适用于高维数据集,乘积量化索引适用于低维数据集。通过使用索引结构,Faiss能够将搜索空间划分为多个子空间,从而加速相似度搜索。
- 其次,Faiss使用量化编码来减少向量的维度。它将高维向量映射到低维空间,以降低计算和存储的成本。Faiss支持多种量化编码方法,如乘积量化(Product Quantization)、向量量化(Vector Quantization)等。这些方法可以将向量划分为多个子向量,并对每个子向量进行编码。通过使用量化编码,Faiss能够在保持搜索质量的同时,显著减少计算和存储的开销。
4、HNSW (Hierarchical Navigable Small World) 特点: HNSW是一种基于图的近似最近邻搜索算法,通过构建一个分层的图结构来实现高效的搜索。HNSW能够在大规模数据集上实现快速且准确的近似最近邻搜索,具有较低的内存消耗和较快的查询速度。应用场景: 推荐系统、图像检索、文本搜索等。
5、QSG-NGT:该算法在当前业界最权威的ANN-Benchmarks中荣获第一。NGT是一种结合了图和树结构的算法,用于高效地进行最近邻搜索。它主要由两个组成部分构成:Neighborhood Graph(邻域图)和Tree(树结构,如VP-Tree、KD-Tree等)。NGT的核心思想是利用邻域图进行精确或近似的最近邻搜索,同时使用树结构加速搜索过程。
2.1、乘积量化PQ概述
乘积量化(Product Quantization)简称 PQ。是和VLAD算法由法国INRIA实验室一同提出来的,为的是加快图像的检索速度,所以它是一种检索算法。现有的检索算法存在一些弊端,如 kd树不适合维度高的数据,哈希(LSH)适用中小数据集,而乘积量化这类方法,内存占用更小、数据动态增删更方便。基本思路就是聚类、量化压缩向量维度,提升检索速率。
k-means聚类
先看k-means聚类,k-means聚类算法是一种常用的无监督学习算法,用于将数据集划分为k个不重叠的簇。其基本思想是通过迭代优化的方式,将数据点分配到最近的聚类中心,并更新聚类中心的位置,直到满足停止准则。k-means聚类算法的步骤如下:
- 初始化:选择要聚类的数据集和要划分的簇的数量k。随机选择k个数据点作为初始的聚类中心。
- 分配数据点:对于每个数据点,计算其与每个聚类中心的距离,并将其分配给距离最近的聚类中心。
- 更新聚类中心:对于每个聚类,计算其所有分配给它的数据点的平均值,并将该平均值作为新的聚类中心。这种的叫做平均聚类,平均值就代表当前聚类簇ID
- 重复步骤2和步骤3,直到聚类中心不再发生变化或达到预定的迭代次数。
- 输出结果:最终的聚类中心即为聚类结果,每个数据点被分配到一个簇中。
需要注意的是,k-means算法对初始聚类中心的选择敏感,可能会得到不同的结果。因此,可以多次运行算法,选择最优的结果。另外,k-means算法对于非凸形状的数据集效果可能不佳,此时可以考虑使用其他聚类算法。
ps:凸形数据集:如果一个数据集D是凸的,简单来说,数据集D中任意两点的连线上的点,也会在数据集D内,那么数据集D就是一个凸集。
简单的k-means代码demo
package org.example.kmeans;import java.util.ArrayList;
import java.util.List;/*** @author sichaolong* @createdate 2024/3/29 10:20*/public class SimpleKMeansDemo {private int k; // 聚类的个数private List<Point> points; // 数据集private List<Cluster> clusters; // 聚类结果public SimpleKMeansDemo(int k, List<Point> points) {this.k = k;this.points = points;this.clusters = new ArrayList<>();}public void run() {// 初始化聚类中心, 随机选取k个数据点作为初始聚类中心for (int i = 0; i < k; i++) {Cluster cluster = new Cluster();cluster.setCentroid(points.get(i));clusters.add(cluster);}// 循环直到收敛boolean converged = false;while (!converged) {// 清空聚类结果for (Cluster cluster : clusters) {cluster.clearPoints();}// 将每个数据点分配到最近的聚类中心for (Point point : points) {Cluster nearestCluster = null;double minDistance = Double.MAX_VALUE;// 遍历每个聚类中心,找到最近的for (Cluster cluster : clusters) {double distance = point.distanceTo(cluster.getCentroid());if (distance < minDistance) {minDistance = distance;nearestCluster = cluster;}}nearestCluster.addPoint(point);}// 更新聚类中心converged = true;// 遍历每个聚类中心,如果聚类中心没有发生变化,则收敛for (Cluster cluster : clusters) {Point oldCentroid = cluster.getCentroid();Point newCentroid = cluster.calculateCentroid();if (!oldCentroid.equals(newCentroid)) {cluster.setCentroid(newCentroid);converged = false;}}}}public List<Cluster> getClusters() {return clusters;}public static void main(String[] args) {// 创建数据集List<Point> points = new ArrayList<>();points.add(new Point(1, 1));points.add(new Point(1, 2));points.add(new Point(2, 2));points.add(new Point(5, 5));points.add(new Point(6, 6));points.add(new Point(7, 7));// 创建K-means对象并运行算法SimpleKMeansDemo kMeans = new SimpleKMeansDemo(2, points);kMeans.run();// 输出聚类结果List<Cluster> clusters = kMeans.getClusters();for (int i = 0; i < clusters.size(); i++) {System.out.println("Cluster " + (i + 1) + ":");for (Point point : clusters.get(i).getPoints()) {System.out.println("(" + point.getX() + ", " + point.getY() + ")");}System.out.println();}}
}class Point {private double x;private double y;public Point(double x, double y) {this.x = x;this.y = y;}public double getX() {return x;}public double getY() {return y;}/*** 计算两个点之间的距离,使用欧几里徳距离* @param other* @return*/public double distanceTo(Point other) {double dx = x - other.x;double dy = y - other.y;return Math.sqrt(dx * dx + dy * dy);}@Overridepublic boolean equals(Object obj) {if (this == obj) {return true;}if (obj == null || getClass() != obj.getClass()) {return false;}Point other = (Point) obj;return Double.compare(other.x, x) == 0 && Double.compare(other.y, y) == 0;}@Overridepublic int hashCode() {return Double.hashCode(x) + Double.hashCode(y);}
}class Cluster {private Point centroid;private List<Point> points;public Cluster() {this.points = new ArrayList<>();}public Point getCentroid() {return centroid;}public void setCentroid(Point centroid) {this.centroid = centroid;}public List<Point> getPoints() {return points;}public void addPoint(Point point) {points.add(point);}public void clearPoints() {points.clear();}/*** 计算聚类中心点* @return*/public Point calculateCentroid() {double sumX = 0;double sumY = 0;for (Point point : points) {sumX += point.getX();sumY += point.getY();}double avgX = sumX / points.size();double avgY = sumY / points.size();return new Point(avgX, avgY);}
}PQ量化以及搜索
对一个向量数据库进行PQ量化主要分为聚类、量化两个部分,简单理解就是横向拆分,然后k-means聚类,分别计算每个字向量距离最近的簇ID作为本子向量的代表,库中的向量(包含若干子向量)会得到一个量化矩阵,后续搜索按照上述步骤直接从量化矩阵匹配就能找出相似向量。
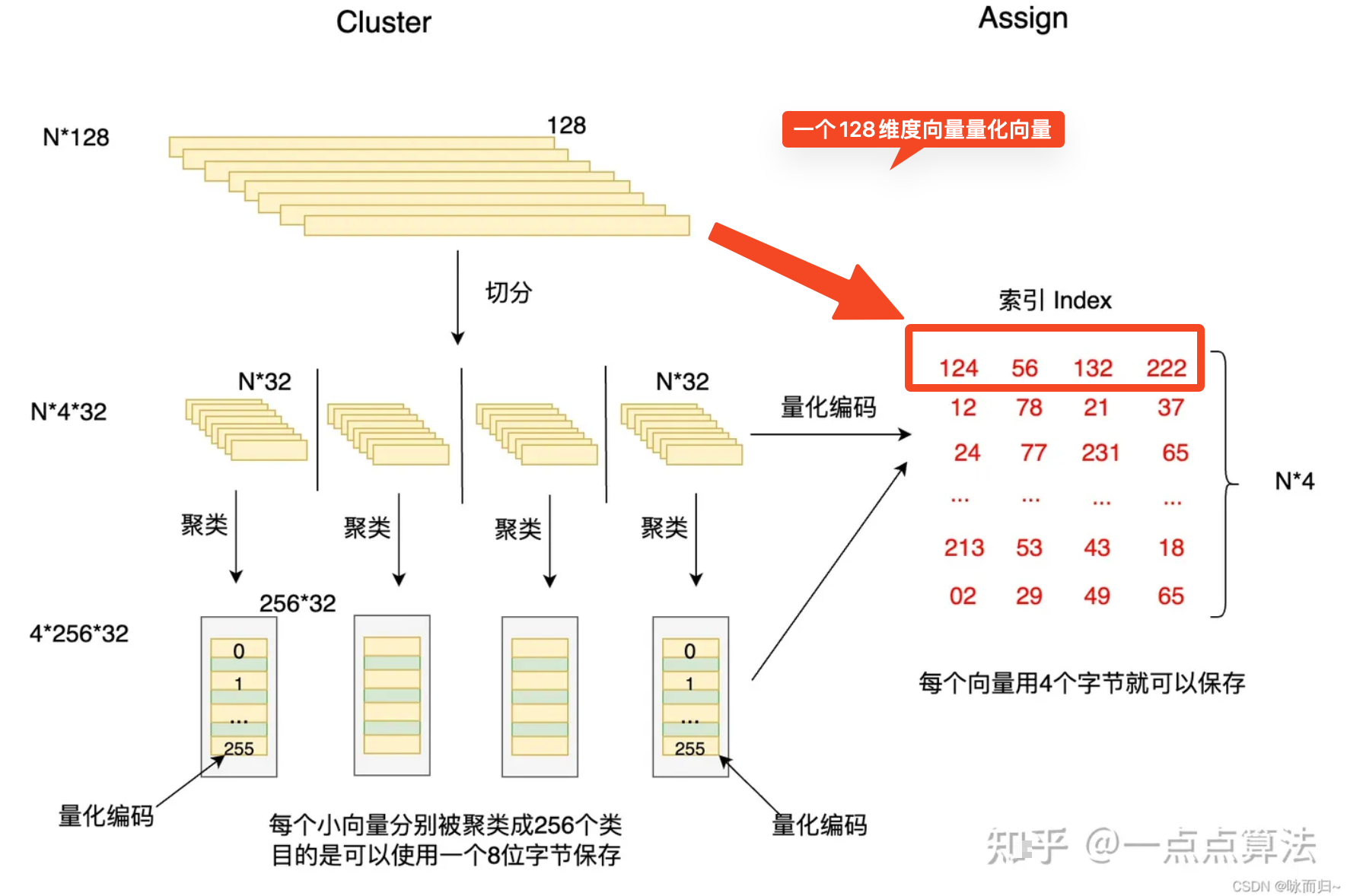
- 乘积量化有个重要的参数m_split ,这个参数控制着向量被切分的段数,如图所示,假设每个向量的维度为128,每个向量被切分为4段,这样就得到了4个小的向量,对大量每段小向量分别进行聚类,聚类个数为256个,这就完成了Cluster。
- 然后做Assign操作,先每个聚类进行编码,然后分别对每个向量来说,先切分成四段小的向量,对每一段小向量,分别计算其对应的最近的簇心,然后使用这个簇心的ID当做该向量的第一个量化编码,依次类推,每个向量都可以由4个ID进行编码。每个ID可以由一个字节保存,每个向量只需要用4个字节就可以编码,这样就完成的向量的压缩,节省了大量的内存,压缩比率2000+。这一步其实就是Faiss训练的部分,目的是为了获取索引Index。
如何得到量化矩阵:假设向量库存在N个大向量,一个大向量是128维,切分4 * 32 个子向量,通过k-means形成了256个聚类,
(1)得到子向量量化编码:那么每个子向量会找出最近的 1/256 个簇ID,这个簇ID假如是a就作为每个字向量的量化编码。一个大向量切分了4个子向量,所以大向量量化向量为(a1,a2,a3,a4).
(2)如果是N个大向量,那就是N * (a1,a2,a3,a4),此就是向量库N个大向量的量化矩阵。
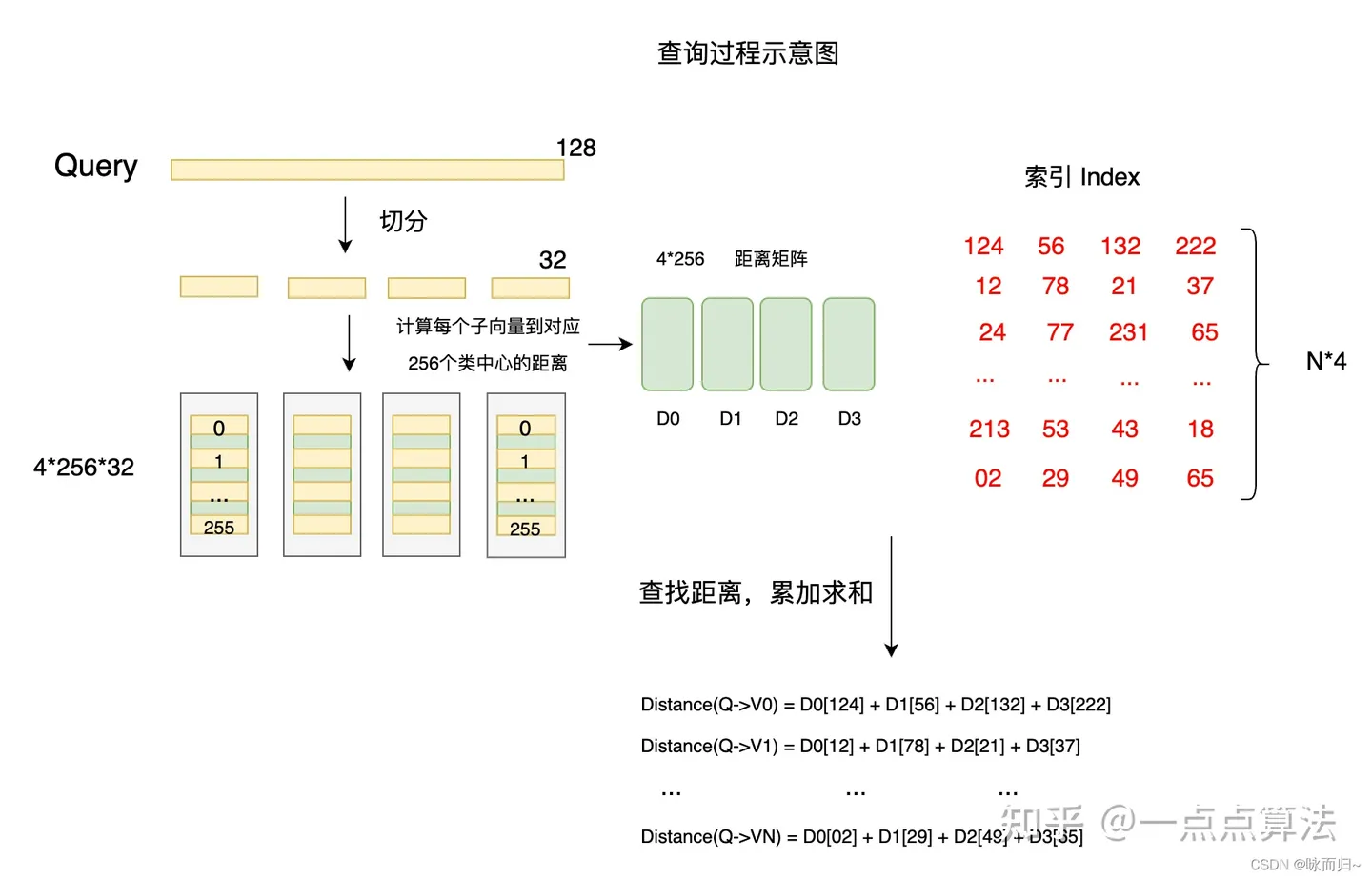
搜索过程:大的向量是128维,被切分为4 * 32维的小向量,每个小向量从256个簇ID找到一个距离最近(根据k-means选取的距离公式计算32维向量的最相似向量)的值,然后组成(a,b,c,d)去距离量化矩阵匹配,匹配上去了,那么就找到了簇ID邻近的向量数据(至于如何找,有很多方法,比如_IVFPQ_就是为了加快检索速率创建簇中心ID ——> 本簇中心的向量的倒排索引),接着找这个簇ID上面的全部相似子向量,组合大向量 or 最近距离返回。
二、基于图的ANNS算法
摘自论文-基于图的近似最近邻搜索的综合综述和实验比较
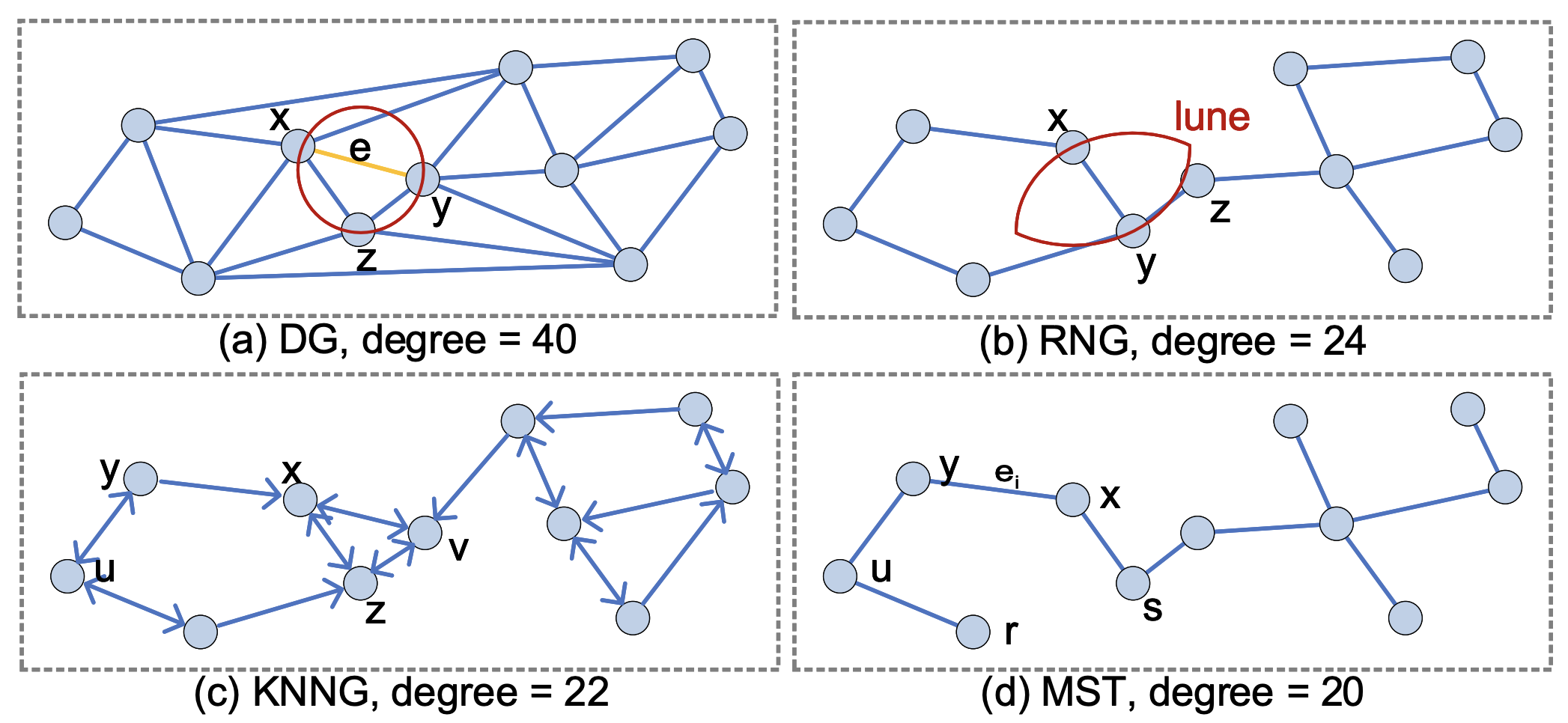
现有的基于图的ANNS算法的索引一般是四种经典基图从不同角度的衍生,即Delaunay图(DG)[35]、相对邻域图(RNG)[92]、K-近邻图(KNNG) [75]和最小生成树(MST)[58]。一些代表性的 ANNS 算法,例如 KGraph [31]、HNSW [67]、DPG [61]、SPTAG [27],可以分为基于 KNNG(KGraph 和 SPTAG)和基于 RNG(DPG 和 HNSW)的组
基于图的ANNS算法可以分为,针对基础图当前很多算法,当前也有很多优化算法,比如HNSW,DPG,NGT,NSG,SPTAG。
- 德劳内图(DG)
- 相对领域图(RNG)
- K近邻图(KNNG)
- 最小生成树(MST)
2.1、NSW算法
NSW(Navigable Small World )翻译为可导航小世界,是一种基于图的紧邻搜索算法。
// TODO
2.2、HNSW算法
Hierarchical Navigable Small Worlds (HNSW)可以被翻译为 分层可导航小世界,是16年提出来的一种图结构紧邻搜索算法。
摘要论文 — 我们提出了一种基于具有可控层次结构的可导航小世界图(新南威尔士州分层,HNSW)的近似K最近邻搜索的新方法。所提出的解决方案 是完全基于图的,不需要任何额外的搜索结构,这些结构通常用于最接近图技术的粗略搜索阶段。分层新南威尔士州以增量方式构建多层结构,该结 构由存储元素的嵌套子集的分层邻近图(层)集组成。存在元素的最大层是随机选择的,概率分布呈指数衰减。这允许生成类似于先前研究的可导航 小世界 (NSW) 结构的图形,同时还具有由其特征距离尺度分隔的链接。与新南威尔士州相比,从上层开始搜索并利用刻度分离可以提高性能,并 允许对数复杂性缩放。额外使用启发式方法来选择邻近图邻居,可显著提高高召回率和高度聚类数据下的性能。性能评估表明,所提出的通用度量空 间搜索索引能够大大优于以前的开源最先进的纯向量方法。该算法与跳过列表结构的相似性允许直接平衡的分布式实现。
参考
- HNSW论文:Understanding Hierarchical Navigable Small Worlds (HNSW)、https://arxiv.org/abs/1603.09320
- NSW论文:https://publications.hse.ru/mirror/pubs/share/folder/x5p6h7thif/direct/128296059
- 顶会论文:基于图的近似最近邻搜索的综合综述和实验比较
- Search Engine For AI:高维数据检索工业级解决方案,阿里巴巴浙大博士论文,知乎
- 大白话理解HNSW - 掘金
- 高维数据检索:基于近邻图的近似最近邻搜索算法实验综述
这篇关于ElasticSearch学习篇11_ANNS之基于图的NSW、HNSW算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









