本文主要是介绍回环检测-,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
回环检测
前言
回环检测作为VSLAM中相对独立又重要的一个模块,在消除累积误差,重定位等方面有着重要作用,更有甚者,把系统是否有重定位模块,来作为判断一个系统是SLAM还是里程计的依据。
回环检测是什么?
回环检测顾名思义,就是检测当前是否有回环。如下面所示,在场景A中,我们从1点出发,沿着某条路线走,如果没有碰到之前的场景,我们的路线一直处于开环状态。当到达地点3时,属于之前走过的地方,路线闭合,形成闭环,这个闭合过程称为发生了回环。如果我们继续沿着之前的路线走(下图中白色虚线框内路径),则会不断发生新的回环,继续产生多个回环点。

为什么会有回环检测呢,或者说回环检测的作用是什么。这一切都和里程计的累计误差有关系。在上述场景,我们理想中的轨迹是这样的:
由于里程计的累计误差,走的越远越不准,最后实际估计的路线可能是下图这样,可以看到,从左侧开始,轨迹就逐渐开始偏掉了:
导致最后我们回到交叉路口时,人是回来了,估计的轨迹没有回来(下图左),整个轨迹与实际相比,出现了很大的偏差。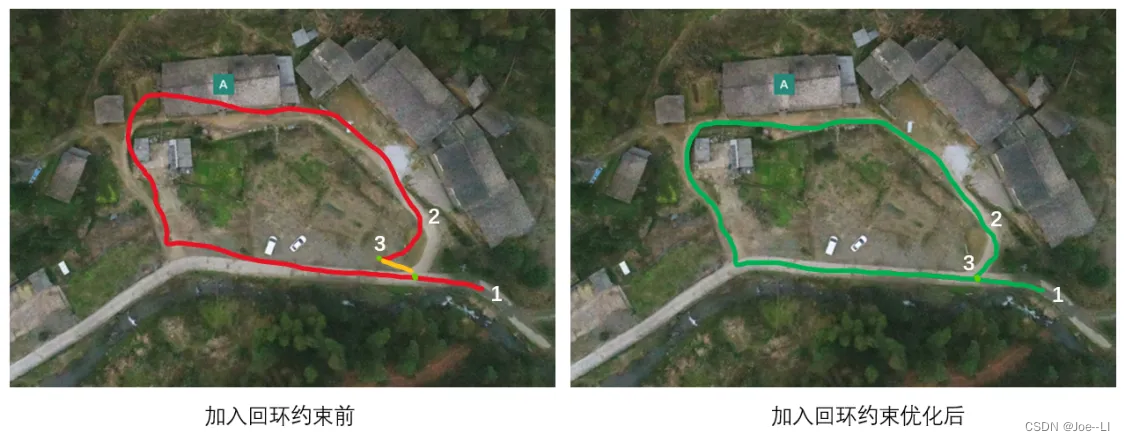
如果能通过算法检测到当前发生了回环,即上图中的两个绿点,其实是同一个地方,就可以通过匹配算法计算两个绿点之间的相对位置关系(黄线),通过这个相对位置关系,可以得到3点真实的位姿。把这个相对约束加到优化中,就可以把轨迹拉到正确的位置上,得到一个全局一致的姿态估计。
所以我们说,回环检测是消除里程计累计误差的好帮手。想在长时间,大范围的姿态估计中获得好的结果,回环检测是不可或缺的。更极端一点的是,我们会把只有前端和局部优化的算法叫做里程计,而有回环检测和全局优化的算法,称为SLAM算法。
另外也可以发现,回环检测算法也可以用在重定位之中。检测到回环后,可以通过匹配算法计算回环位置与当前位置之间的相对位置关系,然后得到当前的真实位姿。因此在定位阶段,回环检测的原理也能发挥重要的作用,回环检测算法真是一个应用很广泛的算法。
回环检测的方法
现在回过头来,如何做回环检测呢?对于视觉SLAM,最简单的方法是对任意两幅图像都做一遍特征匹配,根据正确匹配的数量确定哪两幅图像存在关联。这种方法朴素但是有效,缺点是任意两幅图像做特征匹配,计算量实在太大,因此不实用。退而求其次的话,随机抽取历史数据进行回环检测,比如在帧中随机抽5帧与当前帧比较。时间效率提高很多,但是抽到回环几率不高,也就是检测效率不高。
另外也有如下的一些可能方式:
基于里程计几何关系的方法:
1.大概思路是当我们发现当前相机运动到之前的某个位置附近时,检测他们是否存在回环
缺点:由于累积误差,很难确定运动到了之前某个位置
基于外观的方法
1.仅仅依靠两幅图像的相似性确定回环
其核心问题是如何计算图像的相似性。
目前视觉SLAM中主要是基于外观的方法,细分下的话,分为传统的方法与基于深度学习的方法,传统的方法有词袋模型与随机蕨法,基于深度学习的方法有CALC算法。
词袋模型(Bag of words)
Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
举例说明
文档一:Bob likes to play basketball, Jim likes too.
文档二:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”,8. “games”, 9. “Jim”, 10. “too”}。
基于上述的词典可以构造出一个两个直方图向量
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
这两个向量共包含10个元素, 其中第i个元素表示字典中第i个单词在句子中出现的次数. 因此BoW模型可认为是一种统计直方图 (histogram)
在视觉SLAM当中,每个词换为了特征点的描述子,而一幅图像可以理解为由许多描述子形成的文本,然后使用词袋向量来表示这幅图像。在检测是否发生回环时,通过计算每个关键帧与当前关键帧词袋向量的相似度来看是否发生回环。
DBoW系类库是开源的词袋模型库,许多有代表性的VSLAM算法都使用了DBoW做为回环检测算法,如ORB-SLAM系列,VINS-Mono,RTAB-Map。另外,对于激光SLAM,目前也有使用LinK3D描述子的BoW3D词袋库。
随机蕨法(Random ferns)
随机蕨算法是一种图像压缩编码的算法,它首先通过随机算法,对整幅图像随机生成N个采样点,然后对每个采样点,再随机生成一个阈值。然后对每个通道,对比阈值与对应灰度值的大小,生成1或者0的编码,这样每个位置,会生成一个四维的向量。整个图像,会生成一个4N维的向量作为编码,一个随机蕨的生成过程如下:
将F=|fi|,i∈{R,G,B,D}定义为一个随机蕨
f i = { 1 , I i ( x ) ⩾ τ i 0 , I i ( x ) < τ i f_{i}=\left\{\begin{array}{l} 1, I_{i}(x) \geqslant \tau_{i} \\ 0, I_{i}(x)<\tau_{i} \end{array}\right. fi={1,Ii(x)⩾τi0,Ii(x)<τi
式中Ti,的值通过随机函数产生(TR,TG,TB∈[0,255],TD∈[800,4000])。将随机蕨F中所有的fi按顺序排列,
得到一个二进制编码块 b f b_f bf
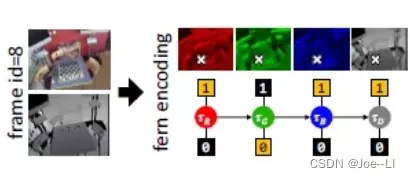
在计算相似度时,使用基于块的汉明距离(block-wise hamming distance: BlockHD),即只要一个块里有一位不一样,则整个块的距离为1,反之都一样则为0。两幅图像的 BlockHD越小,说明两者越相似,如果 BlockHD值越大,说明差异性越大。使用随机蕨算法来进行相似度计算的有一些RGBD-SLAM算法,如kinect fusion,elastic fusion等;
基于深度学习的方法: CALC
CALC是用于回环检测的卷积自动编码器。它该代码分为两个模块。TrainAndTest用于训练和测试模型,DeepLCD是一个用于在线回环检测或图像检索的C ++库。
在大型实时SLAM中采用无监督深度神经网络的方法检测回环可以提升检测效果。该方法创建了一个自动编码结构,可以有效的解决边界定位错误。对于一个位置进行拍摄,在不同时间时,由于视角变化、光照、气候、动态目标变化等因素,会导致定位不准。卷积神经网络可以有效地进行基于视觉的分类任务。在场景识别中,将CNN嵌入到系统可以有效的识别出相似图片。但是传统的基于CNN的方法有时会产生低特征提取,查询过慢,需要训练的数据过大等缺点。而CALC是一种轻量级地实时快速深度学习架构,它只需要很少的参数,可以用于SLAM回环检测或任何其他场所识别任务,即使对于资源有限地系统也可以很好地运行。
这个模型将高维的原始数据映射到有旋转不变性的低维的描述子空间。在训练之前,图片序列中的每一个图片进行随机投影变换,重新缩放成120×160产生图像对,为了捕捉运动过程中的视角的极端变化。然后随机选择一些图片计算HOG算子,采用固定长度的HOG描述子可以帮助网络更好地学习场景的几何。将训练图片的每一个块的HOG存储到堆栈里,定义为X2,其维度为NxD,其中N是块的大小,D是每一个HOG算子的维度。网络有两个带池化层的卷积层,一个纯卷积层,和三个全连接层,同时用ReLU做卷积层的激活单元。在该体系结构中,将图片进行投影变换,提取HOG描述子的操作仅针对整个训练数据集计算一次,然后将结果写入数据库以用于训练。在训练时,批量大小N设置为1,并且仅使用boxed区域中的层。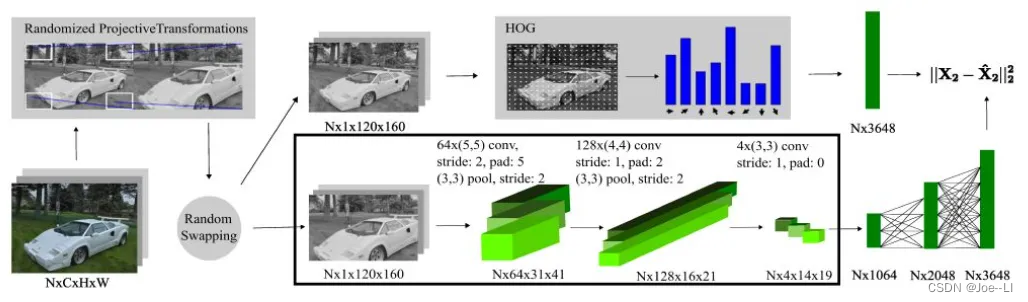
基于缩略图
PTAM的回环检测方法和random ferns很像。PTAM是在构建关键帧时将每一帧图像缩小并高斯模糊生成一个缩略图,作为整张图像的描述子。在进行图像检索时,通过这个缩略图来计算当前帧和关键帧的相似度。这种方法的主要缺点是当视角发生变化时,结果会发生较大的偏差,鲁棒性不如基于不变量特征的方法。
词袋模型
我们一般只关心袋子里物品的种类和数量,对它们的顺序并不关心。现在我们想问,这袋子容量是多少,能装的物品种类是多少,词袋和回环检测有什么关系?别着急,咱们一个个回答。
首先是词袋和回环检测的关系:词袋模型用于回环检测的基本假设是,如果两幅图像中出现的特征种类和数量差不多,那么两幅图像大概率是同一个地方拍摄的。这就是基于外观的回环检测原理。
想象你去商业街购物,在同一家商店里购买东西,出门时袋子里的东西基本是十分相似的,如果去另外一家商店购买,则出门时购物袋里的东西就大概率不一样,当然,也要小心类似于麦当劳和肯德基这种卖同种商品的店铺。因此,我们可以说,词袋相似是回环的必要但不充分条件。
袋子的容量:取决于每幅图像提取的特征点数量。而如果袋子能装的东西越多,那包含不同内容的袋子的数量就越多。
而袋子能装的物品的种类:取决于我们词库里单词的数量。单词数量越多,每个袋子的差异性就可以越大,不同场景的区分性越好。比如上文的麦当劳和肯德基,如果我们把物品只区分到汉堡这个层面,那我们就无法区分这个袋子是麦当劳的购物袋还是肯德基的购物袋,但如果我们对汉堡进一步分类,香辣鸡腿堡是肯德基的,麦辣鸡腿堡是麦当劳的,炫辣鸡腿堡是汉堡王的,那么我们就可以区分这个购物袋的来源了。
如何表征每个袋子呢,用它里面装的东西就可以了。上图右边两个袋子可以表示为:
美食街的袋子= 2青苹果+1螃蟹+1汉堡套餐
动物园的袋子= 1大象+1蝴蝶+2猫+1腕龙
一看到这两个表示,我们基本可以断定,这肯定不是一个类型的东西,如果看到一个:
神秘的袋子 = 1大象+1蝴蝶+2猫+1腕龙 + 1熊猫
我们有很大把握说,这个袋子和动物园的袋子来着同一个商店。
那么接下来的问题就是:
1.构建袋子中的这些类别
2.用这些类别物品,表征这个袋子
3.计算两个袋子的相似度
在接下来的几个小节中我们来对每个问题逐一进行讲解。
词的生成
就像生活中常见的做法一样,按照某些特征的不同,我们会把生活中不同物品不断细分为不同类别。
然后按照这个分类模型,就可以对未知物品,进行分类了。
词的构建也是如此,我们先采集大量的图片,然后从中提取出大量描述子,然后对这些描述子,使用聚类的方法,构建出一个一个类出来,每个类,就是一个单词。聚类问题在无监督机器学习(Unsupervised ML)中特别常见,用于让机器自行寻找数据中的规律。BoW的字典生成问题也属于其中之一。首先,假设我们对大量的图像提取了特征点,例如有N个。现在,我们想找一个有k个单词的字典,每个单词可以看作局部相邻特征点的集合,这可以用经典的K-means(K均值)算法解决。
K-means是一个非常简单有效的方法,因此在无监督学习中广为使用,下面对其原理稍做介绍。简单的说,当有N个数据,想要归成k个类,那么用K-means来做主要包括如下步骤:
1.随机选取k个中心点:c1,… ,ck。
2.对每一个样本,计算它与每个中心点之间的距离,取最小的作为它的归类。
3.重新计算每个类的中心点。
4.如果每个中心点都变化很小,则算法收敛,退出:否则返回第2步。
但实际训练单词时,我们使用的是和动物学分类中类似的树状形式,进一步说,是K叉树形式。
1.在根节点,用K-means把所有样本聚成k类(实际中为保证聚类均匀性会使用K-means++)。这样就得到了第一层。
2.对第一层的每个节点,把属于该节点的样本再聚成k类,得到下一层。
3.依此类推,最后得到叶子层。叶子层即为所谓的wods。
4.计算每个单词的DF权重:idf(i)=logN/n
实际上,最终我们仍在叶子层构建了单词,而树结构中的中间节点仅供快速查找时使用。这样一个k分支、深度为d的树,可以容纳kd个单词。另外,在查找某个给定特征对应的单词时,只需将它与每个中间节点的聚类中心比较(一共d次),即可找到最后的单词,保证了对数级别的查找效率。而为每一个单词计算一个IDF权重,主要用来给每个词增加区分度,在数据集中出现得越少的单词,其可辨认度就越高。
我们把生成的这个词汇树,称为字典。训练词汇树的过程就是构建词典的过程
使用字典表征图像
有了字典之后,给定任意特征,只要在字典树中逐层查找,最后都能找到与之对应的单词wj:当字典足够大时。我们可以认为fi和wj来自同一类物体。那么,假设从一幅图像中提取了N个特征,找到这N个特征对应的单词之后,就相当于拥有了该图像在单词列表中的分布,或者直方图。
另外我们还需要知道每个词的权重。TF-IDF(Term Frequency-Inverse Document Frequency),或译频率-逆文档频率,是文本检索中常用的一种加权方式,也用于BoW模型中。T部分的思想是,某单词在一幅图像中经常出现,它的区分度就高。另外,IDF的思想是,某单词在字典中出现的频率越低,分类图像时区分度越高。
IDF是在构建字典时就进行的。假设所有特征数量为n,wj的数量为ni,那么该单词的IDF为:
I D F i = log n n i \mathrm{IDF}_{i}=\log \frac{n}{n_{i}} IDFi=lognin
TF部分则是在获得每幅图像时计算的。假设图像A中单词wi出现了ni次,而该幅图像中共出现的单词次数为n,那么TF为
T F i = n i n \mathrm{TF}_{i}=\frac{n_{i}}{n} TFi=nni
于是,wi的权重等于TF乘IDF之积:
η i = T F i × I D F i \eta_{i}=\mathrm{TF}_{i} \times \mathrm{IDF}_{i} ηi=TFi×IDFi
考虑权重以后,对于某幅图像A,把它的特征点匹配到对应单词之后,组成它的BoW:
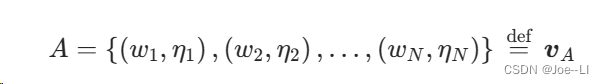
由于相似的特征可能落到同一个类中,因此实际的VA中会存在大量的零。无论如何,通过词袋我们用单个向量)VA描述了一幅图像A。这个向量vA是一个稀疏的向量,它的非零部分指示了图像A中含有哪些单词,而这些部分的值为TF-IDF的值。
回环检测流程
数据库查询
假设通过上节的算法,我们得到了当前图像的词袋(Bow)向量v,现在要在词库中检索最为相似的图像。如何实现这一步,需要先介绍一下DBoW词袋库的特点,以DBoW2词袋库为例:
DBoW2库的结构如下,即保存了图像到词汇(根节点)的正向索引,也保存了词汇到图像的逆向索引。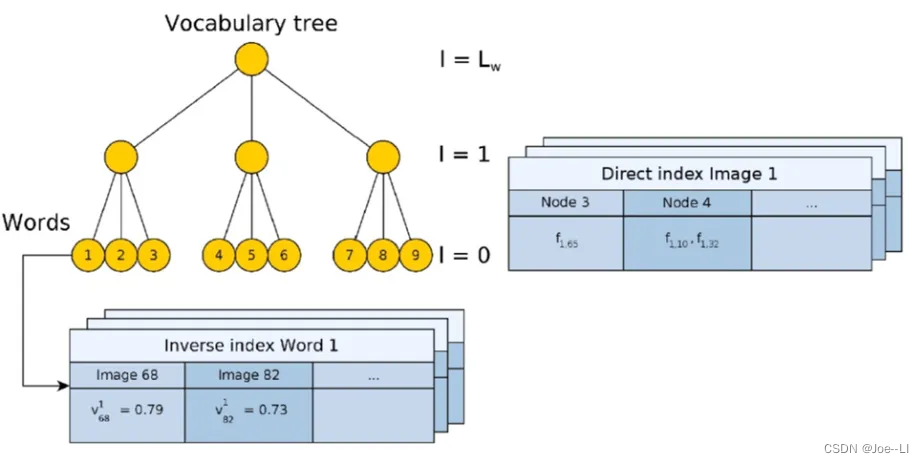
每当有新图像进来,DBoW2库就会根据描述子的情况,不断更新这个正向索引和逆索引。
在检索最相似的图像时,使用了DBoW2库的逆索引,来加速索引速度,而不是使用暴力匹配的方式: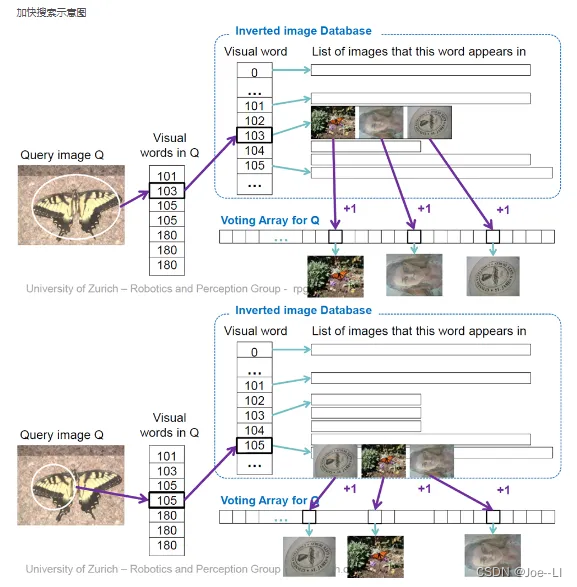
上图的含义,就是对图像Q中每个特征点,通过逆索引找到出现的图像,然后给该图像投一票,到最后哪个图像得票多,哪个就是最相似的图像。
在查询到相似图像后,其得分计算公式如下:
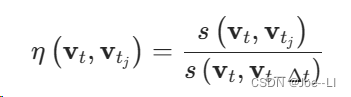
其中分母是当前关键帧上一帧,与当前的帧的相似度(最优图像得分),用以对查询结果分数做归一化。但需要注意是在转弯等部分场景,上一帧的相似度与当前帧会很小。为防止分母很小导致得分异常得大,需要对分母做判断,跳过那些得分差的帧,往前找直到得到一个分数合理的关键帧。
组匹配:
在进行回环匹配时,会将待匹配的图像按时间划分为独立的组,每一组的相似得分是组内所有图像相似得分之和。这是因为回环帧前后的帧,基本也是相似的,但我们只需要一帧,因此需要进行类似非极大值抑制。
H ( v t , V T i ) = ∑ j = n i m i η ( v t , v t j ) H\left(\mathrm{v}_{t}, V_{T_{i}}\right)=\sum_{j=n_{i}}^{m_{i}} \eta\left(\mathrm{v}_{t}, \mathrm{v}_{t_{j}}\right) H(vt,VTi)=∑j=nimiη(vt,vtj)
1、防止连续图像在数据库查询时存在的竞争关系,但是不会考虑同一地点,不同时间的关键帧。
2、防止误匹配
时间一致性判断:
在经过组匹配之后,得到了最佳组匹配,此时需要检验该组匹配的时间一致性。这时做法是,对于当前组匹配vt,与前k帧的最优组匹配,应该有较大的重叠。简单来说,就是在第一次检测到相似帧后,并不会立即认为已发生回环,而是会继续等待接下来k次匹配,在这k次最佳匹配组之间,均有较大的重叠区,这个时候,才会认为真正发生了回环。
在当前经过时间一致性校验之后的匹配组,取组内得分最高的图像,作为匹配图像,进入结构一致性校验。
结构一致性判断:
该部分通过特征点匹配,通过RANSAC计算基本矩阵,再通过基本矩阵,对两幅图像的特征点进行投影匹配。这个部分用到了各个特征点在空间中的位置是唯一不变的这一假设。
在匹配时,使用了词袋库维护的正向索引(direct image index),加速了特征点的匹配速度。搜索的时候需要注意,同时为了获取足够数量的特征点,不能直接选取words作为匹配索引。同时凸显特征之间的区分度,也不能采用采用较高层数的节点(词袋树形结构),即需要在合适的某一层进行索引匹配。
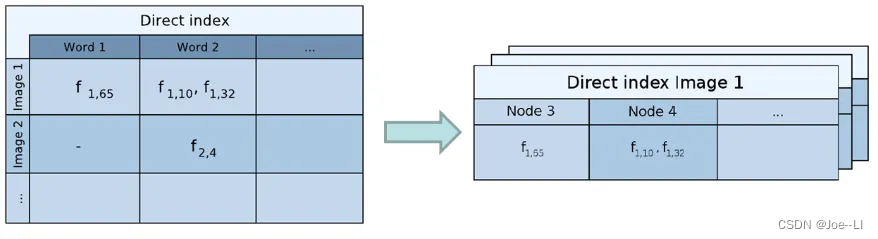
如果使用基础矩阵投影匹配的点数(内点数)大于12个,认为发生了真正的回环。
这篇关于回环检测-的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







